刚开始面对数据的时候,我们需要考虑数据的一些特性。通过熟悉数据集的特性,有利于方便和确定后续的模型训练和开发,通过这篇文章你能够学习到:
1、如何来检查数据
2、异常值的检测
3、使用平行坐标图来寻找重要属性
4、通过可视化来寻找属性之间以及属性与标签之间的关系
数据集使用的是UCI提供的一个岩石和水雷的分类数据,数据集中的特征值代表声呐接收器在不同地点接受到的返回信号,一半数据返回的声呐信号表示的是岩石,一半表示的是水雷。数据集下载地址:https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data
一、检查数据
1、统计数据的规模
统计数据的规模主要包括,数据的行数和数据的特征数量
- import pandas as pd
- if __name__ == "__main__":
- #读取数据
- sonar_data = pd.read_csv("G:/dataset/sonar.csv")
- print(sonar_data.shape)
- #(208, 62)
通过上面的结果可以发现,该数据集一共包含了208条数据,和62列,其中第一列表示的是数据的编号,最后一列表示的是该条数据所对应的类标,其中M表示水雷,R表示岩石,剩下的60列是特征的数量。
2、统计数据的缺失情况
- #统计行数的缺失情况
- print(sonar_data[sonar_data.isnull()].count(axis=1))
- #统计列的缺失情况
- print(sonar_data[sonar_data.isnull()].count(axis=0))

因为数据的行和列比较多就只截取一部分,发现中间有些行和列无法查看,下面统计有缺失值的总行数和中列数
- print(sonar_data[sonar_data.isnull()].count(axis=1).sum())
- #0
- #统计有缺失值的中列数
- print(sonar_data[sonar_data.isnull()].count(axis=0).sum())
- #0
统计发现,行和列中都没有缺失值。所以我们这里就不需要做缺失值处理,一般情况下的数据都有缺失值,对于缺失值的处理通常有两种方式:

a、删除包含缺失值的行数据,这种情况通常是针对于数据量比较大,而且缺失数据的行不是很多的情况下。
b、使用特殊值来填充行数据,特殊值可以视同属性的平均值或者是0,还可以通过构建一个模型来预测缺失值。这种缺失值的处理方式通常是针对于,数据非常宝贵,获取的代价比较高或者是数据本身就比较少。
3、数据的统计分析
- #查看前5行数据
- print(sonar_data.head(n=5))
- #查看后5行数据
- print(sonar_data.tail(n=5))
前五行数据

后5行数据
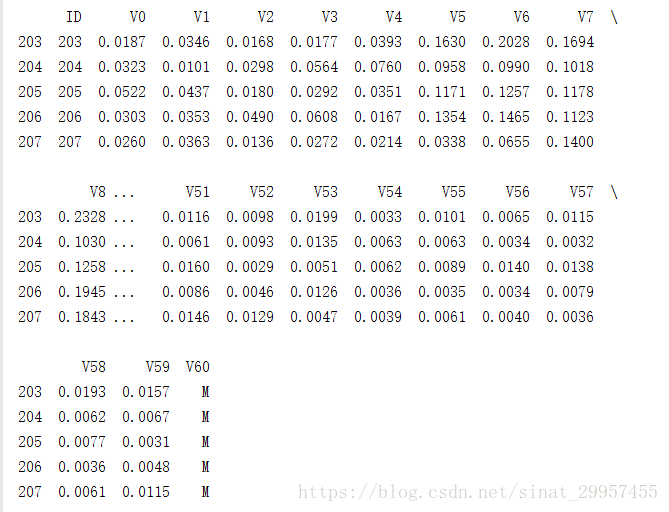
通过查看表格的前几行和最后几行数据发现,表格的前半部分对应的标签是R(岩石),表格的后半部分对应的标签是M(水雷)。
- #查看每列数据的均值、标准差、分位数、最大最小值
- print(sonar_data.describe())

