Table of Contents
朴素贝叶斯的分类
在sklearn中,一共有3个朴素贝叶斯的分类算法,分别是GaussianNB,MultinomialNB和BernoulliNB
GaussianNB
GaussianNB就是先验为高斯分布(正态分布)的朴素贝叶斯,假设每个标签的数据都服从简单的正态分布。
其中
为Y的第k类类别,
和
为需要从训练集估计的值
理解起来可能有点抽象,那我们从朴素贝叶斯的原理说起:
我们需要计算在给定的特征下,每种类别的概率值的大小,即等号左边的P(类别|特征),选取其中概率最大的类别,即为最终的判断结果。
为了求的等号左边的P(类别|特征),我们需要计算等号右边的分式。
对于这个分式,每个类别在计算的时候,对应的分母都是一样的,而且我们只是想要比大小,所以只需要计算出每个类别的情况下,分子的大小
P(类别)计算很简单,就是这个类别的样本数/总样本数
P(特征|类别)的计算,我们之前采用的是数数的方法,数一下,在这个类别下,这个标签所占的比例是多少。这对于离散型的变量是比较容易的数的,但是对于连续性的变量来说,就不现实了。所以,对于连续性变量,我们可以通过高斯公式计算出P(特征|类别)
以鸢尾花数据集为例,理解GaussianNB
鸢尾花数据集给出了每朵花的特征,以及花的类别,下面来导入鸢尾花数据集
import numpy as np
import pandas as pd
dataSet = pd.read_csv('iris.txt',header=None)
dataSet.columns=['feature0','feature1','feature2','feature3','label']
dataSet.head(3)
| feature0 | feature1 | feature2 | feature3 | label | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
可以看出鸢尾花数据集一共有4个特征,最后一列是标签列
dataSet.iloc[:,-1].unique()
array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)
可以看出,鸢尾花数据集的标签一共是3种,代表三种鸢尾花
那么测试集就是给出一朵花的4个特征,判断是属于哪类鸢尾花
假如我们的测试集是test = [4.2 , 4.5 , 1.2 , 0.5]
如果我们想通过GaussianNB来判断结果的话,我们需要分别计算在给定特征的情况下,是每种标签的可能性,即:
- P(‘Iris-setosa’|[4.2 , 4.5 , 1.2 , 0.5])
- P(‘Iris-versicolor’|[4.2 , 4.5 , 1.2 , 0.5] )
- P(‘Iris-virginica’|[4.2 , 4.5 , 1.2 , 0.5] )
进一步展开的话
因为我们只是需要找出这三个概率的最大值,所以这三个概率求解过程中,对应的相同的分母就不需要计算了
所以对于P(‘Iris-setosa’|[4.2 , 4.5 , 1.2 , 0.5]) ,我们只需要计算出分子的部分,即P([4.2 , 4.5 , 1.2 , 0.5]|‘Iris-setosa’)P(‘Iris-setosa’),其他同理
接下来我们以P(‘Iris-setosa’|[4.2 , 4.5 , 1.2 , 0.5]) 的分子求解为例
先计算最容易的P(‘Iris-setosa’)
sum((dataSet.iloc[:,-1]=='Iris-setosa').values)/dataSet.shape[0] #先筛选出dataSet标签为'Iris-setosa'中的类,并计数,再除以总样本数
0.3333333333333333
所以P(‘Iris-setosa’)=0.3333333333333333
接下来就剩P([4.2 , 4.5 , 1.2 , 0.5]|‘Iris-virginica’)的求解了。
在求解之前,因为朴素贝叶斯假设各特征之间都是独立的,所以
我们以等号右边的P(feature0=4.2|‘Iris-setosa’)为例,讲解求解过程,这个会了其他的就都会啦
GaussianNB假设每个特征是符合高斯分布的,所以
其中
是在’Iris-setosa’数据集中feature0数据的标准差,
则是对应的均值
我们来计算下
和
data_setosa = dataSet.loc[dataSet.iloc[:,-1]=='Iris-setosa',:] #从全部数据集中筛选出seotosa这一类的数据集
feature0=pd.DataFrame(data_setosa.iloc[:,0]).T #单独看feature0这一列的数据
feature0
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| feature0 | 5.1 | 4.9 | 4.7 | 4.6 | 5.0 | 5.4 | 4.6 | 5.0 | 4.4 | 4.9 | ... | 5.0 | 4.5 | 4.4 | 5.0 | 5.1 | 4.8 | 5.1 | 4.6 | 5.3 | 5.0 |
1 rows × 50 columns
#分别求平均
mu = float(feature0.mean(axis=1))
sigma = float(feature0.std(axis=1))
print(f'均值为{mu}')
print(f'标准差为{sigma}')
均值为5.005999999999999
标准差为0.3524896872134512
带入 得
1/(np.sqrt(2*np.pi*sigma**2))*np.e**(-(4.2-mu)**2/(2*sigma**2))
