一、需求分析
1.1 深圳大数据招聘信息分析
数据源: 智联招聘
网站: https://sou.zhaopin.com
题目: 深圳大数据招聘分析
1.2 要求
- 爬取前5页
- 将数据保存到sqlite数据库中
- 按企业性质(民营、上市公司、国企等)汇总做饼图
- 按学历汇总做柱形图
- 详情页对专业技能做词云图
- 可自由发挥分析展示其他信息
- 可以通过网页访问结果
参考步骤
数据获取
以深圳为例:在智联招聘网站上选择深圳->在搜素栏输入大数据->点击搜索
二、软件设计
表3-1 设计技术表
| 任务 | 采用的方法 |
|---|---|
| 数据的获取 | Scrapy爬虫框架,json |
| 数据的存储 | Python的sqlite轻量级关系型数据库 |
| 数据的处理 | Python的pandas库 |
| 数据的分析展示 | Python的pyecharts可视化库 |
| python服务器框 | Flask |
2.1 爬虫设计:
- 所选技术栈:
表3-2 实训爬虫技术表
| 技术 | 概念 |
|---|---|
| Scrapy | 数据的获取 |
| Json | 对Response返回的数据进行筛选 |
| SQLite | 进行数据的存储 |
- 软件框架:
简介:
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取(更确切来说,网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如:Amazon Associates Web Services) 或者通用的网络爬虫。

图3-1 scrapy工程目录树图 - 分析思路
- 明确目标
我们打算抓取https://sou.zhaopin.com/招聘网的深圳大数据行业的数据
网站里的所有职位的名称、月薪、公司名称、学历、所需工作经验、详情页要求等 - 制作爬虫,数据的筛选
我们具体分析出数据的来源,如说智联招聘是一个前后端分离的网站,通过用户点击,返回特定的json文件从而渲染网站,展示给用户。因此我们需要通过json分析特定URL返回的js文件。用键值提取关键数据;
由于详情页的数据获取需要页面的跳转,且数据是一次性渲染展示,可通过Scrapy自带的Xpath选择器提取关键数据。 - 保存数据
对数据的存储,我定义了pipelines管道,通过管道,将数据存储进轻量关系型数据库Sqlite。
-
爬取的url及字段内容等
从图3-2、图3-3中,通过谷歌浏览器分网站分析工具了解,网站与用户的交互的其大部分数据来源与一个json文件
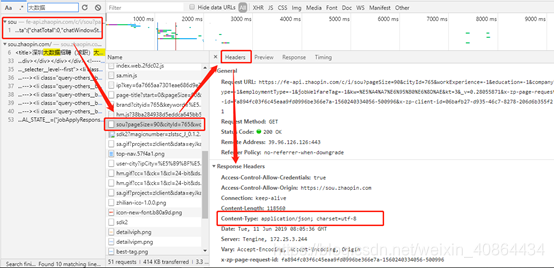
图3-2 网页数据传输图
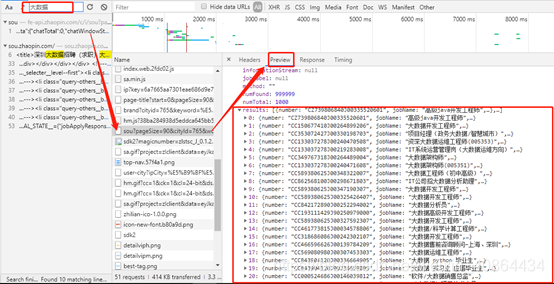
图3-3 网页返回的json文件数据图
由此可得,该URL就是目标,由于我们是要爬取多页的数据,因此我将前三页的url对比分析表3-3 前三页URL
| 页数 | url |
|---|---|
| 1 | https://fe-api.zhaopin.com/c/i/sou?pageSize=90&cityId=765&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E5%A4%A7%E6%95%B0%E6%8D%AE&kt=3&_v=0.28055871&x-zp-page-request-id=fa894fc03f6c45eaa9fd0996be366e7a-1560240334056-500996&x-zp-client-id=06bafb27-d935-46c7-8278-206d6b355f21 |
| 2 | https://fe-api.zhaopin.com/c/i/sou?start=90&pageSize=90&cityId=765&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E5%A4%A7%E6%95%B0%E6%8D%AE&kt=3&_v=0.28055871&x-zp-page-request-id=fa894fc03f6c45eaa9fd0996be366e7a-1560240334056-500996&x-zp-client-id=06bafb27-d935-46c7-8278-206d6b355f21 |
| 3 | https://fe-api.zhaopin.com/c/i/sou?start=180&pageSize=90&cityId=765&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E5%A4%A7%E6%95%B0%E6%8D%AE&kt=3&_v=0.28055871&x-zp-page-request-id=fa894fc03f6c45eaa9fd0996be366e7a-1560240334056-500996&x-zp-client-id=06bafb27-d935-46c7-8278-206d6b355f21 |
表中可得,从第二页开始URL的变化就在start=90、180,每一页都递增数为90
总结得出,变换start的数值可得到不同的页面。
2.2 数据存取:数据表设计、相关SQL语句等
1.数据表的设计
表3-4 数据表字段的设计
| 字段 | 标题 | 公司 | 公司类型 | 薪酬 | 经验 | 学历 |
|---|---|---|---|---|---|---|
| 类型 | varchar | varchar | varchar | varchar | varchar | varchar |
| 字段 | 详细链接 | 工作地址 | 福利 | 技能 | 要求 | |
| 类型 | varchar | varchar | varchar | varchar | varchar |
2.相关SQL语句
insert_sql = 'insert into bigDataZL values' \
' ("{}","{}", "{}","{}","{}", "{}","{}","{}", "{}","{}","{}")'.format(
item['title'],item['company'],item['company_type'],
item['salary'],item['experience'],item['education'],
