我是跟着@Jack-Cui 老哥的博客爬的,发现爬取的网站更新了,不得不跟着更新爬取的代码
原博客:https://blog.csdn.net/c406495762/article/details/78123502
要点:1.charles抓包、分析、compose功能
2.浅复制 headers.copy()
3.re.findall 的用法
4.js的 encodeURIComponent 转码使用urllib parse.unquote
注:fiddler局限性很大,tunnel to的网页不能显示,问了很多爬虫前辈,加上百度,我用上了charles花瓶,挺好用的,大家可以自行研究下,得搞破解版才行哦!
###http://api.xfsub.com/index.php?url=http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1
现在这个旋风破解又特么更新了,不能直接播放,得搞个框架才行,非常麻烦

但我还是忍着恶心去解析了这个vip播放网站,到最后一步下载视频时,居然更恶心!!
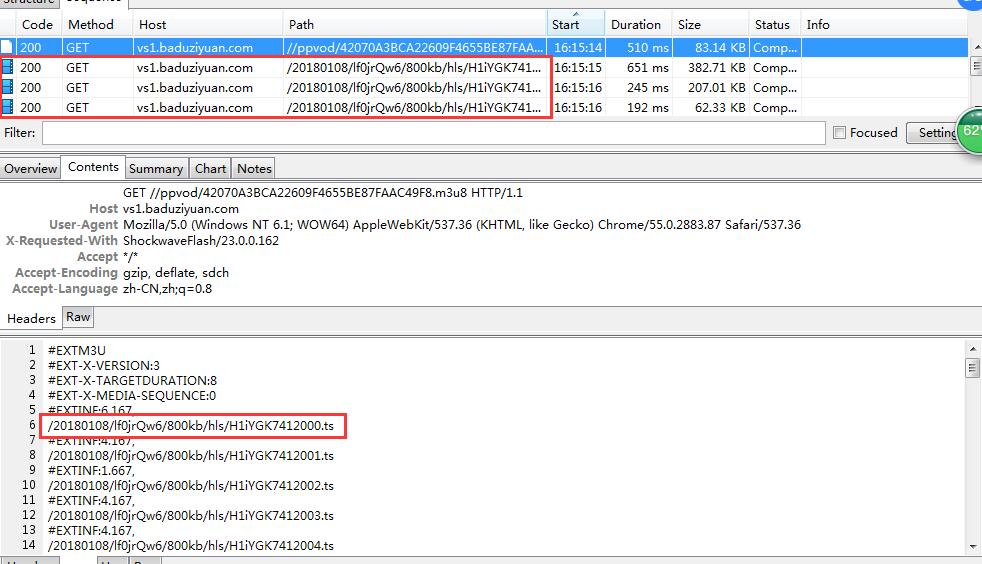
文件居然是ts格式,还是几百个!!每个5秒钟,所以我做到这一步就不搞了,我把代码贴上来,大家可以看看思路
import requests,json,re from bs4 import BeautifulSoup from urllib import parse class download_movie(): def __init__(self,url): self.headers={'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'} self.first_url='http://api.xfsub.com/index.php?url='+url.split('#')[0] self.main_ip='https://api.177537.com' def second_url(self): '''因为现在是用iframe框架,所以我搞多一步,返回的url就是 