0.08287221251829666
所以P(feature0=4.2|‘Iris-setosa’)=0.082872,剩下的3个概率也是一样的计算方法:
- 先筛选数据
- 分别计算均值和标准差
- 带入高斯公式,得到结果
我们也可以通过图像,来验证下高斯分布的假设对于我们的数据集是否合适
import matplotlib.pyplot as plt
plt.hist(feature0,bins=15,density=True,stacked=True)
x = np.arange(4,6,0.03)
y = np.exp(-(x-mu)**2/(2*sigma**2))*(1/np.sqrt(2*np.pi*sigma**2))
plt.plot(x,y)
[<matplotlib.lines.Line2D at 0x11a6364a8>]
数据是符合高斯分布的假设基本上是成立的
实例:使用GaussianNB对鸢尾花数据集进行分类
接下来我们就直接敲python代码,完成整个实例
#导入数据集
import numpy as np
import pandas as pd
dataSet = pd.read_csv('iris.txt',header=None)
dataSet.head()
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
#随机切分数据集
'''
函数名称:randSplit
函数功能:随机切分训练集和测试集
参数说明:
dataSet-输入的数据集
train_rate-训练集所占的比例
返回:
train-切分好的训练集
test-切分好的测试集
'''
def randSplit(dataSet,train_rate=0.8):
import random
m = dataSet.shape[0]
index = list(dataSet.index)
random.shuffle(index)
dataSet.index = index
train = dataSet.loc[range(int(m*train_rate)),:]#取的是索引
test = dataSet.loc[range(int(m*train_rate),m),:]
test.index=list(range(test.shape[0]))
dataSet.index = list(range(dataSet.shape[0]))
return train,test
train,test=randSplit(dataSet)
test.shape
(30, 5)
#构建高斯朴素贝叶斯分类器
'''
函数名称:gnb_classify
函数说明:构建高斯朴素贝叶斯分类器,
参数说明:
train-训练集
test-测试集
返回:test-添加一列预测结果的测试集
modify:2019-05-28
'''
def gnb_classify(train,test):
labellist = train.iloc[:,-1].unique().tolist()
p = []
means = []
stds = []
for label in labellist:
subdata = train.loc[train.iloc[:,-1] == label]
p.append(subdata.shape[0]/train.shape[0])
means.append(subdata.iloc[:,:-1].mean().tolist())
stds.append(subdata.iloc[:,:-1].std().tolist())
res = []
p = np.array(p)
means = np.array(means)
stds = np.array(stds)
for i in range(test.shape[0]):
t = np.array(test.iloc[i,:-1]).T
pro = np.e**(-(t-means)**2/(2*stds**2))*(1/(np.sqrt(2*np.pi*stds**2)))
P = pro.prod(axis=1)
P = P*p
res.append(labellist[P.argmax()])
test['predict']=res
print(f'错误率为{(test.iloc[:,-1]!=test.iloc[:,-2]).mean()}')
return test
test = gnb_classify(train,test)
错误率为0.06666666666666667
实例:使用sklearn.GaussianNB进行鸢尾花数据集分析
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn import datasets
#切分数据集
iris = datasets.load_iris()
Xtrain,Xtest,Ytrain,Ytest = train_test_split(iris.data,iris.target,test_size=0.2)
#建模
clf = GaussianNB()
clf.fit(Xtrain,Ytrain)
GaussianNB(priors=None, var_smoothing=1e-09)
#在测试集上执行预测,proba导出的是每个样本属于某类的概率
a = clf.predict(Xtest)
prob = clf.predict_proba(Xtest)
#预测准确率
clf.score(Xtest,Ytest)
1.0
待学习
混淆矩阵
布里尔分数
MultinomialNB
先验为多项式分布的朴素贝叶斯,它的假设特征是由一个简单多项式分布生成。多项分布可以描述各种类型样本出行次数的频率,因此多项式朴素贝叶斯非常适合用于描述出现次数或者出现次数比例的特征。
