一.安装相应依赖
pip3 install tensorflow==2.2.0
pip3 install numpy==1.19.3
pip3 install jieba==0.42.1
pip3 install nltk==3.6.2
pip3 install sklearn
pip3 install pandas==1.1.5
二.准备数据
# 相应的数据格式如下
{
"category": "Cigarette Manufacturing Machinery", "pro_title": "Thick syrup honey edible essential oil shampoo cream lotion water liquid milk bottle paste filling machine for liquid"}
三、使用步骤
1.引入库
# -*- coding: utf-8 -*-
# @Time : 2021/6/23 8:47
# @Author :
import pandas as pd
import re
import json
import numpy as np
import nltk
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM, SpatialDropout1D
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import EarlyStopping
import jieba as jb
2.相应数据格式转换
category_list = []
lst_dics = []
with open(r'data.json', mode='r', errors='ignore') as json_file:
for dic in json_file:
dd = json.loads(dic)
category = dd.get("category","")
if category not in category_list:
category_list.append(category)
lst_dics.append(dd)
lst_dics[0]

# rename columns
df = pd.DataFrame(lst_dics)
df = df.rename(columns={
"category": "cat", "pro_title": "review"})
# print 5 random rows
df.sample(5)

# 查看是否有空值
"在 cat 列中总共有 %d 个空值." % df['cat'].isnull().sum()
"在 review 列中总共有 %d 个空值." % df['review'].isnull().sum()
df[df.isnull().values == True]
df = df[pd.notnull(df['review'])]
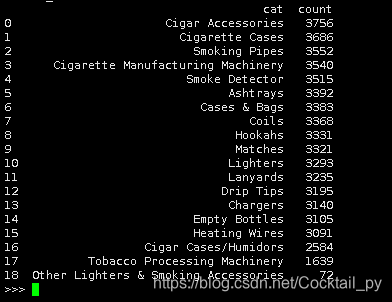
# 统计相应数量
d = {
'cat': df['cat'].value_counts().index, 'count': df['cat'].value_counts()}
df_cat = pd.DataFrame(data=d).reset_index(drop=True)
df_cat
3.数据预处理
接下来我们要将cat类转换成id,这样便于以后的分类模型的训练
df['cat_id'] = df['cat'].factorize()[0]
cat_id_df = df[['cat', 'cat_id']].drop_duplicates().sort_values('cat_id').reset_index(drop=True)
cat_to_id = dict(cat_id_df.values)
id_to_cat = dict(cat_id_df[['cat_id', 'cat']].values)
df.sample(10)

加载停用词
stopwords = nltk.corpus.stopwords.words("english")
删除非字母数字空符号外的所有符号
def remove_punctuation(line):
line = str(line)
if line.strip() == '':
return ''
rule = re.compile("[^0-9a-zA-Z\s-]")
line = rule.sub('', line).strip()
return line
df['clean_review'] = df['review'].apply(remove_punctuation)
df.sample(10)

分词,并过滤停用词
df['cut_review'] = df['clean_review'].apply(lambda x: " ".join([w for w in list(jb.cut(x)) if w not in stopwords]))
df.head()

4.数据预处理
# LSTM建模
# 设置最频繁使用的50000个词(在texts_to_matrix是会取前MAX_NB_WORDS,会取前MAX_NB_WORDS列)
MAX_NB_WORDS = 50000
# 每条cut_review最大的长度
MAX_SEQUENCE_LENGTH = 250
# 设置Embeddingceng层的维度
EMBEDDING_DIM = 100
tokenizer = Tokenizer(num_words=MAX_NB_WORDS, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~', lower=True)
tokenizer.fit_on_texts(df['cut_review'].values)
word_index = tokenizer.word_index
'共有 %s 个不相同的词语.' % len(word_index)

