最近需要写一个神经网络模型来做分类。
作为此前没有实战过深度学习,只写过SVM之类的,学习过一些理论知识的新手,为了快速上手,第一想法就是找一个简单的demo跑通,对整个流程和结构有一个初步体验。于是在网上找了一个Tensorflow实战系列:手把手教你使用LSTM进行文本分类
但是教程存在一个问题,是没有把数据集分成训练和预测两个部分,导致学习过程中学习数据和预测数据产生混淆,让我有些迷茫,然后通过学习单个函数和尝试,跑通了代码。添加内容:
- 个别函数加入学习注释
- 新增预测样本,修改预测部分,把预测和训练两部分样本分离
遗留问题:之前写机器学习的时候习惯使用交叉验证(cross validation),在这个代码中没有看到有验证部分,后续会开始写需要写的代码,并看一些比这个稍微再复杂一些的代码,进一步了解深度学习编程。
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.contrib import learn
import numpy as np
from tensorflow.python.ops.rnn import static_rnn
from tensorflow.python.ops.rnn_cell_impl import BasicLSTMCell
# 数据
positive_texts = [
"我 今天 很 开心",
"我 很 高兴",
"他 很 高兴",
"他 很 开心"
]
negative_texts = [
"我 不 高兴",
"我 不 开心",
"他 很 不 高兴",
"他 很 生气"
]
label_name_dict = {
0: "正面情感",
1: "负面情感"
}
pre_texts = [
"谁 今天 不 开心",
"开心 吗",
"在 吗"
]
# 配置信息
embedding_size = 50
num_classes = 2
# 将文本和标签矢量化
all_texts = positive_texts + negative_texts
labels = [0] * len(positive_texts) + [1] * len(negative_texts)
max_document_length = 4
vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length)
datas = np.array(list(vocab_processor.fit_transform(all_texts))) # 按词建立字典
pre = np.array(list(vocab_processor.transform(pre_texts)))
vocab_size = len(vocab_processor.vocabulary_) # 字典长度
# 容器
datas_placeholder = tf.placeholder(tf.int32, [None, max_document_length]) #自适应行数,列数为max_document_length
labels_placeholder = tf.placeholder(tf.int32, [None])
# 构建随机的词向量矩阵
# tf.get_variable(name, shape, initializer): name变量的名称,shape变量的维度,initializer变量初始化的方式
embeddings = tf.get_variable("embeddings", [vocab_size, embedding_size], initializer=tf.truncated_normal_initializer)
embedded = tf.nn.embedding_lookup(embeddings, datas_placeholder)
# 将数据处理成LSTM的输入格式(时序)
rnn_input = tf.unstack(embedded, max_document_length, axis=1)
# 定义LSTM
lstm_cell = BasicLSTMCell(20, forget_bias=1.0)
rnn_outputs, rnn_states = static_rnn(lstm_cell, rnn_input, dtype=tf.float32)
#predict
logits = tf.layers.dense(rnn_outputs[-1], num_classes)
predicted_labels = tf.argmax(logits, axis=1)
losses = tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(labels_placeholder, num_classes),
logits = logits
)
mean_loss = tf.reduce_mean(losses)
optimizer = tf.train.AdamOptimizer(learning_rate=1e-2).minimize(mean_loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
feed_dict = {
datas_placeholder: datas,
labels_placeholder: labels
}
print ("begin training")
# 训练
for step in range(100):
_, mean_loss_val = sess.run([optimizer, mean_loss], feed_dict=feed_dict)
if step%10 == 0:
print ("step = {}\t mean loss ={}".format(step, mean_loss_val))
print ("predict")
# 预测
predicted_labels_val = sess.run(predicted_labels, feed_dict={datas_placeholder: pre})
for i, text in enumerate(pre_texts):
label = predicted_labels_val[i]
label_name = label_name_dict[label]
print ("{} => {}".format(text, label_name))
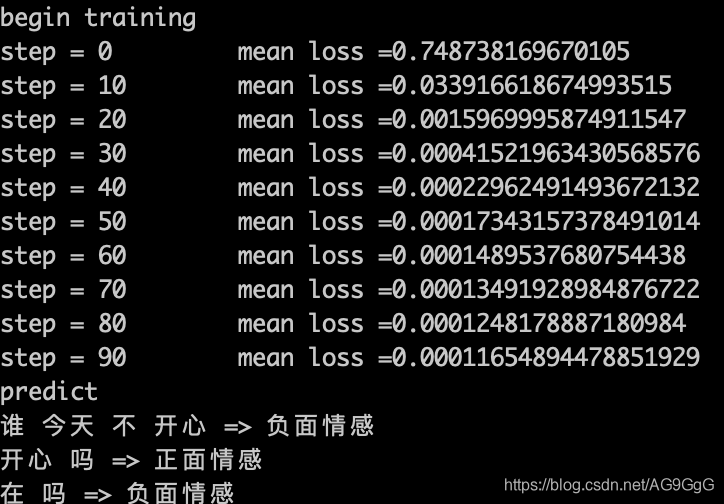
运行结果