该模型常用于文本分类,特征表示的是次数,例如某个词语的出现次数
多项式分布公式如下:
其中,
指的是第k个类别的第j为特征的第l个取值条件概率。
是训练集中输出第k类的样本个数,
是一个大于0的常数,常常取值为1,即拉普拉斯平滑,也可以取其他值
sklearn中MultinomialNB
class sklearn.naive_bayes.MultinomialNB(alpha=1.0,fit_prior=True,class_prior=None)
参数说明:
- alpha:浮点型可选参数,默认为1,就是添加拉普拉斯平滑,即上述公式的 ,如果这个参数设置为0,就是不添加平滑
- fit_prior:布尔型可选参数,默认为True。表示是否要考虑先验概率。如果为false,则所有样本都输出相同的先验概率,否则可以让算法自己从训练集样本来计算先验概率,即 或者通过第三个参数class_prior输入先验参数
- class_prior:认为设定的先验参数
MultinomialNB中的方法:
- fit
- get_params
- set_params
- partial_fit:非常重要的方法,用于训练集数据非常大,不能一次全部参入内存的时候。这时我们可以把训练集分成若干等分,重复调用partial_fit来一步步学习。
- predict:直接给出测试集的预测类别输出
- predict_proba:给出测试集样本在各个类别上预测的概率
- predict_log_proba:给出测试集样本在各个类别上预测的概率的对数转化
- score
实例:使用sklearn.MultionmialNB进行新浪新闻分类
我们的数据集是已经分类好的新闻,储存在文件夹SogouC中。
这个例子的关键在于使用中文分词,可以直接使用python中的jieba组件,完成中文的分词
jieba库的使用教程:
https://github.com/fxsjy/jieba
import os
import jieba
'''
函数名称:TextProcessing
函数说明:导入分好类的新闻文本,并进行分词,最后按照test_size的比例将全部数据切分为训练集和测试集,并返回训练集中的词条
参数:folder_path-新闻文本所在的文件夹
返回:all_words_list - 训练集中的全部词条
train_data_list - 训练集数据
train_class_list - 训练集标签
test_data_list - 测试集数据
test_class_list - 测试集标签
modify:2019-05-30
'''
def TextProcessing(folder_path,test_size = 0.2):
folder_list = os.listdir(folder_path)
data_list = []
class_list = []
for folder in folder_list:
new_folder_path = os.path.join(folder_path,folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path)
for file in files:
with open(os.path.join(new_folder_path,file)) as f:
raw = f.read()
word_cut = jieba.lcut(raw)
data_list.append(word_cut)
class_list.append(folder)
#切分数据集
data_class_list = list(zip(data_list,class_list))
import random
random.shuffle(data_class_list)
index = int(len(data_list)*test_size)
train_list = data_class_list[index:]
test_list = data_class_list[:index]
train_data_list,train_class_list = zip(*train_list) #解压
test_data_list,test_class_list = zip(*test_list) #解压
#统计训练集词条
all_words={}
for sentence in train_data_list:
for word in sentence:
all_words[word]=all_words.get(word,0)+1
sort_all_words = sorted(all_words.items(),key = lambda x:x[1], reverse=True) #对词频进行排序
all_words_list,all_words_nums = zip(*sort_all_words)
all_words_list = list(all_words_list)
return all_words_list,train_data_list,train_class_list,test_data_list,test_class_list
all_words_list,train_data_list,train_class_list,test_data_list,test_class_list = TextProcessing('SogouC/Sample')
all_words_list[:12]
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/bp/tnctfw1x0zg2yt473wrd5ltw0000gn/T/jieba.cache
Loading model cost 0.761 seconds.
