前言
对比学习损失(Contrastive Learning Loss)是一种用于自监督学习的损失函数。它侧重于学习一个特征空间,其中相似的样本被拉近,而不相似的样本被推远。在二分类任务中,对比学习损失可以用来学习区分正负样本的特征表示。 对比学习损失函数有多种,其中比较常用的一种是InfoNCE loss。 InfoNCE Loss损失函数是基于对比度的一个损失函数,是由NCE Loss损失函数演变而来。
1.Alignment和Uniformity
1.1 Alignment
Alignment和Uniformity都是对比学习的表示能力的评判标准。出自论文《Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere》。
Alignment指的是相似的例子,也就是正例,映射到单位超球面后,应该具有比较接近的特征,球面距离应该比较近;

1.2 Uniformity
Uniformity指的是系统应该倾向于应该在特征里保留尽可能多的信息,映射到球面上就要求,单位球面上的特征应该尽可能地均与分布在球面上,分布越均匀,意味着保留的特征也就越多越充分。因为,分布越均匀,意味着各自保留各自的独有的特征,这代表着信息保留越充分。

Uniformity特性的极端反例,所有数据都映射到单位超球面的同一个点上,这代表着所有数据的信息都被丢掉,体现为数据分布极度不均匀得到了超球面上的同一个点。也就意味着,所有数据经过两次非线性计算之后都收敛到同一个常数上,这种异常情况我们称之为:模型坍塌(collapse)
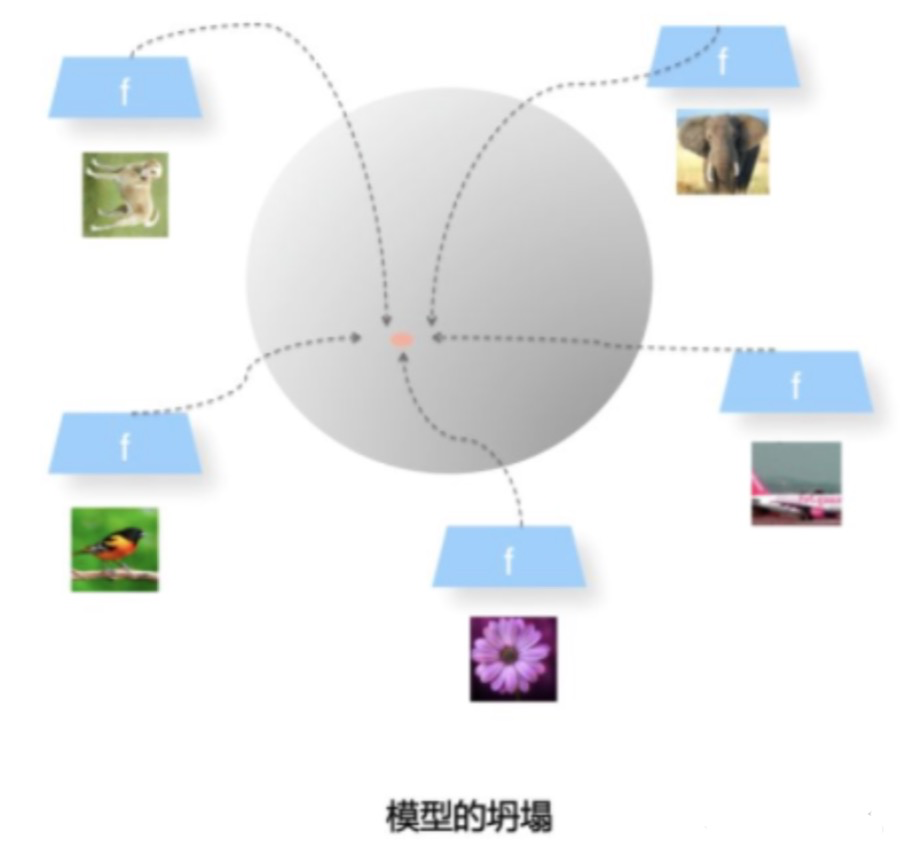
2.对比学习的损失函数
模型作决策时,假设输入到 softmax 前的结果用 sθ(w,c) 表示,实际上 sθ(w,c) 是有含义的,它是一个 socring function ,输出的分数用来量化 w 在上下文 c 中匹配性,那么 w 条件概率可以表示为以下形式:

其中分母部分是归一化常数,一个目的是用来让这个分布真的成为一个“分布”要求(分布积分=1),很多时候,比如计算一个巨大(几十上百万词)的词表在每一个词上的概率得分的时候,计算这个分母会变得非常非常非常消耗资源。
所以在一些应用,比如一个语言模型最后softmax层中,在推理阶段其实只要找到的那一项就够了,并不需要归一化(当然,这个操作其实是错误的。正确的推理是计算出每一个词的概率作为分布,然后从这个分布中采样得到一个正确的词,而不是直接挑一个分数最大的。但是一切为了运算方便)。但在模型的训练阶段,由于分母Z中是包含了模型参数的,所以也要一起参与优化,所以这个计算省不了(当然,softmax这个函数比较特殊,在实际应用中也相当于没有计算这个归一化项,只是计算了ground-truth word的那一项)。
2.1.NCE Loss
NCE(Noise contrastive estimation ),它是通过最大化同一个目标函数来估计模型参数 θ 和归一化常数,NCE 的核心思想就是通过学习数据分布样本和噪声分布样本之间的区别,从而发现数据中的一些特性,因为这个方法需要依靠与噪声数据进行对比,所以称为“噪声对比估计(Noise Contrastive Estimation)”
NCE(Noise contrastive estimation )核心思想是将多分类问题转化成二分类问题。分类器能够对数据样本和噪声样本进行二分类,一个类是数据类别 data sample,另一个类是噪声类别 noisy sample,通过学习数据样本和噪声样本之间的区别,将数据样本去和噪声样本做对比,也就是“噪声对比(noise contrastive)”,从而发现数据中的一些特性。
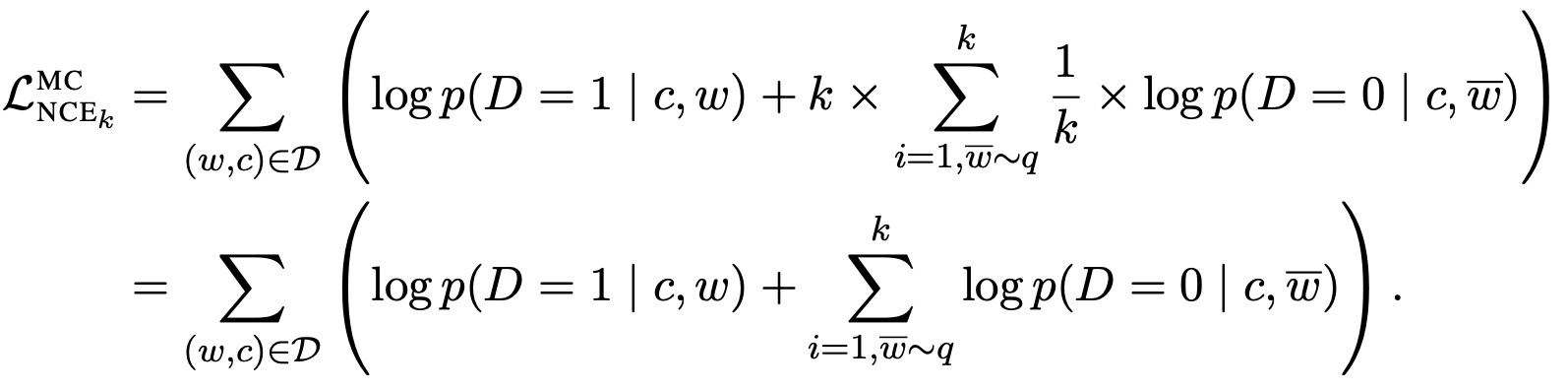
但是,如果把整个数据集剩下的数据都当作负样本(即噪声样本),虽然解决了类别多的问题,计算复杂度还是没有降下来,解决办法就是做负样本采样来计算loss,这就是estimation的含义,也就是说它只是估计和近似。一般来说,负样本选取的越多,就越接近整个数据集,效果自然会更好。
结论是:对于设置的噪声分布 ,我们实际上是希望它尽量接近数据分布,否则这个二分类任务就过于简单了,也就无法很好的学到数据特性。而作者通过实验和推导证明(我在第三节中也会简单的证明),当负样本和正样本数量之比 k 越大,那么我们的 NCE 对于噪声分布好坏的依赖程度也就越小。换句话说,作者建议我们在计算能力运行的条件下,尽可能的增大比值 k 。也许这也就是大家都默认将正样本数量设置为 1 的原因:正样本至少取要 1 个,所以最大化比值 k ,也就是尽可能取更多负样本的同时,将正样本数量取最小值 1。
另外,如果我们希望目标函数不是只针对一个特定的上下文 c ,而是使不同的上下文可以共享参数,至此 NCE 的构建就完成了。

总结一下就是:从上下文 c 中取出单词作为正样本,从噪声分布中取出单词作为负样本,正负样本数量比为 1:k ,然后训练一个二分类器,通过一个类似于交叉熵损失函数的目标函数进行训练。
2.2 InfoNEC Loss
Info NCE loss是NCE的一个简单变体,它认为如果你只把问题看作是一个二分类,只有数据样本和噪声样本的话,可能对模型学习不友好,因为很多噪声样本可能本就不是一个类,因此还是把它看成一个多分类问题比较合理,公式如下:
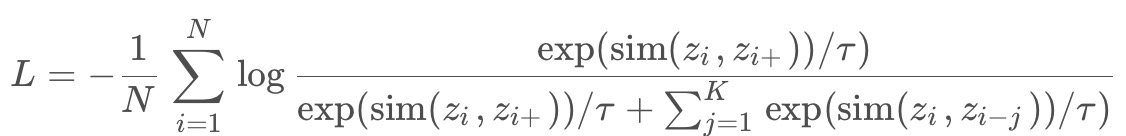
其中
是第i个样本的特征表示,
是其正样本,
是负样本,
是样本x 和y 之间的相似性度量(例如余弦相似性), τ 是一个温度参数,用于控制损失函数的形状。
在公式中可知,分子体现出了Alignment属性,它期望在超球面上正例之间的距离越近越好;分母则体现了Uniformity属性,它期望在负例对之间的距离尽可能的远,这种推力会尽量将点尽可能地均匀分布在超球面上,保留了尽可能多的有用信息。分子部分表示正例之间的相似度,分母表示正例与负例之间的相似度,因此,相同类别相似度越大,不同类别相似度越小,损失就会越小。
损失函数inforNCE会在Alignment和Uniformity之间寻找折中点。如果只有Alignment模型会很快坍塌到常数,损失函数中采用负例的对比学习计算方法,主要是靠负例的Uniformity来防止模型坍塌,很多典型的对比学习方法都是基于此的。infoNCE的思想就是正例之间相互吸引,负例之间相互排斥。
温度系数,是设定的超参数,它的作用是控制模型对负样本的区分度。温度参数会将模型更新的重点,聚焦到有难度的负例,并对他们做相应的惩罚,难度越大,也即与正例越接近,分配到的惩罚系数越多。在模型优化的过程中,需要将这些负例从正例旁边推开,使得其距离越远,是一种斥力。也就是,距离越近的负例会获得更多的权重,会具有更大的斥力,需要将其推开的力越大。
温度系数设的越大,sim的分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。
如果温度超参数设置过小,会导致损失函数分配的惩罚项范围越窄,更加聚焦在比较近的范围之内负例之中。同时,如果这些被覆盖的负例,因为数量减少了,会导致分配到的每个负例上的权重更大,斥力会更大。会导致模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。因此温度系数的设定是不可或缺的。
一般情况下,有效的负例只会聚焦在距离最近的一到两个最难的实例。我们希望能够在温度参数能够在alginment和unifoemity之间找一个平衡点。温度系数在处在一个平衡点时,超球面上的密集数据才会被打散,数据将会越来越均匀。
3.交叉熵损失函数
交叉熵损失函数的形式如图所示:
![]()
softmax公式如下所示:
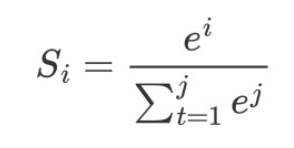
在分类中,由于输出是是one-hot向量,只有一个维度为1,其他维度都为0的向量,所以交叉熵损失函数如下所示:

这和InfoNCE Loss的损失函数的形式十分相似,不同在于,上式中的k在有监督学习里指的是这个数据集一共有多少类别,比如数据集中有1000类,k就是1000。 而在InfoNCE loss中类别只有两类或者几类,而交叉熵损失函数每一个用户或者商品自成一类,softmax操作在如此多类别上进行计算是非常耗时的,再加上有指数运算的操作,这导致计算复杂度相当高且不能实现。
Reference:
1.Noise Contrastive Estimation 前世今生——从 NCE 到 InfoNCE - 知乎
3.https://blog.csdn.net/qq_46006468/article/details/126076039