https://api.177537.com/?url= + http://www.iqiyi.com/v_19rrkqj6kg.html 偷懒应该可以直接上url就行了 headers的referer爱奇艺的应该是固定的字符url''' headers=self.headers.copy() if 'www.iqiyi.com' in self.first_url: headers['referer']='http://api.xfsub.com/index.php?url=http://www.iqiyi.com/v_19rr7qhfg0.html' req = requests.get(self.first_url, headers=headers) bf = BeautifulSoup(req.text, 'lxml') api_url = bf.find('iframe')['src'] return api_url def post_info(self): '''api_url=https://api.177537.com/?url=http://www.iqiyi.com/v_19rrkqj6kg.html 用正则表达式求出post的4个参数,求出来的是5个,实际只需要4个 headers的referer就是api.xfsub.com/index.php?url='+url''' api_url=self.second_url() headers = self.headers.copy() headers['referer'] =self.first_url req = requests.get(api_url, headers=headers) req_json = re.findall('"url.php", (.+),', req.text)[0] req1 = re.findall('(.+),"ckey1"', req_json)[0] + '}' info = json.loads(req1) return info def post_url(self): '''把那4个参数post到https://api.177537.com/url.php(好像是固定网站) 会返回包含电影地址的网站,不过要注意play这个参数,返回的url类型不同的!!''' info=self.post_info() data = {'time': info['time'], 'key': info['key'], 'url': info['url'], 'type': info['type']} req = requests.post(self.main_ip+'/url.php', headers=self.headers, data=data) url =json.loads(req.text)['url'] play=json.loads(req.text)['play'] return play,url def movie_url(self): '''play=m3u8时,url="http%3A%2F%2Fvs1.baduziyuan.com%2F%2Fppvod%2F42070A3BCA22609F4655BE87FAAC49F8.m3u8" 所以得用unquote转码 play=xml时,url=/url.php?key=357350013cc120d659b1a4d5e1d7acfe&time=1523979626&url=http%3A%2F%2Fwww.iqiyi.com%2Fv_19rrluypwg.html&type=iqiyi&xml=1 需要加头才能get''' play,url=self.post_url() print(play,url) if play=='m3u8': url1=parse.unquote(url) self.m3u8_movie(url1) elif play=='xml': url1=self.main_ip+url self.xml_movie(url1) def xml_movie(self,url1): '''这种情况得到的是xml,电影片段零碎, 都是http://61.179.109.165/14/w/89aae12482708fc94010602ff1b34520.mp4?type=ppbox.launcher&key=a32e0dd656ea3cc2f31b98b102ce71c6&k=02ecf7808b8c478dca6b1a98cd4c595a-a396-1523991314', 