深度学习中常用损失函数
损失函数是用来估量模型的预测值f(x)与真实值Y的不一致程度,它是一个非负值函数,通常用L(Y,f(x))来表示,损失函数越小,模型的鲁棒性越好。损失函数是经验风险函数的核心部分,也是结构风险函数的重要组成部分。模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子:
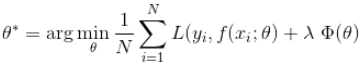
其中,前面的均值函数表示的是经验风险损失函数,L表示的是损失函数,后面的是正则化项。
L1损失函数和L2损失函数
这两个损失函数通常一起比较着来说。
L1损失函数,又叫最小绝对值偏差(LAE)。它把目标值与估计值的绝对差值的总和最小化:
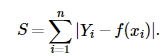
L2损失函数,也被称为最小平方误差。总的来说,它是把目标值与估计值的差值的平方和最小化。
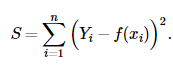
L2损失函数对异常点比较敏感,因为L2将误差平方化,使得异常点的误差过大,模型需要大幅度的调整,这样会牺牲很多正常的样本。
而L1损失函数由于导数不连续,可能存在多个解,当数据集有一个微笑的变化,解可能会有一个很大的跳动,L1的解不稳定。
smooth l1损失函数
在目标检测中,在reg坐标中用到smooth l1损失函数。如下式
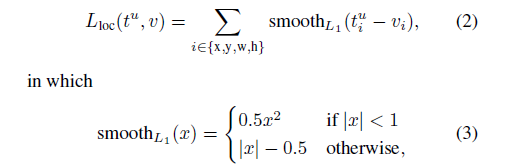
smooth l1损失韩式可以让离群点更加的鲁棒,相比于l1,其对离群点、异常值不敏感,可以控制梯度的量级使训练不容易跑飞。另外,smooth l1在零点处变得可导,函数更加的平滑。
交叉熵损失函数
交叉熵损失函数刻画的是两个概率分布之间的距离。如下式,交叉熵刻画的的是通过概率分布q来表达概率分布p的困难程度,其中p为真实分布,q为预测,交叉熵越小,两个概率分布越接近。
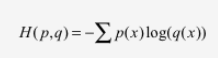
其实交叉熵损失函数来源于信息论中KL散度这一概念。具体的推导这里不细谈(主要是太懒了),感兴趣的可以参考这篇博客
在深度学习中,二分类通常通过sigmoid函数作为预测的输出,得到预测的分布,那对于多分类是怎样得到预测的分布的呢。答案是softmax。
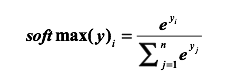
神经网络经过softmax之后,把神经网络的输出变成了一个概率分布。从而可以通过交叉熵来计算预测的概率分布与真实分布之间的距离了。
另外,目前深度学习中基本上都是用交叉熵损失函数,那么交叉熵损失函数好在哪里呢。
首先我们看L2损失函数的曲线
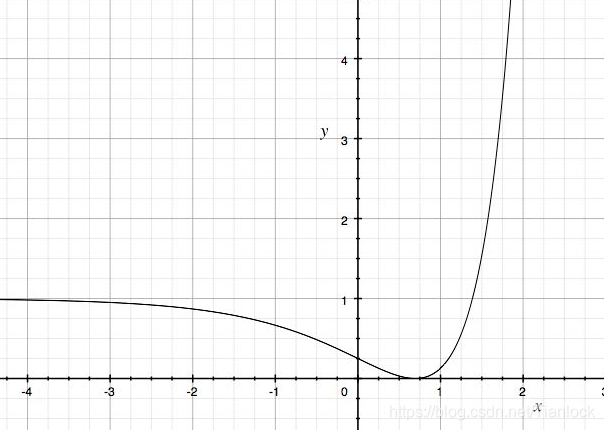
这是一个非凸的函数,也就是说梯度下降不一定能够保证达到全局最优解。
而交叉熵损失函数的曲线如下
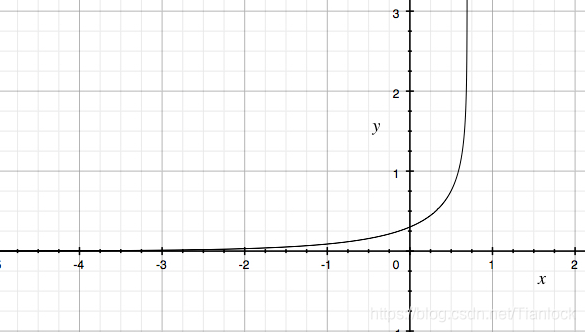
这是一个凸函数,曲线整体呈单调性,loss越大,梯度越大。便于反向传播时的快速优化。所以通常使用交叉熵损失函数。
Kaiming大佬在2018年针对目标检测中数据不平衡问题提出了交叉熵损失函数的改进版本,focalloss,具体的讲解我在之前的博客里有提到,感兴趣的可以去看一下。
其他机器学习常见损失函数
0 -1 损失函数
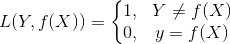
仅当预测为真时取1,其余为0. 0-1损失非凸、非光滑。使得算法很难直接对函数进行优化。
Hinge损失
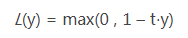
Hinge损失函数是0-1损失的一个代理损失函数。当t×y大于1时,不做任何惩罚。其在t×y=1处不可到,不能用梯度下降法进行优化,而是用次梯度下降法。
Logistic loss
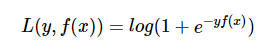
logistic loss也是0-1损失的代理损失函数,且该函数处处光滑,
指数损失函数
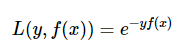
AdaBoost中使用的就是指数损失函数。
另外在深度学习领域,针对分类问题优化还有center loss等等,论文我还没有看,等以后遇到类似的问题看完论文之后再补充