文章目录
一、K-Means聚类算法原理过程
K-means算法的目的概述:K-means聚类算法是比较流行的无监督学习算法,输入无标签的数据,然后将数据聚类成不同的组
我们下面先看看K-means算法的一般过程:
【Step1】:随机初始化K个聚类中心
【Step2】:接下来,重复以下步骤

下面,我们通过图更加深刻地理解K-means算法的执行过程:
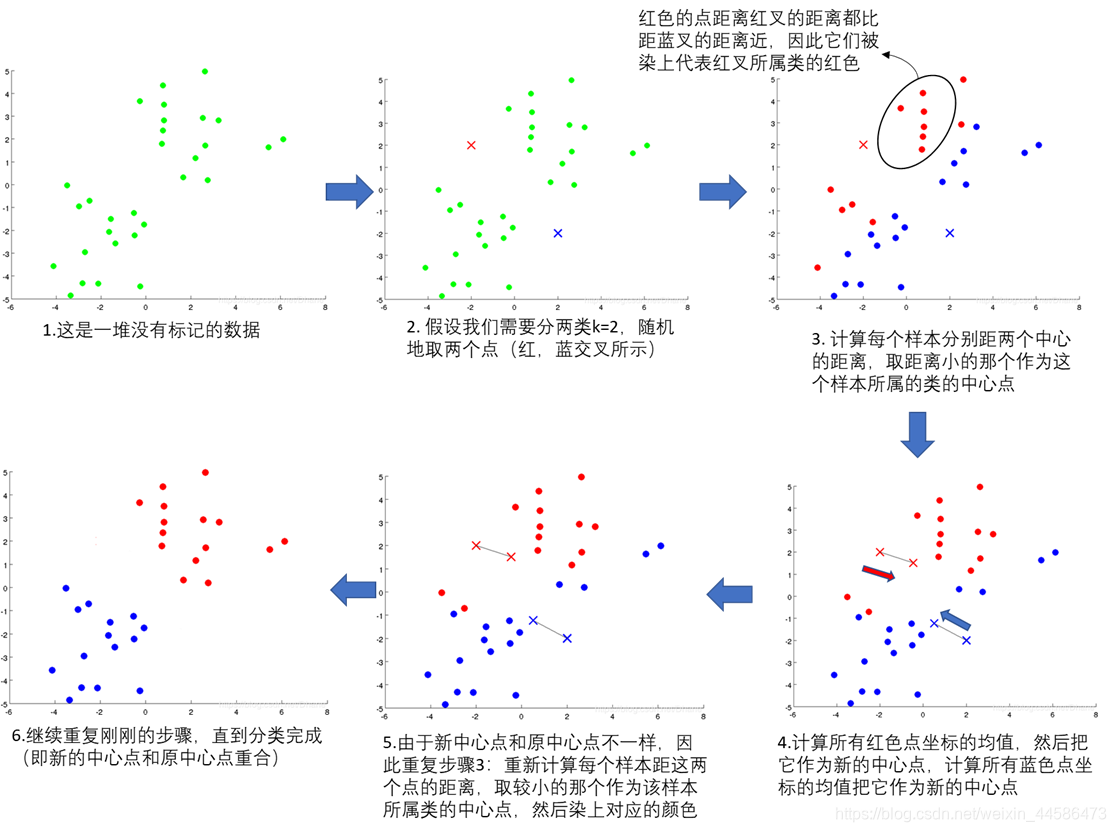
1.1 K-means聚类的一些细节
1.1.1 样本 与中心点 距离的衡量
我们一般用下面的式子来考虑样本
与中心点
距离:
而我们就是需要找到令
最小的k值,也即是这个样本
所属于的类的中心点
1.1.2 K-means聚类算法的应用场合
对于一些能够肉眼很明显地分辨出几个簇的数据,用K-means聚类算法当然是相当不错的,像上图的情况,但是对于一些数据分离不佳的情况,我们依然是可以用K-means聚类算法来进行分类的。
像下面这个服装经营商的例子:假设我们收集了不同人群的身高和体重,这些数据通常是密密麻麻,难以一眼分辨分离情况的,但是我们依然可以使用K-means聚类

比如说,我们需要设计S、M、L三种尺码的衣服,但是需要预计生产的数量,我们可以用K-means聚类算法把数据分成下面三种:
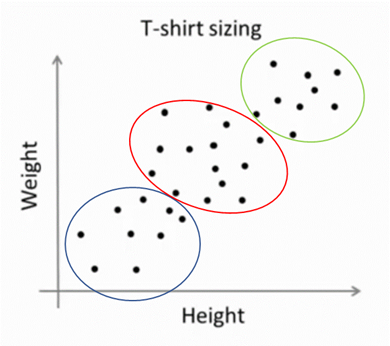
这样就可以很好地指导我们生产服装的数量
1.1.3 K-means聚类算法的优化目标
想要搞清楚为什么经过有限次数的迭代之后,算法就可以把数据进行分类?那么我们就需要明白算法的优化目标,以及算法是如何优化这个目标的。
而很明显,算法是想让每一样本离它所属的类的中心点的距离比距其他类的中心点的距离都近
我们用函数可以这样表达:
其中,对
我需要解释一下:
就是第m个样本所属的类的中心点的下标k
下面,我们就来看看算法是什么时候偷偷优化了这个函数吧:
大家请翻到前面看看K-means聚类算法的算法步骤:

1.1.4 随机初始化的要点
还记得我们在算法过程里面的第一步吗:随机选取K个点作为初始化的簇中心点。但是实际上我们并不这样做,我们一般我在样本里面选K个点,让它们作为初始化的簇中心点
但是大家记得一件事情:就是我们的算法有可能会陷入局部最优的情况,也就是说同一个数据集可能会出现很多不同的分类情况,像下面的例子:
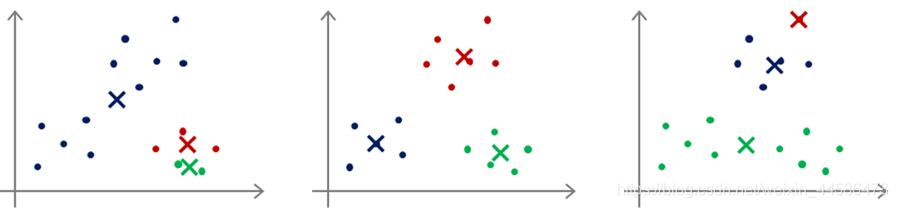
这三种情况都可以满足算法终止的条件,但是有些并不是最好的,遇到这种情况:当K值不大的时候(比如说3,4,5),那么我们可以考虑多次运行程序以求得一个较好的分类
1.1.5 类的数量K的选取
方法一是“肘部法则”,不过并不推荐,这里简单一下:肘部法则就是在使用K-means聚类算法时,我们多选择几个K值,用算法分别试一下这些K值,然后做出优化函数J的曲线,如果曲线长这样:
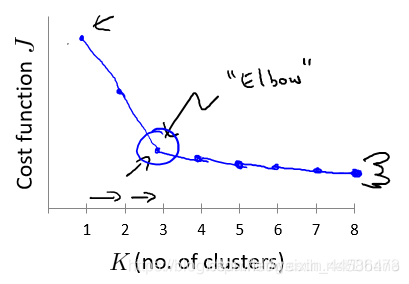