数据太多就只截取了最后几列的统计特征,通过分析比较列不同分位数之间的差异,如果存在某一个差异严重异于其他差异,则说明存在异常点。
二、异常值检测
下面通过probplot函数来分析数据中是否含有异常值,分布图展示了数据的百分位边界与高斯分布的同样百分位的边界对比。如果,该属性服从高斯分布(正态分布),绘制出来的图是一条直线。下面我们观察数据第四列的分位数图
- import scipy.stats as stats
- import pylab
- #绘制第四列数据的分位数图
- stats.probplot(sonar_data.ix[:,3],dist="norm",plot=pylab)
- #设置x轴的标签
- pylab.xlabel("分位数")
- #设置y轴的标签
- pylab.ylabel("已排序数值")
- #设置标题
- pylab.title("概率图")
- pylab.show()
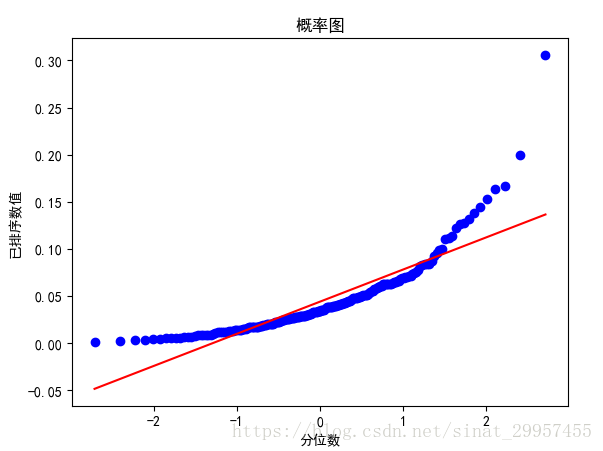
通过第四列的分位数图可以发现,数据的分位数图在最小值和最大值有点偏离直线,所以这个属性的左右两边尾部的数据要多于高斯分布的尾部数据。
如果数据集中包含异常值影响到训练的模型和模型预测的结果。当模型训练完成之后,通过这个模型来预测数据,观察模型预测错误的数据是否和数据中的异常值有关。如果是异常值造成的影响,可以采取一些步骤来进行校正。处理方法如下:
a、通过复制预测错误的数据来增加这些数据在数据集中的比重。
b、将模型预测错误的数据单独拿出来进行训练。
c、如果在实际情况中,不会遇到这种异常值的情况,可以将数据集中的这些数据做删除处理。
三、使用平行坐标图来寻找重要特征
平行坐标图(parallel coordinates plot)用来可视化具有多个属性的数据。平行坐标图是由一条一条的折线所组成的,每条折线表示一条数据,折线上的折点表示这条数据在该个属性值上的取值。下面通过观察平行坐标图来分析不同属性对于水雷和岩石的区分程度。
- import matplotlib.pyplot as plt
- for i in range(208):
- #判断该条数据是岩石(R)还是水雷(M),
- if sonar_data.ix[i,61] == "M":
- #用红色的折线表示水雷
- broken_line_color = "red"
- else:
- #用蓝色的折线表示岩石
- broken_line_color = "blue"
- #获取数据的属性值,不包括ID列
- data_attr = sonar_data.ix[i,1:61]
- data_attr.plot(color=broken_line_color)
- plt.xlabel("属性索引")
- plt.ylabel("属性值")
- plt.title("平行坐标图")
- plt.show()
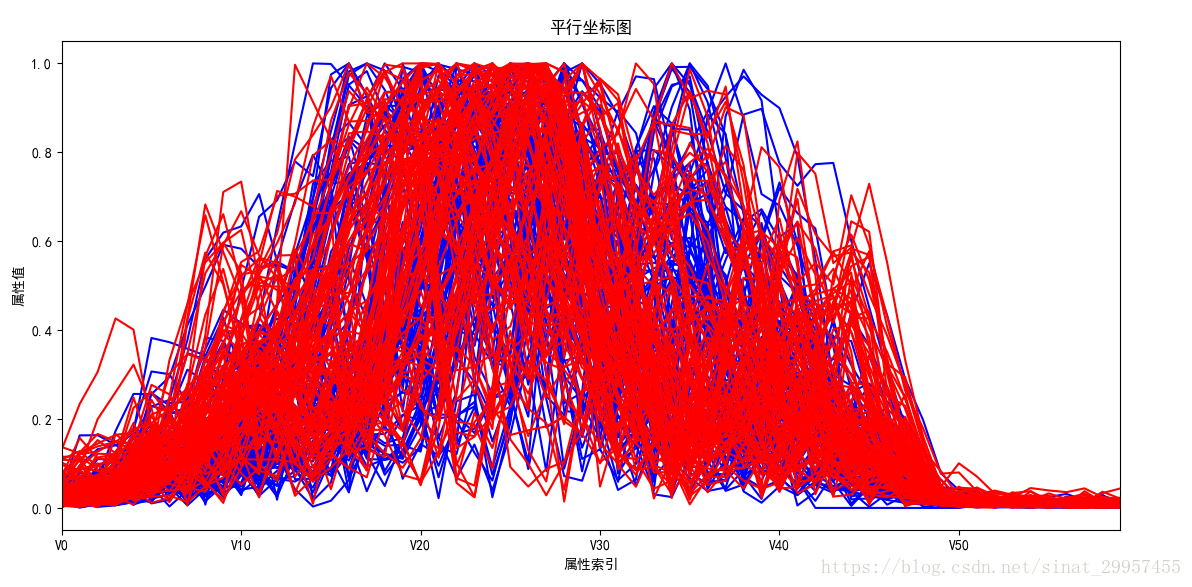
通过平行坐标图可以发现,好像看不出来有什么好的属性能够将蓝色的折线和红色折线区分开来。仔细一看,在属性索引为V30到V40之间,蓝色折线稍微靠山一点,而红色的折线比较靠下一点。所以这些特征后面在进行模型训练的时候,需要加以考虑。
四、寻找属性之间以及属性与标签之间的关系
1、通过散点图来分析属性与属性之间的关系
散点图就是数据在直角坐标系平面上的分布图,通过散点图可以观察自变量与因变量之间的关系。
- #绘制V1和V2的散点图
- plt.scatter(sonar_data.ix[:,2],sonar_data.ix[:,3])
- plt.xlabel("V1")
- plt.ylabel("V2")
- plt.show()