Prefix dict has been built succesfully.
[',', '的', '\u3000', '。', '\n', ' ', ';', '&', 'nbsp', '、', '在', '了']
我们会发现,训练集词条中存在很多标点符号或者无实际意义的词条,但统计这些词条出现的频率并不能帮助我们判断新闻的类别。所以接下来我们需要去掉训练集词条中这些无意义的词。
去除方法:
- 无意义的词->在’stopwords_cn.txt’文档中存储了常见的无意义的词条,如果训练集词条在’stopwords_cn.txt’文档中出现,则去掉训练集中的这个词条
- 标签符号和数字->用词条的长度和string.isdigit()函数来判断
'''
函数名称:MakeWordsSet
函数说明:读取文档中的内容,并去重
参数说明:words_file - 文件路径
返回:words_set - 读取内容的set集合
'''
def MakeWordsSet(words_file):
words_set = set()
with open(words_file) as f:
contend = f.readlines()
for line in contend:
words_set = words_set | set([line.strip()])
return words_set
words_set = MakeWordsSet('stopwords_cn.txt') #存储'stopwords_cn'中的词条
'''
函数名称:words_dict
函数说明:文本特征提取,去除无意义的词
参数说明:
all_words_list - 训练集所有文本列表
deleteN - 删除词频最高的deleteN个词
stopwords_set - 无意义词集
返回:
feature_words - 特征集
modify:2019-05-30
'''
def words_dict(all_words_list,deleteN,stopwords_set=set()):
feature_words=[]
for i in range(deleteN,len(all_words_list)):#前deleteN词不要
if(len(feature_words) == 1000):
break #控制feature_words的维数不超过1000
word = all_words_list[i]
if not word.isdigit() and not word in stopwords_set and 1<len(word)<5:
feature_words.append(word)
return feature_words
feature_words = words_dict(all_words_list,10,words_set)
feature_words[:10]
['中国', '游客', '旅游', '公司', '考生', '一个', '导弹', '大陆', '市场', '火炮']
可以看出,现在feature_words就很适合作为新闻分类的特征了
接下里就要使用sklearn中MultinomialNB,来确定deleteN这个参数的合适值
在使用sklearn之前,要先将文本向量化
'''
函数名称:TextFeatures
函数说明:根据feature_words将文本向量化
函数参数:
train_data_list - 训练集
test_data_list - 测试集
feature_words - 特征集
返回:
train_feature_list - 训练集向量化列表
test_feature_list - 测试集向量话列表
'''
def TextFeatures(train_data_list,test_data_list,feature_words):
def text_features(text,feature_words):
text_words = set(text)
features = [1 if word in text_words else 0 for word in feature_words]
return features
train_feature_list = [text_features(text,feature_words) for text in train_data_list]
test_feature_list = [text_features(text,feature_words) for text in test_data_list]
return train_feature_list,test_feature_list
train_feature_list,test_feature_list = TextFeatures(train_data_list,test_data_list,feature_words)
pd.DataFrame(train_feature_list).head() #方便查看词向量
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 990 | 991 | 992 | 993 | 994 | 995 | 996 | 997 | 998 | 999 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 1000 columns
'''
函数名称:TextClassifier
函数说明:新闻分类器
参数:
train_feature_list - 向量化的训练集特征文本
test_feature_list - 向量化的测试集特征文本
train_class_list - 训练集分类标签
test_class_list - 测试集分类标签
返回:test_accuray - 分类器精度
modify:2019-05-30
'''
def TextClassifier(train_feature_list,test_feature_list,train_class_list,test_class_list):