item['detail_url'],item['address'],item['welfare'],
item['skill'],item['claim']
)
createSql = "create table bigDataZL(" \
"标题 varchar(100)," \
"公司 varchar(100)," \
"公司类型 varchar(100)," \
"薪酬 varchar(100)," \
"经验 varchar(100)," \
"学历 varchar(100)," \
"详细链接 varchar(100) primary key ," \
"工作地址 varchar(100)," \
"福利 varchar(100)," \
"技能 varchar(100)," \
"要求 varchar(100))"
2.3 数据分析:数据处理流程等
查重处理:以详情链接字段为主键。
数据的读取:pandas读取数据表转为DataFrame数据类型
-
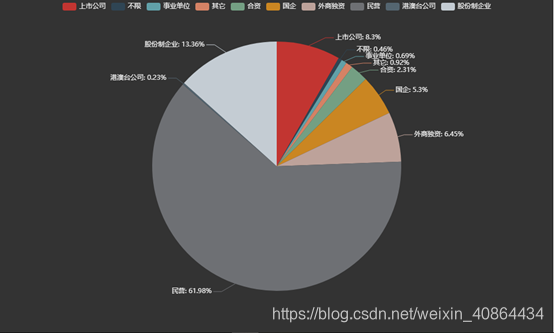
企业性质汇总数据分析
按企业性质分组统计,得到企业性质的统计值 -
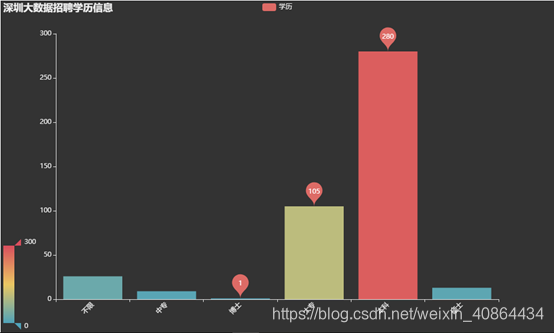
学历汇总数据分析
按学历分组统计,得到学历的统计值 -
详情页对专业技能做词云图数据分析
详细页的岗位要求需要我们对关键字的提取,其中不乏一些无用信息,也需要我们剔除掉,如图3-6:
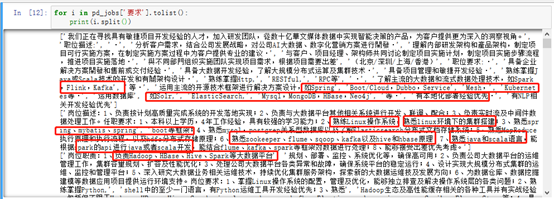
图3-7的处理,首先为定义一个专业词库列表,并且让每一条数据都只提取不重复的关键字,且定义键为单词,值为1的字典存进列表中,再将列表转为Pandas的DataFrame类型统计单词出现的频率 -
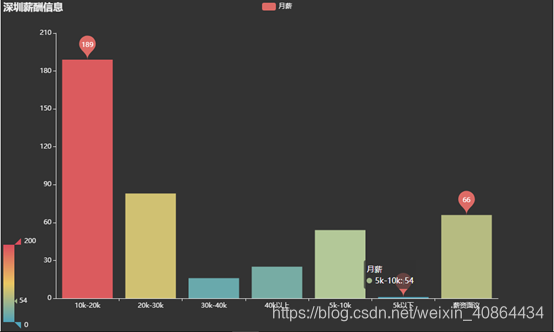
薪酬汇总做数据分析
为了更好地进行分析,我们要对薪资做一个预处理。由于其分布比较散乱,很多值的个数只有1。为了不造成过大的误差,根据其分布情况,可以将它分成【5k 以下、5k-10k、10k-20k、20k-30k、30k-40k、40k 以上】,为了更加方便我们分析,取每个薪资范围的中位数,并划分到我们指定的范围内。 -
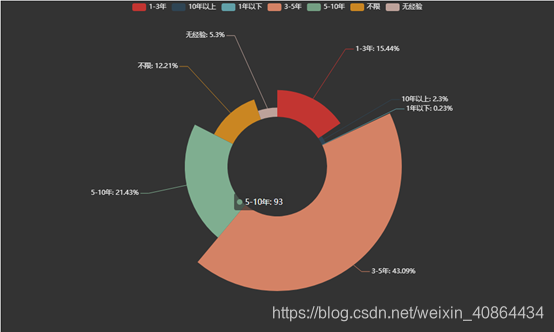
所需经验数据分析
按学历列分组统计,得到学历的统计值
2.5 结果展示:所选择的Web框架、网页展示的方案设计等
- 选择的Web框架:
Flask是一个使用Python编写的轻量级 Web 应用框架。其WSGI工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 Flask使用 BSD 授权。
Flask也被称为“microframework”,因为它使用简单的核心,用 extension 增加其他功能。Flask没有默认使用的数据库、窗体验证工具。 - 网页展示的方案设计
通过用户点击从而展示不同的分析内容,如图
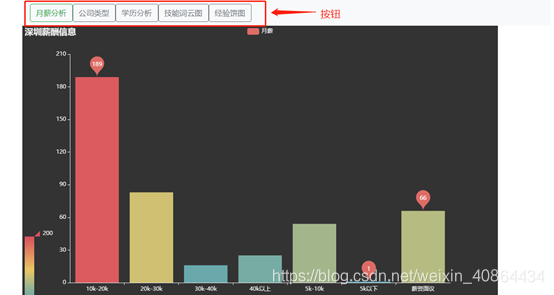
三、测试报告
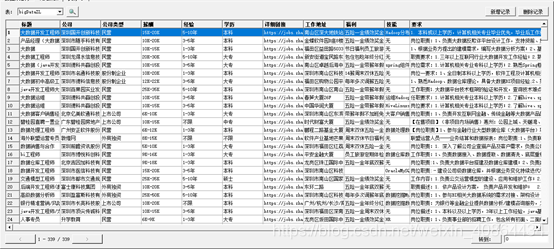
3.1数据采集

3.2可视化图表