- #绘制V1和V21的散点图
- plt.scatter(sonar_data.ix[:,2],sonar_data.ix[:,22])
- plt.xlabel("V1")
- plt.ylabel("V21")
- plt.show()

通过观察V1和V2以及V1和V21之间的散点图可以发现,V1和V2之间存在较强的相关关系(散点图呈直线,V2随着V1的增大而增大),而V1和V21之间并没有存在明显的相关性。
2、通过散点图来分析属性与标签之间的关系
因为标签是字符串,所以我们需要将标签进行数值化,将M变成1,R变成0,然后再绘制V1与标签之间的散点图
- #将标签数值化
- for i in range(208):
- if sonar_data.ix[i,61] == "M":
- #将标签为M转成1
- sonar_data.ix[i,61] = 1
- else:
- #将标签为R转成0
- sonar_data.ix[i,61] = 0
- #绘制V1和标签的散点图
- plt.scatter(sonar_data.ix[:,2],sonar_data.ix[:,61])
- plt.xlabel("V1")
- plt.ylabel("标签值")
- plt.show()
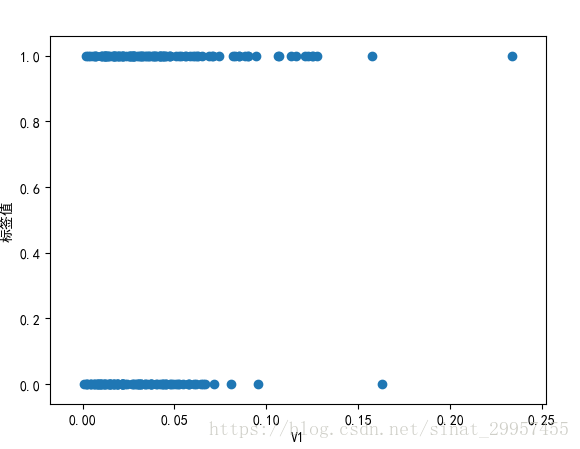
通过上面V1与标签之间的散点图发现,大部分的点都已经重叠在一起,无法分析点是如何沿线分布的。下面通过两个方法来解决这个问题:
a、在标签值上叠加一个范围在(-0.1,0.1)之间的随机数
b、将点的颜色设置成透明,这样重叠的部分就会比较明显
- import random
- for i in range(208):
- if sonar_data.ix[i,61] == "M":
- #将标签为M转成1,并叠加一个随机数
- sonar_data.ix[i,61] = 1 + random.uniform(-0.1,0.1)
- else:
- #将标签为R转成0,并叠加一个随机数
- sonar_data.ix[i,61] = 0 + random.uniform(-0.1,0.1)
- #绘制V1和标签的散点图
- plt.scatter(sonar_data.ix[:,2],sonar_data.ix[:,61],alpha=0.5)
- plt.xlabel("V1")
- plt.ylabel("标签值")
- plt.show()

通过V1和标签之间的散点图可以发现,标签为R的数据V1的值大部分在0.075以内,而标签为M的数据的范围稍微大一点。
3、通过热图来分析属性之间的相关性
- #获取相关系数矩阵
- corrMat = sonar_data.corr()
- #绘制热图
- plt.pcolor(corrMat)
- plt.show()

热图是通过属性之间的相关系数进行绘制的,沿对角线区域的浅色区域相关性较高。当属性的个数较多的时候就不方便使用热图进行分析,我们可以通过分析相关系数矩阵来寻找属性之间的关系。如果相关系数为1,表示属性之间完全相关。相关系数大于0.7表示相关性很高,如果模型的多个属性之间的相关性很高的时候会导致预测结果不稳定。对于相关性很高的属性,我们可以做特征的合并以及降维处理。