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB()
clf.fit(train_feature_list,train_class_list)
test_accuray = clf.score(test_feature_list,test_class_list)
return test_accuray
test_accuray = TextClassifier(train_feature_list,test_feature_list,train_class_list,test_class_list)
test_accuray #超级惨的准确度
0.5555555555555556
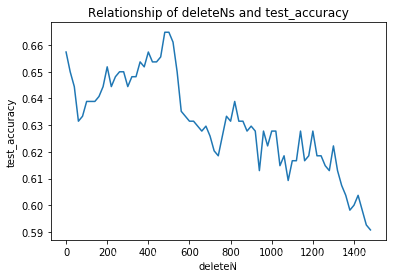
有了上面的全部函数后,我们就可以编写函数,绘制分类正确率与deleteN之间的关系曲线,选择合适的deleteN的数值
写之前,先回顾下之前写的全部函数:
- TextProcessing(folder_path,test_size = 0.2)
- return all_words_list,train_data_list,train_class_list,test_data_list,test_class_list
- 导入分好类的新闻文本,并进行分词,最后按照test_size的比例将全部数据切分为训练集和测试集,并返回训练集中的词条
- MakeWordsSet(words_file)
- return words_set
- 读取文档中的内容,并去重
- words_dict(all_words_list,deleteN,stopwords_set=set())
- return feature_words
- 文本特征提取,去除无意义的词
- TextFeatures(train_data_list,test_data_list,feature_words)
- return train_feature_list,test_feature_list
- 根据feature_words将文本向量化
- TextClassifier(train_feature_list,test_feature_list,train_class_list,test_class_list)
- return test_accuray
- 新闻分类器
accuracy = []
for i in range(30):
#获取数据
folder_path = 'SogouC/Sample'
all_words_list,train_data_list,train_class_list,test_data_list,test_class_list = TextProcessing(folder_path,test_size = 0.2)
#整理'stopwords_cn.txt文档'
stopwords_file = 'stopwords_cn.txt'
stopwords_set = MakeWordsSet(stopwords_file)
#改变deleteN的值,记录对应的正确率
test_accuracy_list =[]
deleteNs = range(0,1500,20)
for deleteN in deleteNs:
feature_words = words_dict(all_words_list,deleteN,stopwords_set)
train_feature_list,test_feature_list = TextFeatures(train_data_list,test_data_list,feature_words)
test_accuracy = TextClassifier(train_feature_list,test_feature_list,train_class_list,test_class_list)
test_accuracy_list.append(test_accuracy)
accuracy.append(test_accuracy_list)
import pandas as pd
meanaccuracy = pd.DataFrame(accuracy,columns = range(0,1500,20)).mean()
#绘图
import matplotlib.pyplot as plt
plt.figure()
plt.plot(deleteNs,meanaccuracy)
plt.title('Relationship of deleteNs and test_accuracy')
plt.xlabel('deleteN')
plt.ylabel('test_accuracy')
plt.show()
import numpy as np
meanaccuracy.idxmax()
480
这样就可以确定一定较为合适的deleteN的值
BernoulliNB
BernoulliNB就是先验为伯努利分布的朴素贝叶斯,假设特征的先验概率为二元伯努利分布,即如下式:
此时l只有两种取值,即x_{jl}只能取0或者1
在伯努利模型中,每个特征的取值是布尔型,即true和false,在文本分类中,就只一个特征有没有在一个文档中出现。
总结
- 一般来说,如果样本特征的分布大部分是连续值,使用GaussianNB会比较好
- 如果样本特征的分布大部分是多元离散值,使用MultinomialNB会比较好
- 如果样本特征的分布是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB
总结
朴素贝叶斯推断的优点:
- 生成式模型,通过计算概率来进行分类,可以用来处理多分类问题
- 对小规模的数据表现很好,算法简单,适合增量式训练
朴素贝叶斯推断的缺点:
- 对输入数据的表达形式很敏感
- 由于朴素贝叶斯的“朴素”特点,所以会带来精确率上的损失
- 需要计算先验概率,分类决策存在错误率
