本项目以电影数据为主题,以数据采集、处理、分析及数据可视化为项目流程,可实现百万级电影数据离线处理与计算。
项目链接: https://github.com/GoAlers/Bigdata-movie
开发环境:IDEA+Pycharm+Centos7.0+hadoop2.8+hive2.3.0+hbase2.0.0+mysql5.7+sqoop
- 1. 负责Hadoop大数据平台安装部署和基本配置、参数优化以及相关组件部署与管理。
- 2. 搭建分布式大数据平台,负责爬虫采集海量电影数据及数据清洗,制作词图云、matplotlib图表及Echarts数据可视化。
- 3. 利用Python/Java编写MR编程离线计算特定电影统计;利用sqoop工具传输数据,运用hive进行相关数据分析。
- 4. 运用机器学习算法及相关库实现电影评论情感分析及预测用户评分范围及票房,统计总分topN。
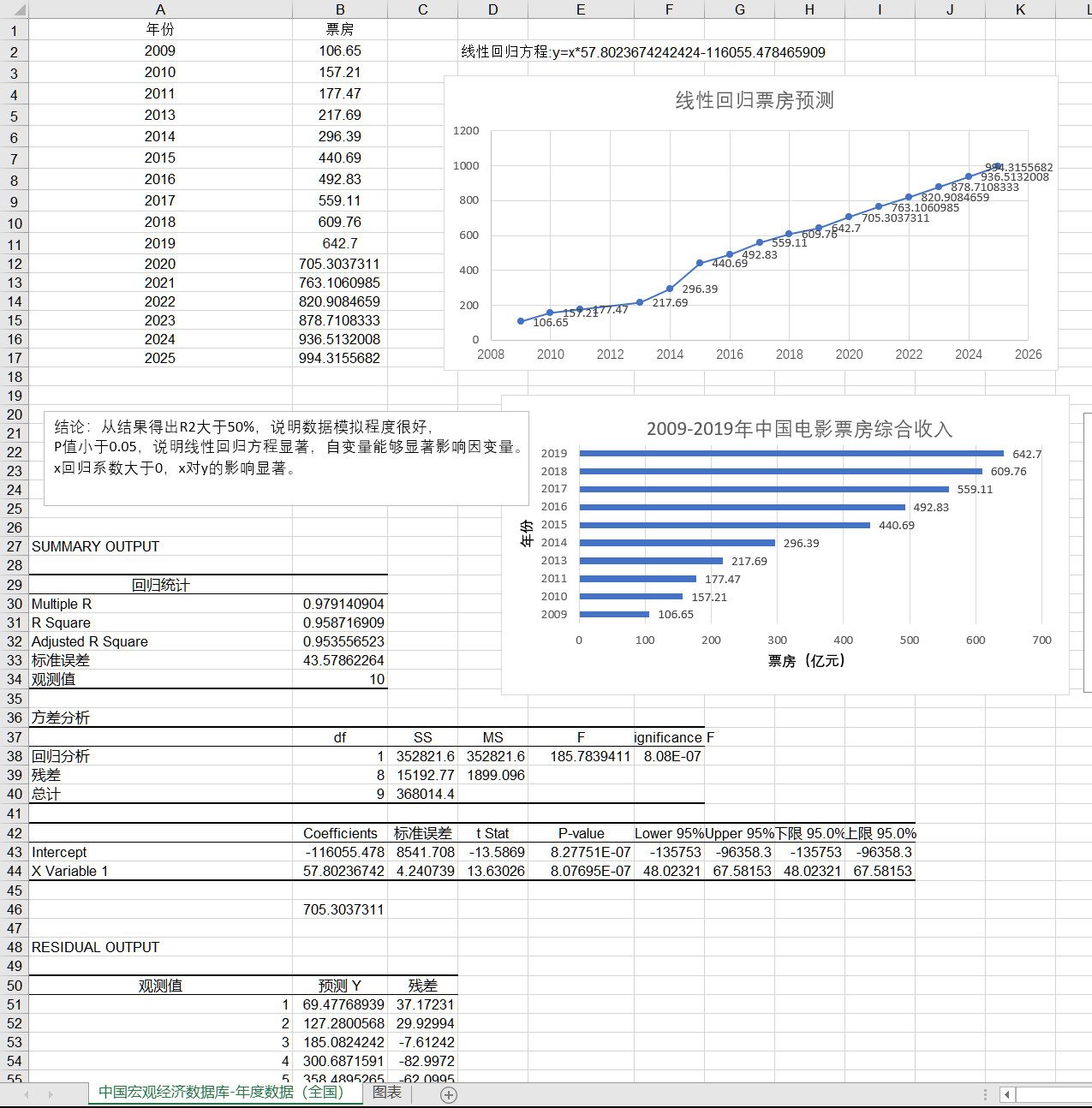
1.数据采集(pachong.py)、清洗:采集豆瓣电影数据,抓取电影票房总收入排名情况(取前20),删除冗余和空值字,利用Python的PyMysql库连接本地Mysql数据库并导入movies表,可以将数据保存到本地,从而进行数据可视化展示,也可将数据导入到大数据的Hive数仓工具中,用于大数据分析。
| 排序 | 影片名称 | 类型 | 总票房(万) | 场均人次 | 上映日期 |
| 1 | 战狼2 | 动作 | 567928 | 38 | 2017/7/27 |
| 2 | 哪吒之魔童降世 | 动画 | 501324 | 24 | 2019/7/26 |
| 3 | 流浪地球 | 科幻 | 468433 | 29 | 2019/2/5 |
| 4 | 复仇者联盟4:终局之战 | 动作 | 425024 | 23 | 2019/4/24 |
| 5 | 红海行动 | 动作 | 365079 | 33 | 2018/2/16 |
| 6 | 唐人街探案2 | 喜剧 | 339769 | 39 | 2018/2/16 |
| 7 | 美人鱼 | 喜剧 | 339211 | 44 | 2016/2/8 |
| 8 | 我和我的祖国 | 剧情 | 317152 | 36 | 2019/9/30 |
| 9 | 我不是药神 | 剧情 | 309996 | 27 | 2018/7/5 |
| 10 | 中国机长 | 剧情 | 291229 | 27 | 2019/9/30 |
2.数据可视化:数据可视化能使数据更加直观,更有利于分析,可以说可视化技术是数据分析与挖掘最重要的内容。Matplotlib作为基于Python语言的开源项目,旨在为Python提供一个数据绘图包,实现专业丰富的绘图功能。
(1)电影票房排名
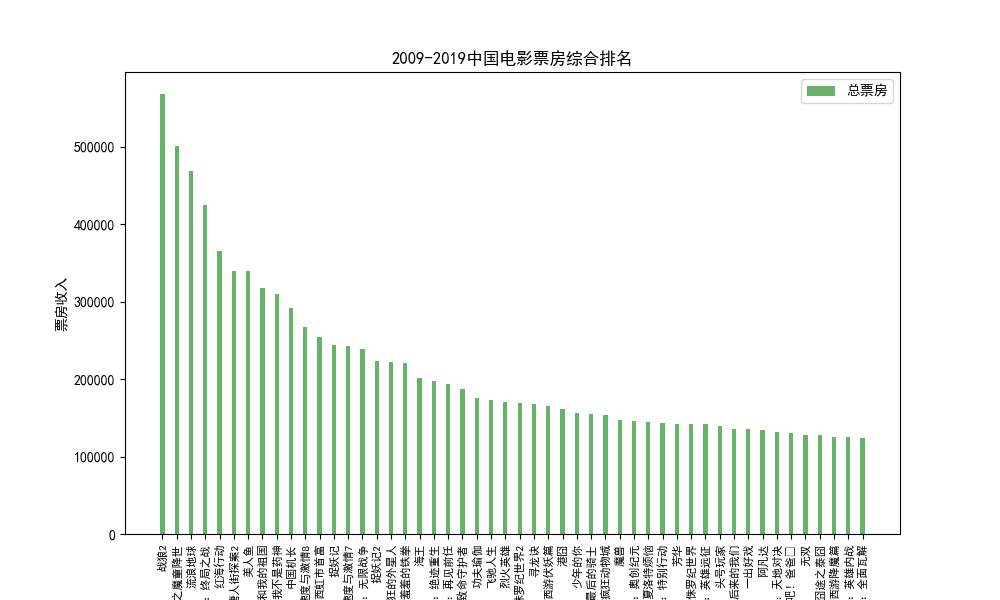
(2)电影评分排名douanscore.py
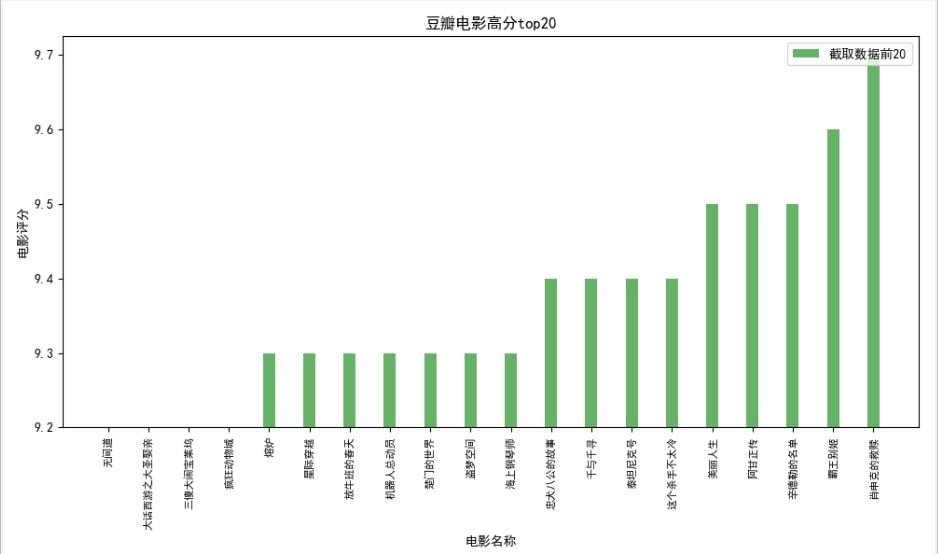
(3)Echarts最近上映电影
Echarts 主要用于数据可视化展示,是一个开源的JavaScript库,兼容现有绝大部分浏览器。在Python中,Echarts被包装成数据可视化工具库Pyecharts。它提供直观、丰富、可个性化定制的数据可视化图表,包括常规的折线图、柱状图、散点图、饼图等。

(4)影片《囧妈》短评信息
大年初一电影《囧妈》网络首映映,截止目前其豆瓣电影评分6.0分,通过电影《囧妈》的豆瓣热门短评进行案例分析,以八爪鱼软件为数据采集工具进行数据爬虫,采集字段有用户名、评级、点赞数和评论内容等信息,利用正则表达式匹配字段标签,根据豆瓣电影提供的评级星数系统显示力荐、推荐、还行、较差、很差等五个评级,满分为五星,数据格式如下:
(7)python词频统计wordcount.py
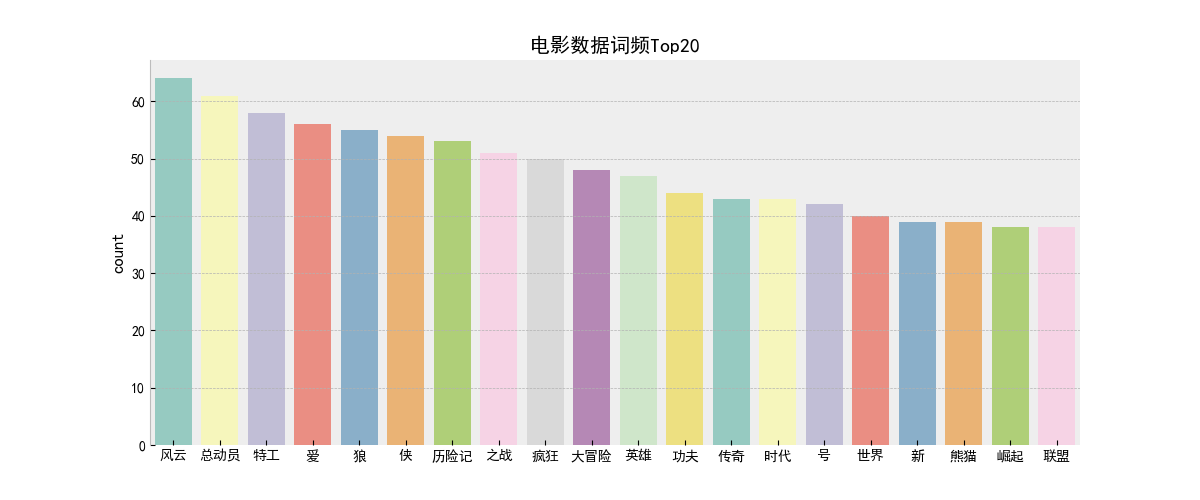
3.大数据分析:
大数据处理最重要的环节就是数据分析,数据分析通常分为两种:批处理和流处理。批处理是对一段时间内海量的离线数据进行统一处理,对应的处理框架Mapreduce、Spark等;流处理则是针对动态实时的数据处理,即在接收数据的同时就对其进行处理,对应的处理框架有 Storm、Spark Streaming、Flink等。本文以离线计算为主,介绍电影数据分析。
(1)Mapreduce离线计算(mapreduce_hive文件)
Mapreduce编程词频统计主要利用wordcount思想,通过按规定格式分割词句,实现单词统计词频。其统计数据为历史电影的上映信息,map阶段主要负责单词分割统计,map阶段把每个字符串映射成键、值对,按行将单词映射成(单词,1)形式,Shuffle过程会对map的结果进行分区排序,然后按照同一分区的输出合并在一起写入到磁盘中,最终得到一个分区有序的文件,最后reduce阶段会汇总统计出每个词对应个数,数据最终会存储在HDFS上。本文以电影词作为统计对象,实现单词统计词频功能。词频统计流程图如下:
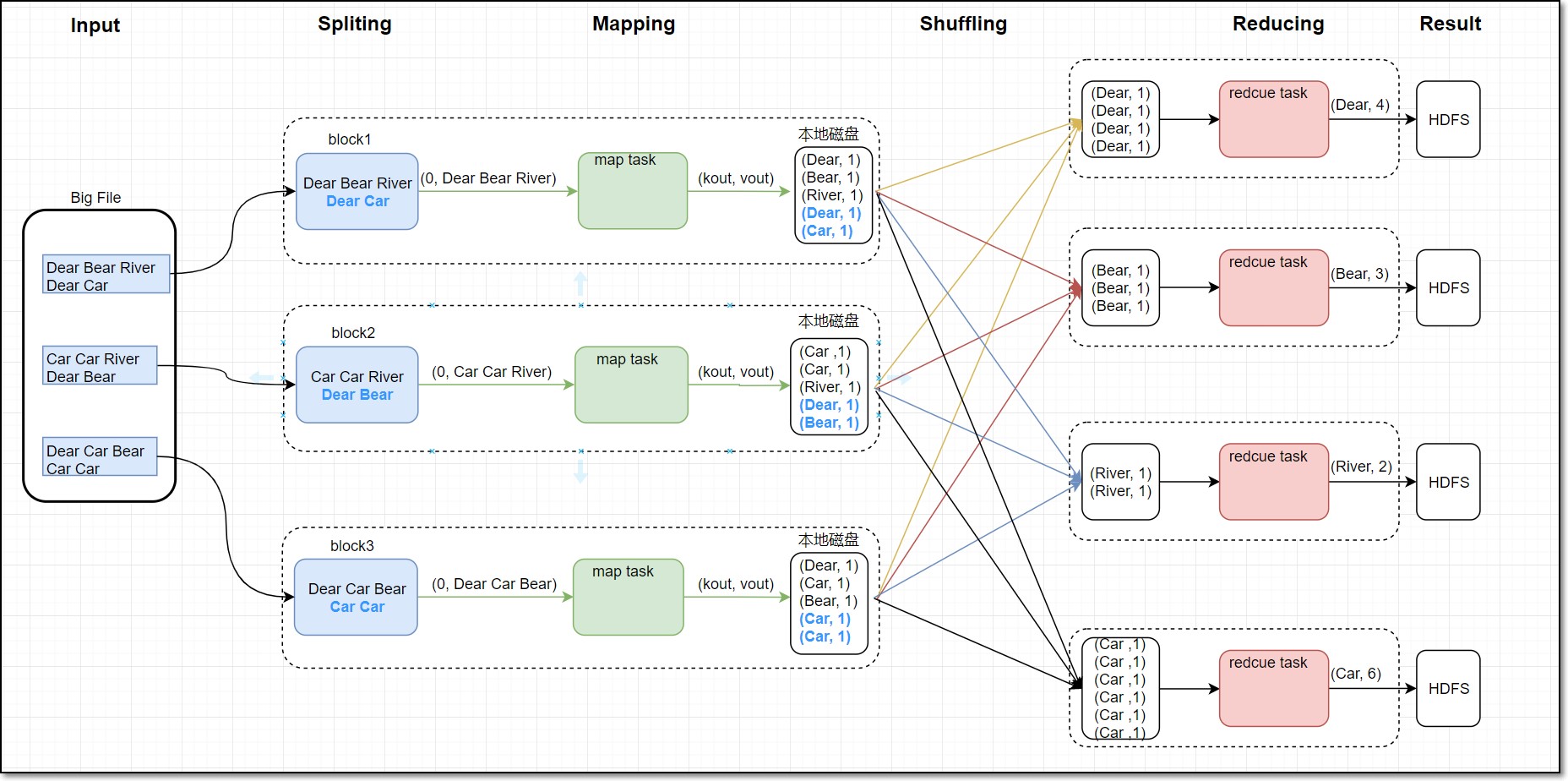
Map阶段代码:
import sys
for line in sys.stdin:
ss = line.strip().split(' ')
for s in ss:
if s.strip() != "":
print "%s\t%s" % (s, 1)
Reduce阶段代码:
import sys
current_word = None
count_pool = []
sum = 0
for line in sys.stdin:
word, val = line.strip().split('\t')
if current_word == None:
current_word = word
if current_word != word:
for count in count_pool:
sum += count
print "%s\t%s" % (current_word, sum)
current_word = word
count_pool = []
sum = 0
count_pool.append(int(val))
for count in count_pool:
sum += count
print "%s\t%s" % (current_word, str(sum))
(2)Hive数据仓库
Hive是一个基于Hadoop的数据仓库工具,主要用于解决海量结构化日志的数据统计,可以将结构化的数据文件映射成一张表,通过类SQL语句的方式对表内数据进行查询、统计分析。利用Sqoop数据传输工具可以将Mysql数据库信息导入到Hive数仓。
运用Hive可以实现海量数据分析,并且支持自定义函数,省去MapReduce编程。本文针对历史豆瓣电影数据进行统计,数据经过清洗,删除空值、多余项,得到大约100000多条电影数据,部分数据格式如下:
(3)影片类型与票房统计图movietype.py
(5)导演与影片类型关系图director.py
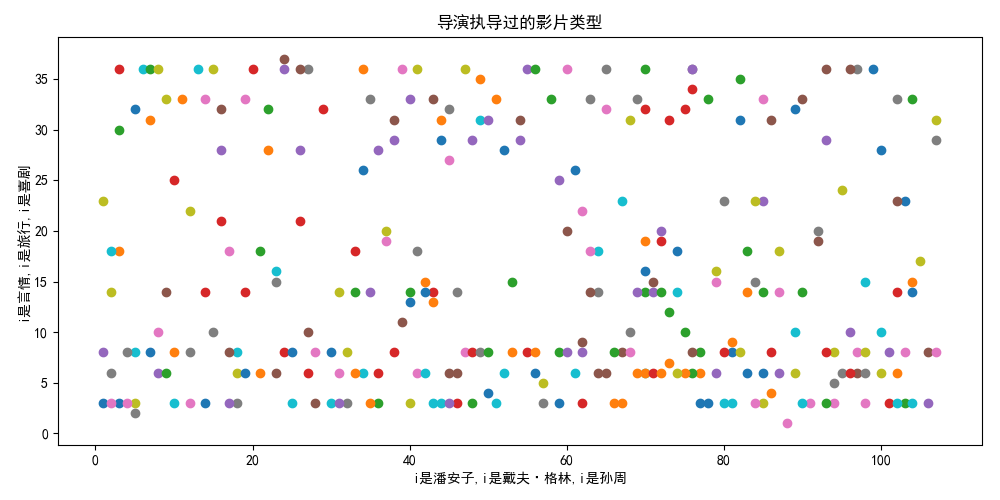
(6)电影票房预测(电票票房预测.xls)
(7)电影评分预测scorepredict.py
利用机器学习sklearn库建立回归模型,随机取5个用户计算评分预测出用户对于某新影片的评分范围,输出评分最大、最小、平均值。
#encoding:utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
from sklearn.linear_model import LinearRegression
#绘图部分
data = pd.read_csv('lianxi/film-csv.txt',encoding = 'utf-8',delimiter = ';') #读取文件
data = data.iloc[:,:-1] #去除文件中的非法数据
data = data.drop(0).drop_duplicates().reset_index().drop('index',axis = 1) #由于第一行为空数据 去除 并去重 重置索引
# print data
t = [] #将电影类型按多种分割符切分
for i in range(len(data)):
a = re.split(u' / |/|,|、| | ',data[u'影片类型'][i])
for j in a:
t.append(j)
t = set(t) #将重复的类型去掉
tt = []
for i in t: #将不规范的类型去除 得出所有存在的类型
if (len(i)<=2)|(i==u'合家欢'):
tt.append(i)
#评分预测
id = [1050,1114,1048,1488,1102] #五个用户id
data1 = pd.read_csv('lianxi/score.log',delimiter=',',encoding = 'utf-8',header=0,names = [u'电影名称',u'userid',u'score'])
data1 = data1[data1[u'userid'].isin(id)] #去除五个用户 相关数据
data1[u'电影名称'] = data1[u'电影名称'].str.strip() #去除电影名称的空格
all = []#用来存预测结果
for k in range(len(id)): #循环五次 建模 进行预测
dfp1 = data1[data1[u'userid']==id[k]].reset_index().drop('index',axis = 1)
datamerge = pd.merge(data,dfp1,on=u'电影名称') #用merge 将电影详细信息 与新用户评分合并
lst = []
lsd = []
lsr = []
for i in range(len(datamerge)): #切分出电影类型 和导演 以及对应的票房
for j in tt:
if j in datamerge[u'影片类型'][i]:
d = re.split(u',|、|/| ',datamerge[u'导演'][i])
for k in d:
lsd.append(k.replace(u' ', u''))
lst.append(j.replace(u' ', u''))
lsr.append(datamerge[u'score'][i])
lsd1 = list(set(lsd))
for i in range(len(lsd1)): #将电影类型和票房转成 连续量 以便机器训练
for j in range(len(lsd)):
if lsd1[i] == lsd[j]:
lsd[j] = i + 1
for i in range(len(tt)):
for j in range(len(lst)):
if tt[i] == lst[j]:
lst[j] = i + 1
lsd = pd.DataFrame(lsd, columns=[u'导演'])
lst = pd.DataFrame(lst, columns=[u'影片类型'])
lsr = pd.DataFrame(lsr, columns=[u'评分'])
a = pd.concat([lsd, lst, lsr], axis=1)
print(a)
trainx = a.iloc[:, 0:2] # 电影类型和 导演 作为特征量
trainy = a.iloc[:, 2:3] # 评分作为样本值
l = LinearRegression() # 建模
l.fit(trainx, trainy) # 训练
anstest = pd.DataFrame([[5,10]],columns=[u'导演',u'影片类型'])
ans = l.predict(anstest)#预测
all.append(ans[0][0]) #得出结果
print (u'评分最大值是'+'%.2f'%max(all)) #输出
print (u'评分最小值是'+'%.2f'%min(all))
print (u'评分中位数值是'+'%.2f'%np.median(all))
print (u'评分平均值是'+'%.2f'%np.mean(all))