1.Softmax + Cross Entropy Loss(交叉熵)(加入交叉熵的原因是考虑到数值的稳定性)
损失函数:


适应场景:单标签分类问题
该损失函数各个标签之间不独立
2.Sigmoid Cross Entropy Loss
损失函数:
L维多标签场景的损失函数为:
使用场景:预测目标概率分布,可用于多标签学习(如社会年龄估计)
注意:1.目标输出需要归一化到【0,1】;损失层的输出要有具体的意义;各个标签之间相互独立即每一维是独立的。
3.Euclidean Loss(欧氏损失)
损失函数: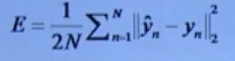
适用场景:实数值回归问题
注意:欧氏损失前可以增加Sigmoid操作进行归一化,相应的输出标签也归一化。
4.Contrastive Loss(Siamess Net)
损失函数:
适用场景:人脸测度学习
5.Center loss(softMax的一种改进)

6.Triplet Loss

适用场景:learning to rank ;人脸识别(FaceNet)
7.Moon Loss
Basic Idea:考虑多标签分类中训练和测试阶段样本分布的不平衡
对每个属性计算概率:
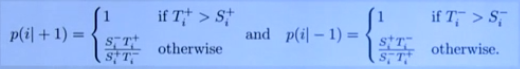
混合损失函数:
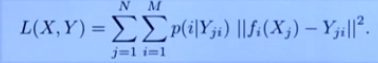
8.Focal Loss
Basic Idea:用一个权重条件函数去降低易分样本对损失的贡献
解决方案:

适用场景:解决one-stage的目标检测中背景样本和前景样本的不平衡问题
9.Large-Margin Loss(softmax的改进)
Basic Idea:在SoftMax Loss中通过约束权重矩阵的夹角引入Margin正则