1.可以用作损失函数的有均方误差:
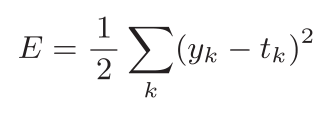
这里,yk 是表示神经网络的输出,tk 表示监督数据,k表示数据的维数。
将正确解标签表示为1,其他标签表示为0的表示方法称为one-hot表示。
均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和。现在,我们用Python来实现这个均方误差,
实现方式如下所示:
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)>>> # 设“2”为正确解
>>> t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
>>>
>>> # 例1:“2”的概率最高的情况(0.6)
>>> y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
>>> mean_squared_error(np.array(y), np.array(t))
0.097500000000000031
>>>
>>> # 例2:“7”的概率最高的情况(0.6)
>>> y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
>>> mean_squared_error(np.array(y), np.array(t))
0.59750000000000003这里举了两个例子。第一个例子中,正确解是“2”,神经网络的输出的最大值是“2”;第二个例子中,正确解是“2”,神经网络的输出的最大值是“7”。如实验结果所示,我们发现第一个例子的损失函数的值更小,和监督数据之间的误差较小。也就是说,均方误差显示第一个例子的输出结果与监督数据更加吻合。
2.除了均方误差之外,交叉熵误差(cross entropy error)也经常被用作损失函数。交叉熵误差如下式所示:
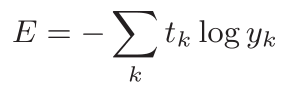
这里,log表示以e为底数的自然对数(loge)。并且,tk 中只有正确解标签的索引为1,其他均为0(one-hot表示)。因此实际上只计算对应正确解标签的输出的自然对数。比如,假设正确解标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差
是−log0.6 = 0.51;若“2”对应的输出是0.1,则交叉熵误差为−log0.1 = 2.30。也就是说,交叉熵误差的值是由正确解标签所对应的输出结果决定的。
用代码实现交叉熵误差:
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))这里,参数 y 和 t 是NumPy数组。函数内部在计算 np.log 时,加上了一个微小值 delta 。这是因为,当出现 np.log(0) 时,np.log(0) 会变为负无限大的 -inf ,这样一来就会导致后续计算无法进行。作为保护性对策,添加一个微小值可以防止负无限大的发生。下面,我们使用 cross_entropy_error(y, t)进行一些简单的计算
>>> t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
>>> y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
>>> cross_entropy_error(np.array(y), np.array(t))
0.51082545709933802
>>>
>>> y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
>>> cross_entropy_error(np.array(y), np.array(t))
2.3025840929945458第一个例子中,正确解标签对应的输出为0.6,此时的交叉熵误差大约为0.51。第二个例子中,正确解标签对应的输出为0.1的低值,此时的交叉熵误差大约为2.3。由此可以看出,这些结果与我们前面讨论的内容是一致的。