X = tokenizer.texts_to_sequences(df['cut_review'].values)
# 填充X,让X的各个列的长度统一
X = pad_sequences(X, maxlen=MAX_SEQUENCE_LENGTH)
# 多类标签的onehot展开
Y = pd.get_dummies(df['cat_id']).values
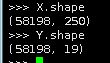
X.shape
Y.shape
拆分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.10, random_state=42)
print(X_train.shape, Y_train.shape)
print(X_test.shape, Y_test.shape)
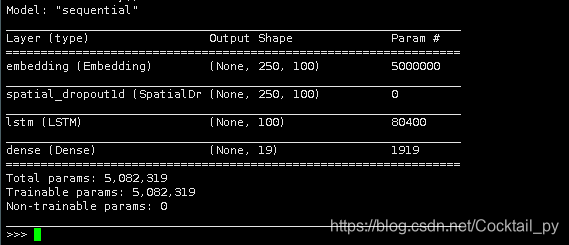
定义模型
model = Sequential()
model.add(Embedding(MAX_NB_WORDS, EMBEDDING_DIM, input_length=X.shape[1]))
model.add(SpatialDropout1D(0.2))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(len(category_list), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
模型训练
epochs = 5
batch_size = 64
history = model.fit(X_train, Y_train, epochs=epochs, batch_size=batch_size, validation_split=0.1,
callbacks=[EarlyStopping(monitor='val_loss', patience=3, min_delta=0.0001)])
accr = model.evaluate(X_test, Y_test)
'Test set\n Loss: {:0.3f}\n Accuracy: {:0.3f}'.format(accr[0], accr[1])

LSTM模型的评估
y_pred = model.predict(X_test)
y_pred = y_pred.argmax(axis=1)
Y_test = Y_test.argmax(axis=1)
查看相应精度
'accuracy %s' % accuracy_score(y_pred, Y_test)
print(classification_report(Y_test, y_pred, target_names=cat_id_df['cat'].values))

自定义预测
def predict(text):
txt = remove_punctuation(text)
txt = [" ".join([w for w in list(jb.cut(txt.lower())) if w not in stopwords])]
seq = tokenizer.texts_to_sequences(txt)
padded = pad_sequences(seq, maxlen=MAX_SEQUENCE_LENGTH)
pred = model.predict(padded)
cat_id = pred.argmax(axis=1)[0]
return cat_id_df[cat_id_df.cat_id == cat_id]['cat'].values[0]
predict("liquid bottling machine e cigarette liquid smoke oil filling machine for eliquid filling manual coffee filling machine")
>>'Cigarette Manufacturing Machinery'
四、Keras的Tokenizer
fit_on_texts(texts) :
参数 texts:要用以训练的文本列表。
返回值:无。
texts_to_sequences(texts) :
参数 texts:待转为序列的文本列表。
返回值:序列的列表,列表中每个序列对应于一段输入文本。
texts_to_sequences_generator(texts) :
本函数是texts_to_sequences的生成器函数版。
参数 texts:待转为序列的文本列表。
返回值:每次调用返回对应于一段输入文本的序列。
texts_to_matrix(texts, mode) :
参数 texts:待向量化的文本列表。
参数 mode:‘binary’,‘count’,‘tfidf’,‘freq’ 之一,默认为 ‘binary’。
返回值:形如(len(texts), num_words) 的numpy array。
fit_on_sequences(sequences) :
参数 sequences:要用以训练的序列列表。
返回值:无
sequences_to_matrix(sequences) :
参数 sequences:待向量化的序列列表。
参数 mode:‘binary’,‘count’,‘tfidf’,‘freq’ 之一,默认为 ‘binary’。
返回值:形如(len(sequences), num_words) 的 numpy array。
get_config:
将标记器的配置返回为Python字典,标记器使用的字数字典被序列化为纯JSON,以便其他项目可以读取配置
返回值:带有tokenizer配置的Python字典
to_json:
返回包含标记器配置的JSON字符串,要从JSON字符串加载标记器,请使用keras.preprocessing.text.tokenizer_from_json(json_string)。
返回值:包含标记器配置的JSON字符串
基于LSTM的中文文本多分类实战
Text Classification with NLP: Tf-Idf vs Word2Vec vs BERT
搞清楚TensorFlow2–Keras的Tokenizer