1.去重复:duplicated
import pandas as pd
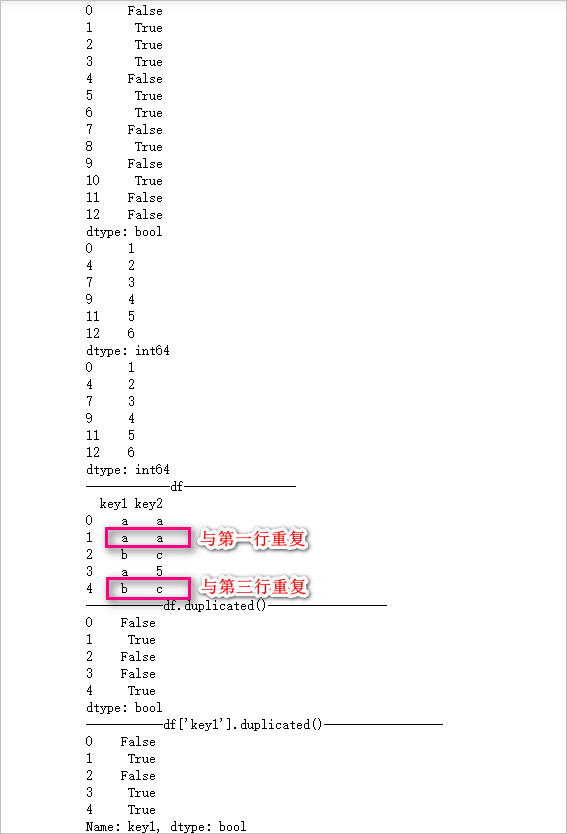
s = pd.Series([1,1,1,1,2,2,2,3,3,4,4,5,6])
# 通过duplicated判断是否重复
print(s.duplicated())
# 通过布尔判断,得到不重复的值
print(s[s.duplicated() == False])
# 移除重复drop_duplicates
s_re = s.drop_duplicates()
print(s_re)
# Dataframe中使用duplicated
df = pd.DataFrame({'key1':['a','a','b','a','b'],
'key2':['a','a','c',5,'c']
})
print('------------df----------------')
print(df)
print('-----------df.duplicated()-----------------') # 第2行与第1行重复了,所以为True,第5行与第3行重复,所以为True
print(df.duplicated())
print('-----------df[\'key1\'].duplicated()-----------------')
print(df['key1'].duplicated())输出结果:
2.替换:replace
import pandas as pd
import numpy as np
s = pd.Series(list('aseaasasx'))
print(s.replace('a', np.nan)) # 替换a为np.nan
print(s.replace(['a','s'], np.nan)) # a替换为s,然后再将s替换为np.nan
print(s.replace({'a':'@@@','s':'***'})) # 一次性替换为多个值输出结果:
