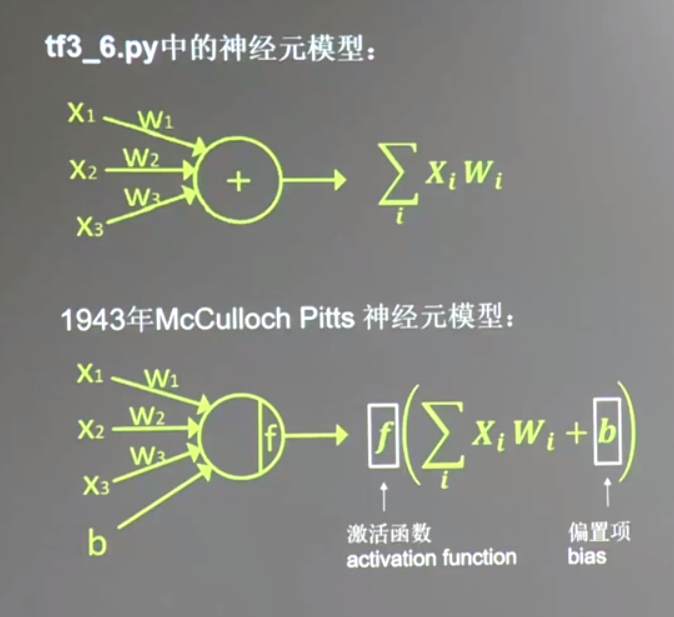
神经元模型

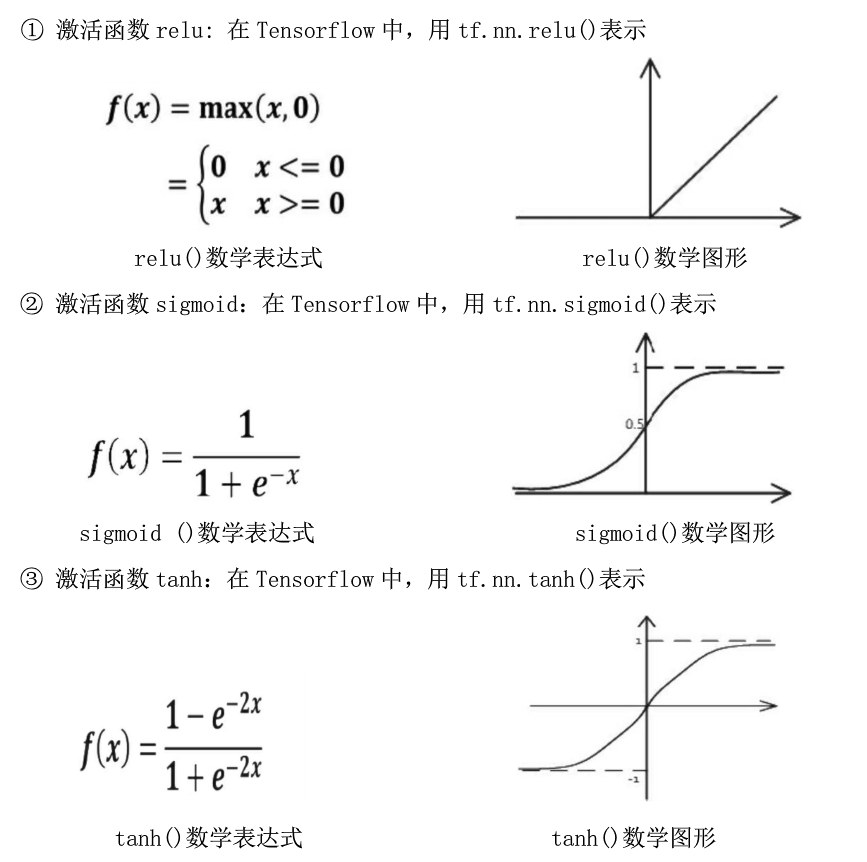
常用的激活函数(激励函数):
神经网络(NN)复杂度:多用神经网络层数和神经网络参数个数来表示
层数 = 隐藏层层数+1个输出层
参数个数 = 总W(权重) + 总B(偏置)
比如


损失函数(loss):预测值y 和已知答案y_ 的差距
神经网络优化目标:使损失函数loss 达到最小
常用loss计算方法:均方误差MSE
公式: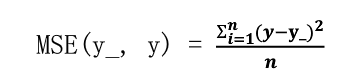
在TensorFlow中代码:
loss_MSE = tf.reduce_mean(tf.square(y-y_))
例子:

import tensorflow as tf import numpy as np BATCH_SIZE = 8 SEED = 23333 #X1和X2在影响Y的关系系数 Px1 = 3 Px2 = 2 rdm = np.random.RandomState(SEED) X = rdm.rand(320, 2) #此处用关系系数加权得到Y Y_ = [[Px1*x1+Px2*x2+(rdm.rand()/10.0 -0.05)]for (x1, x2) in X] #定义神经网络的输入、参数和输出,定义前向传播过程 x = tf.placeholder(tf.float32, shape=(None, 2)) y_ = tf.placeholder(tf.float32, shape=(None, 1)) w1 = tf.Variable(tf.random_normal([2, 1], stddev=1)) y = tf.matmul(x, w1) #定义损失函数和反向传播方法 loss_mse = tf.reduce_mean(tf.square(y_ - y)) train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss_mse) #生成会话 训练 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) for i in range(10000): start = (i*BATCH_SIZE) % 320 end = start + BATCH_SIZE sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]}) if i % 500 == 0: print ("w1:", sess.run(w1), "loss:", sess.run(loss_mse, feed_dict={x: X[start:end], y_: Y_[start:end]}))
最终得到接近于开始设定的Px1 = 3 Px2 =2
w1: [[2.9960208]
[1.9995174]] loss: 0.00053528405