每段都有7分钟,几十个文件!!''' req = requests.get(url1, headers=self.headers) bf = BeautifulSoup(req.text, 'xml') # 因为文件是xml格式的,所以要进行xml解析。 video_url = bf.find_all('file') urls = [] for ip in video_url: urls.append(ip.string) print(urls) def m3u8_movie(self,url1): '''这种情况得到的是text,电影片段很零碎,而且地址还得自己加头, 都是/20180108/lf0jrQw6/800kb/hls/H1iYGK7412000.ts, 每段都只有几秒,几百个文件,很恶心!!''' req = requests.get(url1, headers=self.headers) text=re.findall(r'(.+.ts)',req.text) head = re.findall('(^.+com)', url1)[0] urls=[] for path in text: urls.append(head+path) print(urls) url='http://www.iqiyi.com/v_19rrluypwg.html' text=download_movie(url) text.movie_url()
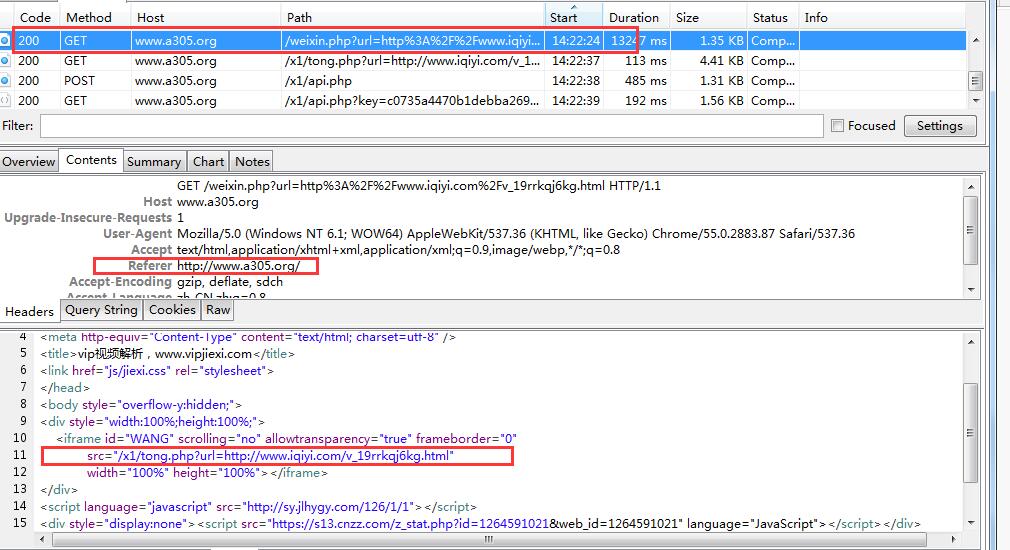
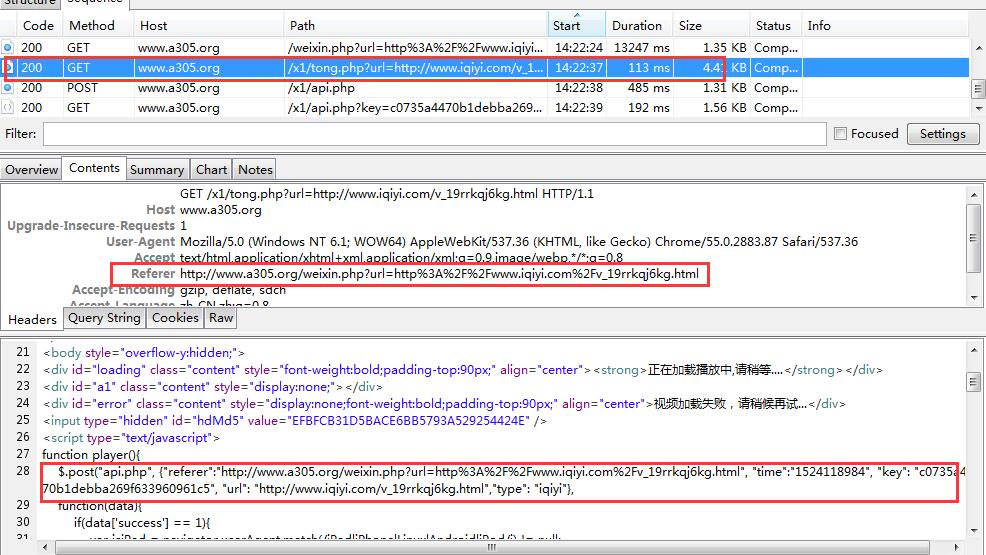
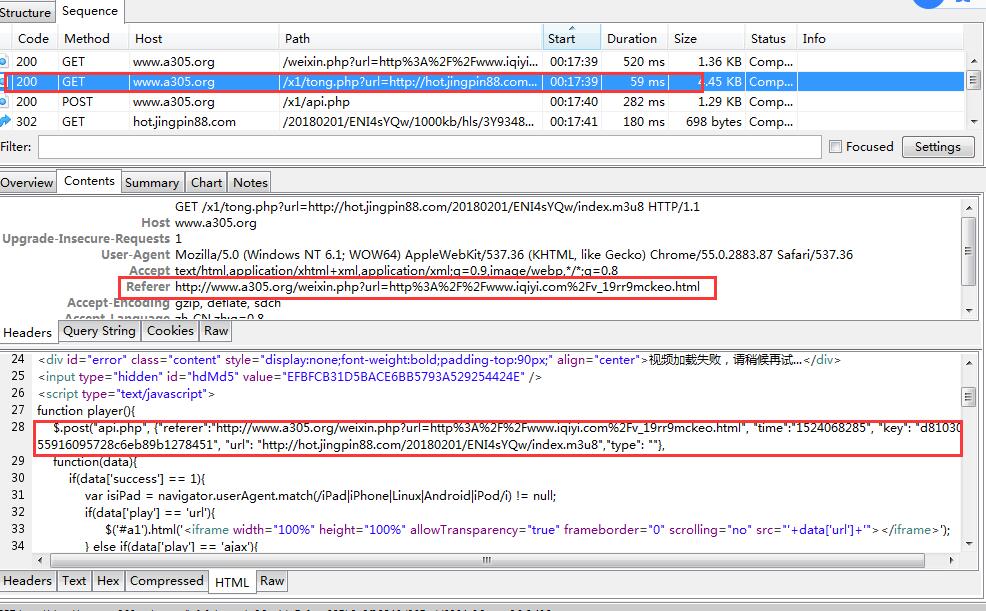
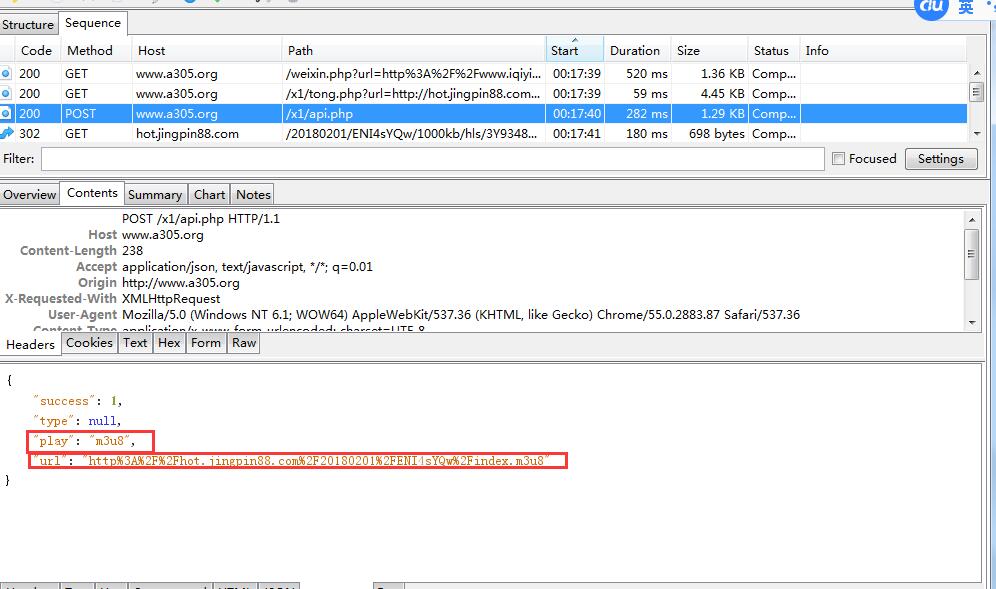
另外在说说Jack-Cui之前视频破解的解析网站,还有个更好的,不需要搞iframe框架,直接就能看vip的,我用charles分析了下,大同小异,把图片贴上来,如果有兴趣,可以直接爬这个网站,不过到了最后一步,视频文件还是几秒的,几百个,下载还是算了吧!!
---------------------------------------
-------------------------------

----------------

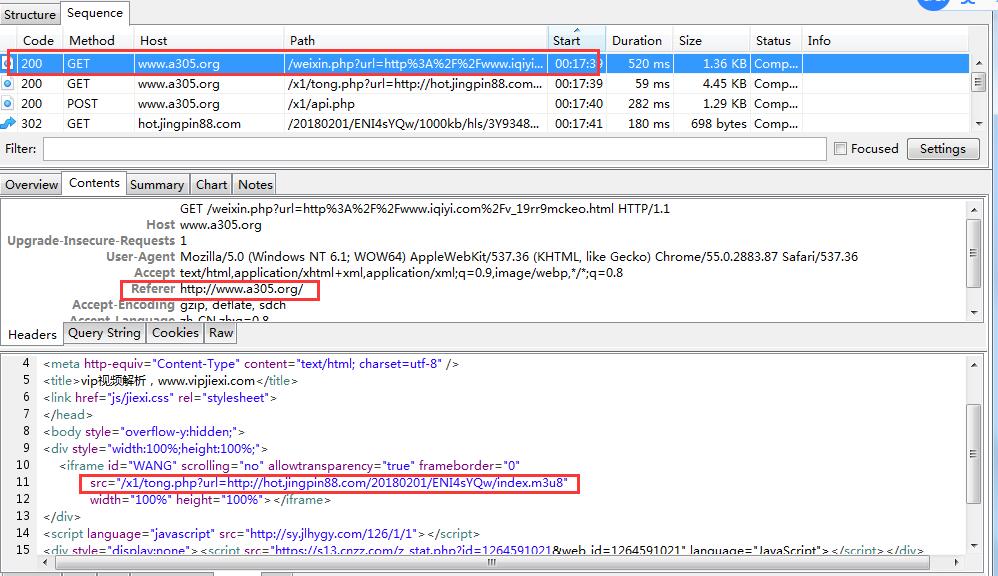
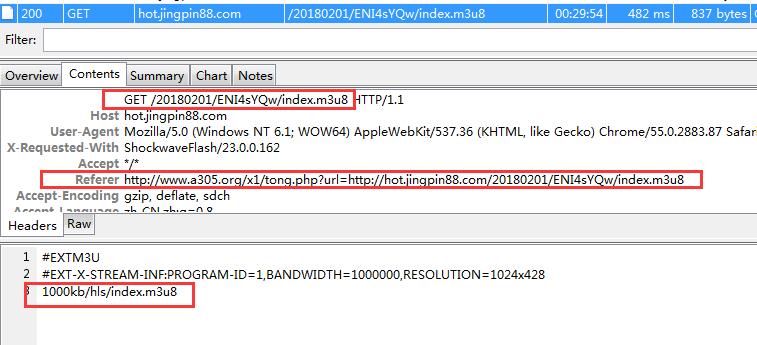
不知为什么,有2种格式或者播放的文件,一个是7分钟,一个是5秒钟的,链接也完全不同
---------------------------
--------------------------
---------------------------------------

-------------------------
---------------------------------
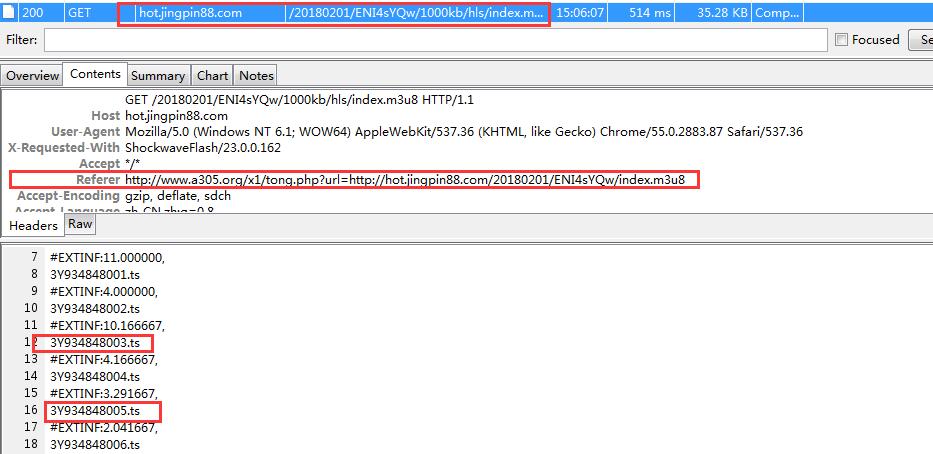
要注意referer一定要有,不然打不开网页,charles的compose功能很好用,大家可以研究下