作者主页:编程千纸鹤
作者简介:Java、前端、Python开发多年,做过高程,项目经理,架构师
主要内容:Java项目开发、Python项目开发、大学数据和AI项目开发、单片机项目设计、面试技术整理、最新技术分享
收藏点赞不迷路 关注作者有好处
文末获得源码
项目编号:BS-Python-012
一,环境介绍
语言环境:Python3.7
数据库:Mysql: mysql5.7
开发工具:IDEA或PyCharm
使用技术:Python+Flask+Echart+BeautifulSoup
二,项目简介
本项目基于爬虫实现对51JOB网站的爬取,并将数据存入MYSQL数据库。利用Flask开发WEB应用程序,读取MYSQL数据进行分析,利用Echart进行数据分析展示。
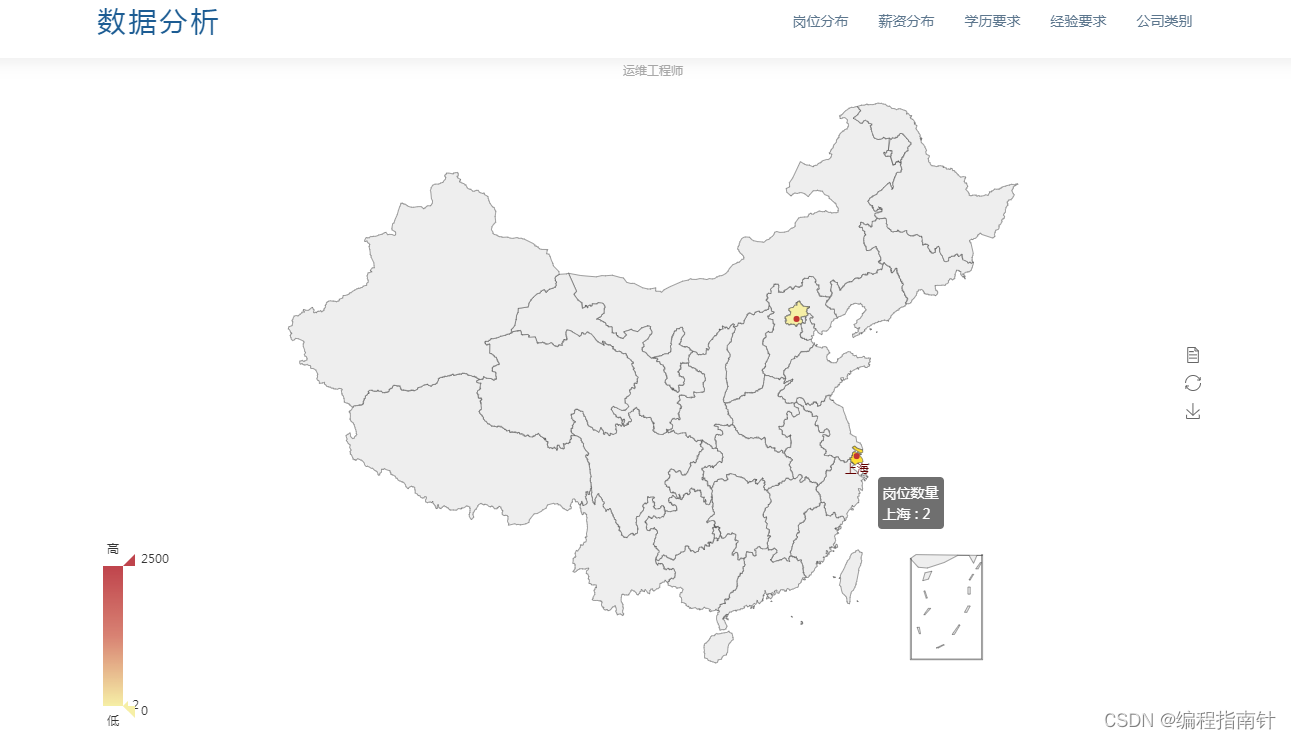
三,系统展示

岗位分布
薪资分布

学历分布

经验要求

公司类型

四,核心代码展示
from bs4 import BeautifulSoup # 导入beautifulsoup库
import re # 导入re库以使用正则表达式
import urllib.request, urllib.error
from urllib import parse
from clean_Data import CleanData
import time
class CrawlingData:
# 第page页的岗位列表
def get_jobPage(self, key, page):
try:
# 定义爬取岗位的第一页url
#url = "https://search.51job.com/list/000000,000000,0000,00,9,99," + key + ',2,' + str(page) + '.html'
#url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,数据分析,2,{page}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='
url = "https://search.51job.com/list/000000,000000,0000,00,9,99," + key + ",2,{}.html" # 需要获取的url
# 伪装header头,以防止网站禁止爬取,这里使用的是火狐浏览器的请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0"
}
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
# 'Cookie': 'guid = f717c64de9a2d88a5cb25651fa2469d1;nsearch = jobarea % 3D % 26 % 7C % 26ord_field % 3D % 26 % 7C % 26recentSearch0 % 3D % 26 % 7C % 26recentSearch1 % 3D % 26 % 7C % 26recentSearch2 % 3D % 26 % 7C % 26recentSearch3 % 3D % 26 % 7C % 26recentSearch4 % 3D % 26 % 7C % 26collapse_expansion % 3D;search = jobarea % 7E % 60000000 % 7C % 21ord_field % 7E % 600 % 7C % 21recentSearch0 % 7E % 60000000 % A1 % FB % A1 % FA000000 % A1 % FB % A1 % FA0000 % A1 % FB % A1 % FA00 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA9 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA % A1 % FB % A1 % FA0 % A1 % FB % A1 % FApython % A1 % FB % A1 % FA2 % A1 % FB % A1 % FA1 % 7C % 21recentSearch1 % 7E % 60000000 % A1 % FB % A1 % FA000000 % A1 % FB % A1 % FA0000 % A1 % FB % A1 % FA00 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA9 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA % A1 % FB % A1 % FA0 % A1 % FB % A1 % FAjava % A1 % FB % A1 % FA2 % A1 % FB % A1 % FA1 % 7C % 21recentSearch2 % 7E % 60000000 % A1 % FB % A1 % FA000000 % A1 % FB % A1 % FA0000 % A1 % FB % A1 % FA00 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA9 % A1 % FB % A1 % FA99 % A1 % FB % A1 % FA % A1 % FB % A1 % FA0 % A1 % FB % A1 % FAPython % A1 % FB % A1 % FA2 % A1 % FB % A1 % FA1 % 7C % 21;ssxmod_itna = QqfxRDyD9iqDqY5DtDXDnD + h + OB58xuA7q28qGNQ43DZDiqAPGhDC + 39bRhR02GGqoYiPC0Ix3WG8heaoHfDRb5ABOG4GLDmKDyKGZeGGfxBYDQxAYDGDDPDocPD1D3qDkD7O1lS9kqi3DbO = Di4D + FLQDmqG0DDUH94G2D7UcW0vcQCdPETbgK0iQ07 = DjwbD / +DW17 = 5T1a5nu0i5 = iW3qGyRPGujwUZSbbDC2 = / Ud0zjDPqtgf3YBoQmD4dCYETR0weW0SLCi5pK4qe9G4zn0xDG4q5nDLxeD;ssxmod_itna2 = QqfxRDyD9iqDqY5DtDXDnD + h + OB58xuA7q24A6TQYQD / YCjDFOniFr2rf1aKAPQYmhOvxQVlQWrdqtizQYuxYoAmv4mtg0MANhr2SL8WkD69P34zRCti6TukvKsghsU59Gok8dNSe + cC8vVmhDxXx2qdCr / 8nEqvSA5Tjid9uoVBT64omNN1RGpnRiPyuK3aLfE + mIbpQ2E7pdOIgbjjEUhf6PhipvOIcybp0cd5zrjIgiYC12936gs20okO4c3NRId2BAOPE9bxVyrmrAPZFC6aHIOkSK2qp7HZTApMcOlNSRf / 6VBu5jtnQ / cWlHBtn7 + aM + IhzP4sxqg5q5YZ8xFCyD0aaQ2plh = Kmq8hOGnY2G42G5 = iaIrWlhKycFlhP0b8Kox0 + FWwNW0WnRbD + qGu79Eef4i8IQaiuD4rXEiD += CEPt8yKRt = DTLgtE91j4oX8dGumeEO / AbtxDKuAUEPN0C4pK2iKja = qBYYYU = OKbixD7 = DYIYwhqzDHRhDD == =;adv = ad_logid_url % 3Dhttps % 253A % 252F % 252Ftrace.51job.com % 252Ftrace.php % 253Fpartner % 253Dsem_pc360s1_29369 % 2526ajp % 253DaHR0cHM6Ly9ta3QuNTFqb2IuY29tL3RnL3NlbS9MUF8yMDIwXzEuaHRtbD9mcm9tPTM2MGFk % 2526k % 253D7d16490a53bc7f778963fbe04432456c % 2526qhclickid % 253Dd9d672a3cdb12ead % 26 % 7C % 26;partner = cn_bing_com;privacy = 1651475693'
# }
# 发送获取页面的请求
req = urllib.request.Request(url, headers=header)
html = ""
response = urllib.request.urlopen(req, timeout=10)
html = response.read().decode("utf-8")
response.close()
time.sleep(0.5)
return html
except:
print('爬取失败')
# 获取该岗位有的页数
def get_allPages(self, html):
try:
bs = BeautifulSoup(html, "html.parser")
a_text = bs.select(".td")[0].get_text()
pages = re.findall(r"\d+", a_text)
pages = int(pages[0])
return pages
except:
print("error")
# 获取岗位详情页links
def get_links(self, html, pages):
try:
bs = BeautifulSoup(html, "html.parser")
a_href = bs.select(".el > .t1 > span > a")
link = []
for i in a_href:
link.append(i.get("href"))
return link
except:
print('error')
# 爬取详情页信息
def get_jobInfo(slef, link):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0"
}
errors = 0
# 创建cleanData对象
cle = CleanData()
try:
req = urllib.request.Request(link, headers=header)
html = ""
response = urllib.request.urlopen(req, timeout=10)
html = response.read().decode("gbk")
bs = BeautifulSoup(html, "html.parser")
# 数据列表
data = []
# 获取岗位名称
job_name = bs.select("h1")[0].get_text()
job_name = cle.clean_job(job_name)
data.append(job_name)
# 获取薪资
salary = bs.select("h1 ~ strong")[0].get_text()
# 清洗工资数据,统一格式千/月,为空和面议的,默认为0.0代表面议,或不封顶,
sals = cle.clean_salary(salary)
# 获取最低工资并填充到data
low_salary = sals[0]
data.append(low_salary)
# 获取最高工资
high_salary = sals[1]
data.append(high_salary)
# 获取公司名
company = bs.select(".catn")[0].get_text()
# 去除公司名的中英括号
company = cle.clean_company(company)
data.append(company)
# 获取信息
msg = bs.select(".msg")[0].get_text()
# 获取地区
area = msg.split("|")[0].strip()
# 清理地址的区
area = cle.clean_area(area)
data.append(area)
# 获取经验
experience = msg.split("|")[1].strip()
# 清理经验格式与薪水类似,分为最低经验和最高经验
exp = cle.clean_experience(experience)
# 最低经验
data.append(exp[0])
# 最高经验
data.append(exp[1])
# 获取学历
education = msg.split("|")[2].strip()
# 清理学历
education = cle.clean_education(education)
data.append(education)
# 获取公司类型
comp_type = bs.select(".at")[0].get_text()
data.append(comp_type)
# 获取公司规模(人数)
comp_size = bs.select(".at")[1].get_text()
data.append(comp_size)
# 获取职位信息
job_infos = bs.select(".job_msg,.job_msg > ol > li > p > span,.job_msg > p")
job_info = ""
for i in job_infos:
job_info += i.get_text().strip()
job_info = "".join(job_info.split())
data.append(job_info)
response.close()
time.sleep(0.5)
print(data)
return data
except:
print("爬取异常,跳过爬取")
print("爬取失败链接:%s" % link)
五,相关作品展示
基于Java开发、Python开发、PHP开发、C#开发等相关语言开发的实战项目
基于Nodejs、Vue等前端技术开发的前端实战项目
基于微信小程序和安卓APP应用开发的相关作品
基于51单片机等嵌入式物联网开发应用
基于各类算法实现的AI智能应用
基于大数据实现的各类数据管理和推荐系统