那很棒,我们就选取J函数的拐点,也就是上图K = 3的地方作为分类数。因为这样的图形酷似人的手臂,拐点是肘关节,因此叫“肘部法则”
但是,常常事与愿违,我们有时候得到的优化函数曲线可能很平滑,让人根本无法看出拐点emmmm
事实上,K值的选择还是取决于你的实际目的。在用K-means算法时,要好好想想自己用这个算法是要去干嘛的?我所选取的分类数能不能为我后续的工作服务。就像上面服装厂家的例子,如果只能生产S、M、L三种尺码衣服,那么很明显就分成3类好了,分成5类6类7类显然是不合理的
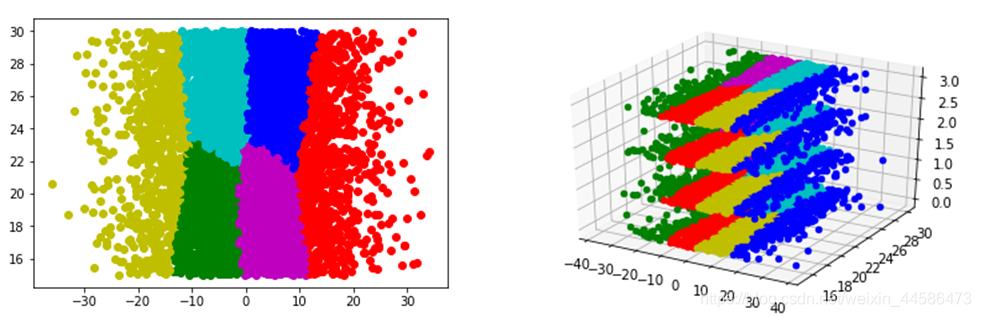
二、二维,三维数据K-means算法的Python实现
先上完整代码:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 空间三维画图
import random
def K_means(data, K):
"""
程序说明:
本函数实现二维和三维数据的K_means聚类算法
data:输入的数据,维度(m, 2)或者(m, 3)
K:表示希望分出来的类数
"""
num = np.shape(data)[0]
cls = np.zeros([num], np.int)
random_array = np.random.random(size = k)
random_array = np.floor(random_array*num)
rarray = random_array.astype(int)
print('数据集中随机索引', rarray)
center_point = data[rarray]
print('初始化随机中心点', center_point)
change = True #change表示簇中心是否有过改变,又改变了就需要继续循环程序,没改变则终止程序
while change:
for i in range(num):
temp = data[i] - center_point #此句执行之后得到的是两个数或三个数:x-x_0,y-y_0或x-x_0, y-y_0, z-z_0
temp = np.square(temp) #得到(x-x_0)^2等
distance = np.sum(temp,axis=1) #按行相加,得到第i个样本与所有center point的距离
cls[i] = np.argmin(distance) #取得与该样本距离最近的center point的下标
change = False
for i in range(k):
# 找到属于该类的所有样本
club = data[cls==i]
newcenter = np.mean(club, axis=0) #按列求和,计算出新的中心点
ss = np.abs(center_point[i]-newcenter) # 如果新旧center的差距很小,看做他们相等,否则更新之。run置true,再来一次循环
if np.sum(ss, axis=0) > 1e-4:
