核心问题
发现数字的隐藏规律,完成分类。
核心技能
- 最大似然估计
给定一个概率分布 ,已知其概率密度函数(连续分布)或概率质量函数(离散分布)为
,以及一个分布参数
,我们可以从这个分布中抽出一个具有
个值的采样
利用
计算出其似然函数:
若 是离散分布,
即是在参数为
时观测到这一采样的概率。若其是连续分布,
则为
联合分布的概率密度函数在观测值处的取值。一旦我们获得
我们就能求得一个关于
的估计。最大似然估计会寻找关于
的最可能值(即,在所有可能的
取值中,寻找一个值使这个采样的“可能性”最大化)。从数学上来说,我们可以在
的所有可能取值中寻找一个值使得似然函数取到最大值。这个使可能性最大的
值即成为
的最大似然估计。
⚠️注意:1)这里的似然函数是指 不变时,关于
的一个函数。
2)最大似然估计不一定存在,也不一定唯一。
- 贝叶斯模型
首先复习一下贝叶斯定理:贝叶斯定理是关于随机事件 A 和 B 的条件概率的一则定理。
其中 P(A|B) 是在 B 发生的情况下 A 发生的可能性。

在贝叶斯定理中,每个名次都有约定俗成的名称:
- P(A|B) 是已知 B 发生后 A 的条件概率,也由于得自 B 的取值而被称作 A 的后验概率。
- P(A) 是 A 的先验概率,之所以称为“先验“是因为它不考虑任何 B 方面的因素。
- P(B|A) 是已知 A 发生后 B 的条件概率,也由于得自 A 的取值而被称作 B 的后验概率。
- P(B) 是 B 的先验概率。
按这些术语,贝叶斯定理也可以表述为:
后验概率 = (相似度*先验概率)/标准化常量
也就是说,后验概率与先验概率和相似度的乘积成正比。
关于朴素贝叶斯算法的具体应用,看到一篇文章讲得很详细,点击这里传送~
- 高斯分布
高斯分布(Gaussian Distribution), 也叫自然分布或正态分布。

若随机变量 X 服从一个数学期望为 、标准方差为
的高斯分布,记为:
则其概率密度函数为:
高斯分布的期望值 决定了其位置,其标准差
决定了分布的幅度。我们通常提到的标准正态分布是
的正态分布。
关于多元高斯分布在机器学习中的应用,具体可以参考这篇文章:多元高斯分布(Multivariate Gaussian Distribution)
- EM算法
EM算法,即最大希望算法(Expectation-maximization algorithm)。在统计计算中,EM算法是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐性变量。最大期望算法经常用在机器学习和计算机视觉的数据聚类(Data Clustering)领域。
EM算法经过两个步骤交替进行计算,第一步是计算期望(E),利用对隐藏变量的现有估计值,计算其最大似然估计值;第二步是最大化(M),最大化在E步上求得的最大似然值来计算参数的值。M步上找到的参数估计值被用于下一个E步计算中,这个过程不断交替进行。
- 蒙特卡洛
蒙特卡罗是一类随机方法的统称。这类方法的思想可以参考一个例子,用蒙特卡洛法求圆周率:
已知:一个半径为R的圆,它有一个边长为2R的外切正方形。
圆面积:pi*R^2,正方形面积:2R*2R=4R^2
在正方形内随机取一个点,要求每次取的点在正方形内任意一个点位置的概率都是平均分布的,那么这个点在圆内的概率大概为:pi*R^2/4R^2=pi/4
取若干个这样的点,利用平面上两点间的距离公式,计算这个点到圆心的距离,从而判断是否在圆内。
当我们统计过的点的个数足够多时,得到的概率值就会接近 pi/4,从而得到圆周率的值。
蒙特卡洛是依靠足够多次数的随机模拟,来得到近似结果的算法,说白了就是通过频率来估计概率。
- 时间序列
时间序列(time series)是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。
 BTC 价格走势
BTC 价格走势
判断模型
- 检验/降低过拟合
首先明确一下什么是拟合度检验:拟合度检验是对已制作好的预测模型进行检验,比较它们的预测结果与实际发生情况的吻合程度。通常是对数个预测模型同时进行检验,选其拟合度较好的进行试用。常用的拟合度检验方法有:剩余平方和检验、卡方(c2)检验和线性回归检验等。
什么是过拟合:在机器学习的过程中,经常会出现拟合度不合适的问题。但一开始我们的模型往往是欠拟合的,因此才有优化的空间,我们需要不断调整算法来使模型的学习能力越来越强。但同时,优化到了一定程度还会出现过拟合的问题。
通俗地说,过拟合就是模型把数据学习得太全面彻底,以至于把噪声数据的特征也学习到了,这样就会导致在测试阶段不能很好地识别数据,即不能正确地分类或预测,模型的泛化能力差。

绿线代表过拟合模型,黑线代表正则化模型(防止过拟合而引入罚函数的模型)。虽然绿线完美符合训练数据,但太过依赖,并且与黑线相比,对于新的测试数据具有更高的错误率。
- 绘制ROC/计算AUC
ROC(Receiver Operating Characteristic)曲线和 AUC(Area Under Curve)常被用来评价一个二值分类器(Binary Classifier)的优劣。
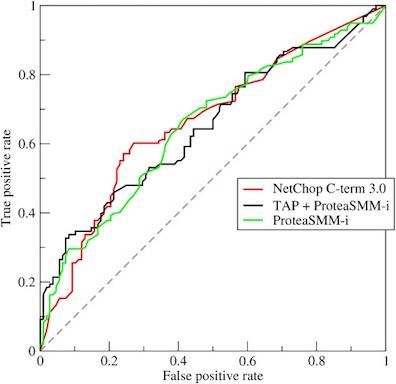
AUC 被定义为 ROC 曲线下的面积,显然这个面积不会大于1。ROC 曲线上的任意相邻两点与横轴都能形成梯形,把所有这样的梯形面积相加即可得到 AUC。一般而言,训练样本越多,在得到样本判别为正例的分数取值后不同分数也相对会越多,这样 ROC 曲线上的点也就越多,估算的 AUC 会更准确。这种思路类似微积分中的微分法。
AUC 的含义:AUC 值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的 Score 值将这个正样本排在负样本前面的概率就是 AUC 值。AUC 值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。另外,AUC 与 Gini 分数有联系,Gini + 1 = 2*AUC。
通过概率统计方法来算 AUC:做 N 次随机试验,每次实验中随机采样一个正样本和一个负样本,当模型预测正样本的分数大于模型预测负样本的分数,计数则加1。记计数最终为 n(n肯定小于等于N),那么用 n/N 即得到 AUC。
- 显著性检验
显著性检验就是事先对总体(随机变量)的参数或总体分布形式做出一个假设,然后利用样本信息来判断这个假设(原假设)是否合理,即判断总体的真实情况与原假设是否显著地有差异。或者说,显著性检验要判断样本与我们对总体所做的假设之间的差异是纯属机会变异,还是由我们所做的假设与总体真实情况之间不一致所引起的。
P 值即概率,反映某一事件发生的可能性大小。统计学根据显著性检验方法所得到的 P 值,一般以 P < 0.05 为显著, P<0.01 为非常显著,其含义是样本间的差异由抽样误差所致的概率小于0.05 或0.01。
