利用LSTM对IMDB Reviwe文本进行分类,数据集可以在kaggle官网上获取,
kaggle比赛
或者https://pan.baidu.com/s/1EYoqAcW238saKy3uQCfC3w
提取码:ilze
# 导入相应的包
import pandas as pd
import warnings
import re
import matplotlib.pyplot as plt
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Dense, LSTM, Embedding, Dropout, Conv1D, MaxPooling1D, Bidirectional
from keras.models import Sequential
warnings.filterwarnings('ignore')
# 读取数据
df1 = pd.read_csv('word2vec-nlp-tutorial/labeledTrainData.tsv', sep='\t', error_bad_lines=False)
df2 = pd.read_csv('word2vec-nlp-tutorial/imdb_master.csv', encoding="latin-1")
df3 = pd.read_csv('word2vec-nlp-tutorial/testData.tsv', sep='\t', error_bad_lines=False)
df2 = df2.drop(['Unnamed: 0','type','file'],axis=1)
df2.columns = ["review","sentiment"]
df2 = df2[df2.sentiment != 'unsup']
df2['sentiment'] = df2['sentiment'].map({'pos': 1, 'neg': 0})
# 合并数据
df = pd.concat([df1, df2]).reset_index(drop=True)
train_texts = df.review
train_labels = df.sentiment
test_texts = df3.review
# 英文缩写替换
def replace_abbreviations(text):
texts = []
for item in text:
item = item.lower().replace("it's", "it is").replace("i'm", "i am").replace("he's", "he is").replace("she's", "she is")\
.replace("we're", "we are").replace("they're", "they are").replace("you're", "you are").replace("that's", "that is")\
.replace("this's", "this is").replace("can't", "can not").replace("don't", "do not").replace("doesn't", "does not")\
.replace("we've", "we have").replace("i've", " i have").replace("isn't", "is not").replace("won't", "will not")\
.replace("hasn't", "has not").replace("wasn't", "was not").replace("weren't", "were not").replace("let's", "let us")\
.replace("didn't", "did not").replace("hadn't", "had not").replace("waht's", "what is").replace("couldn't", "could not")\
.replace("you'll", "you will").replace("you've", "you have")
item = item.replace("'s", "")
texts.append(item)
return texts
# 删除标点符号及其它字符
def clear_review(text):
texts = []
for item in text:
item = item.replace("<br /><br />", "")
item = re.sub("[^a-zA-Z]", " ", item.lower())
texts.append(" ".join(item.split()))
return texts
# 删除停用词 + 词形还原
def stemed_words(text):
stop_words = stopwords.words("english")
lemma = WordNetLemmatizer()
texts = []
for item in text:
words = [lemma.lemmatize(w, pos='v') for w in item.split() if w not in stop_words]
texts.append(" ".join(words))
return texts
# 文本预处理
def preprocess(text):
text = replace_abbreviations(text)
text = clear_review(text)
text = stemed_words(text)
return text
train_texts = preprocess(train_texts)
test_texts = preprocess(test_texts)
max_features = 6000
texts = train_texts + test_texts
# 分词
tok = Tokenizer(num_words=max_features)
tok.fit_on_texts(texts)
# 序列
list_tok = tok.texts_to_sequences(texts)
maxlen = 130
seq_tok = pad_sequences(list_tok, maxlen=maxlen)
x_train = seq_tok[:len(train_texts)]
y_train = train_labels
embed_size = 128
# lstm
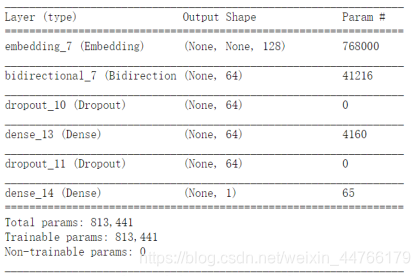
def get_lstm_model(max_features, embed_size):
model = Sequential()
model.add(Embedding(max_features, embed_size))
model.add(Bidirectional(LSTM(32, recurrent_dropout=0.1)))
model.add(Dropout(0.25))
model.add(Dense(64))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
return model
# 训练
def model_fit(model, x, y):
return model.fit(x, y, batch_size=100, epochs=20, validation_split=0.2)
model = get_lstm_model(max_features, embed_size)
model_train = model_fit(model, x_train, y_train)
x_test = seq_tok[len(train_texts):]
# 预测
def model_predict(model, x):
return model.predict_classes(x)
y_pred = model_predict(model, x_test)
# 绘图
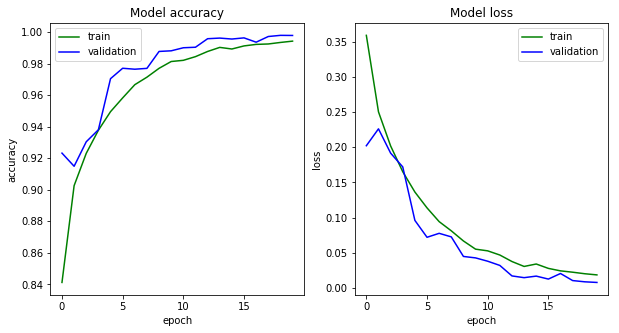
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.plot(model_train.history['acc'], c='g', label='train')
plt.plot(model_train.history['val_acc'], c='b', label='validation')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Model accuracy')
plt.subplot(122)
plt.plot(model_train.history['loss'], c='g', label='train')
plt.plot(model_train.history['val_loss'], c='b', label='validation')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Model loss')
plt.show()