版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/dengxiayigetaishan/article/details/52770024
Rocchio算法
Rocchio算法的基本原理:它是基于向量空间模型进行文本分类的的思路。
步骤:
(1)先把属于一个类别的样本文档转换成文档向量。
(2)求属于一个类别的样本文档的质心向量(原型向量)。
(3)判断新文档属于哪个类别。
详解:
(1)如何把属于一个类别的样本文档转换为文档向量:例如:

对于这5个文档,用tf-idf 向量表示,具体的权重计算公式:
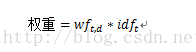
其中

公式中
 表示词项频率,例如1文档中chinese词项频率为2(这里只是作为例子讲解,数据量非常少)。N表示文档的数量;
表示词项频率,例如1文档中chinese词项频率为2(这里只是作为例子讲解,数据量非常少)。N表示文档的数量;
 表示出现词 t 的文档数量,例如上面chinese出现在4个文档中,所以其为4。运用上面的计算公式可以得下面的文档向量表(这里先看下表的前5个向量,后2个为质心向量)。
表示出现词 t 的文档数量,例如上面chinese出现在4个文档中,所以其为4。运用上面的计算公式可以得下面的文档向量表(这里先看下表的前5个向量,后2个为质心向量)。
表示词项频率,例如1文档中chinese词项频率为2(这里只是作为例子讲解,数据量非常少)。N表示文档的数量;
表示出现词 t 的文档数量,例如上面chinese出现在4个文档中,所以其为4。运用上面的计算公式可以得下面的文档向量表(这里先看下表的前5个向量,后2个为质心向量)。
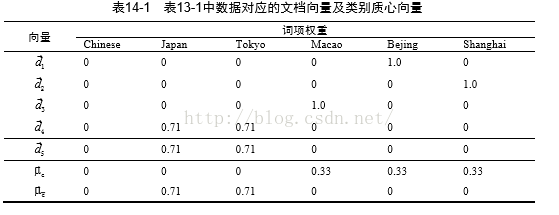
(2)求属于一个类别的样本文档的质心向量(原型向量):它是通过类别中文档向量的平均向量或者质心向量计算,即:
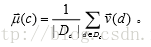
其中
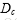 表示文档集中属于类别c的子文档的个数,
表示文档集中属于类别c的子文档的个数,
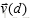 表示归一化之后的文档向量;上面后2个向量就是所求的质心向量。
表示归一化之后的文档向量;上面后2个向量就是所求的质心向量。
表示文档集中属于类别c的子文档的个数,
表示归一化之后的文档向量;上面后2个向量就是所求的质心向量。
有几个子文档类别,就可以得到几个质心向量,如下图,是三个子文档,分为3个类,其中实心黑为质心向量,圆圈属于China类,菱形属于UK类,叉属于Kenya类,而实心正方形为测试文档,图中可以看出属于kenya类。
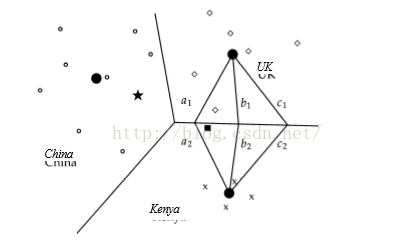
a1和a2,b1和b2,c1和c2距离UK和Kenya类的质心向量一样远,可以知道边界线是有2个类质心的等距的点集组成。(图中是可以看出的,但是如何用数学表示)
在二维平面中,这个直线的点可以表示为
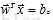 其中
其中
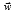 成为边界线(多维的话,边界就是一个超平面)的法向量,b为一个常数。那么
和b如何求呢?
成为边界线(多维的话,边界就是一个超平面)的法向量,b为一个常数。那么
和b如何求呢?
其中
成为边界线(多维的话,边界就是一个超平面)的法向量,b为一个常数。那么
和b如何求呢?
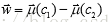
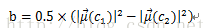 则可以求出:
则可以求出:
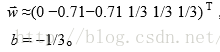
到目前为止,可以说,已经把类之间的边界线已找到。
(3)判断新文档属于哪个类别:
对于向量
 属于哪个类别判断,则:
属于哪个类别判断,则:
属于哪个类别判断,则:
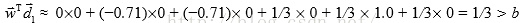
同样对于2<=i<=3,都有
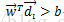 (A类),而对于i=4时,
(A类),而对于i=4时,
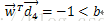 (B类),所以这就是2个类满足的条件,如何给一个新的测试文档,如果
(B类),所以这就是2个类满足的条件,如何给一个新的测试文档,如果
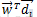 >b,则属于A类;否则属于B类。可以判断
属于B类。
>b,则属于A类;否则属于B类。可以判断
属于B类。
(A类),而对于i=4时,
(B类),所以这就是2个类满足的条件,如何给一个新的测试文档,如果
>b,则属于A类;否则属于B类。可以判断
属于B类。
至此,基本过程已经结束。