center_point[i] = newcenter
change = True
print('K-means done!')
return center_point, cls
"""
补充一点说明:我们下面左图的代码show_picture函数需要用到的cls,
其实就是一个[1, num]的矩阵,里面的元素就是对应第i个样本所属聚类中心的下标
放在第一个for循环的后面:cls[i] = np.argmin(distance)
因为如果第一个for循环得到的聚类已经是最终结果,那么它也不会执行后面的中心点更新的代码了
"""
def show_picture(data, center_point, cls, k):
num,dim = data.shape
color = ['r','g','b','c','y','m','k']
if dim == 2:
for i in range(num):
mark = int(cls[i])
plt.plot(data[i,0],data[i,1],color[mark]+'o')
#下面把中心点单独标记出来:
for i in range(k):
plt.plot(center_point[i,0],center_point[i,1],color[i]+'x')
elif dim == 3:
ax = plt.subplot(111,projection ='3d')
for i in range(num):
mark = int(cls[i])
ax.scatter(data[i,0],data[i,1],data[i,2],c=color[mark])
for i in range(k):
ax.scatter(center_point[i,0],center_point[i,1],center_point[i,2],c=color[i],marker='x')
plt.show()
k=6 ##分类个数
z_MF = []
yl_OSNR = []
pn = np.random.normal(0, 10, 6400)
for i in range(6400):
index_y = random.uniform(15,30)
index_z = random.randint(0,3)
z_MF.append(index_z)
yl_OSNR.append(index_y)
pn = pn[:, np.newaxis]
#print(pn)
y = np.array(yl_OSNR)
y = y[:,np.newaxis]
#print(y)
z_MF = np.array(z_MF)
z = z_MF[:,np.newaxis]
temp = np.hstack((pn, y))
#data = np.hstack((temp, z))
#print(data.shape)
center_point, cls = K_means(temp, k)
show_picture(temp, center_point, cls, k)
下面给大家看看效果: