M-P神经元模型
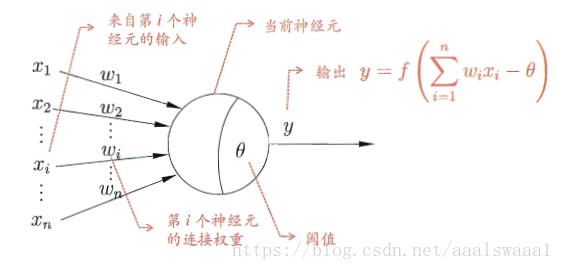
上图表达了模型的思想,就是将输入信号通过带权重的连接传入神经元中,再经过激活函数,然后输出结果。
激活函数可以用符号函数,或者对数几率函数。
感知机与神经网络
感知机由两层神经元组成,而M-P模型就是它的输出层,显然感知机只有输出层有激活函数处理,可以认为只有一层是计算了的,输入层只是将数据输入,因此它的能力非常有限,无法解决异或问题。想解决非线性可分问题就要使用多层功能神经元,这就引入了常见的神经网络。
关于感知机可以看这一篇博文:https://blog.csdn.net/aaalswaaa1/article/details/82016104
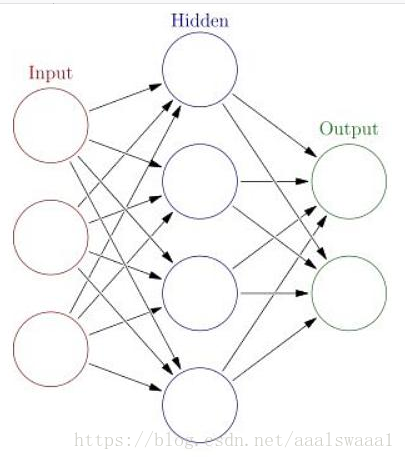
可见,在输入层与输出层之间加入了一层,这层叫隐层。有了这个有3层神经元的网络,就可以解决一些非线性可分的问题,因为它通过空间变换,将非线性可分的变成了线性可分的,这个详细见这个微博http://www.cnblogs.com/subconscious/p/5058741.html
写得非常详细非常好,这里截取了两个图过来说明这个问题
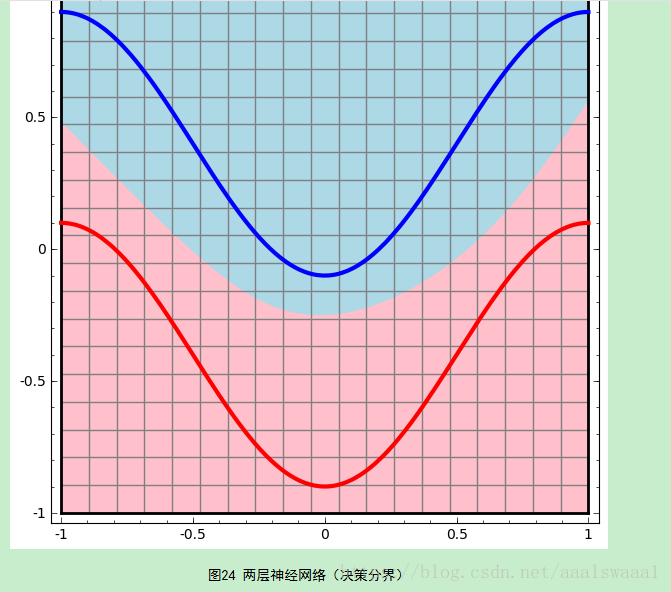
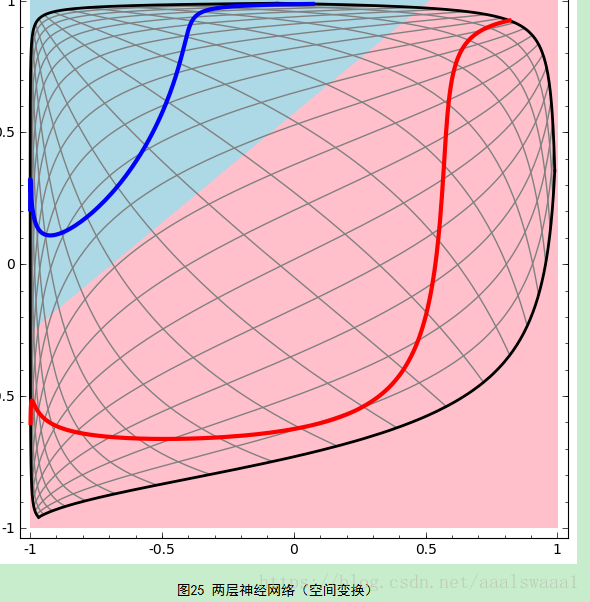
从神经网络的结构图可以看出输入通过隐层再作为输入到了输出层,因此神经网络的学习过程就是通过训练样本来调整神经元之间的连接权以及每个功能神经元的阈值。
误差逆传播算法(BP算法)
这个算法是迄今为止最成功的神经网络学习算法。
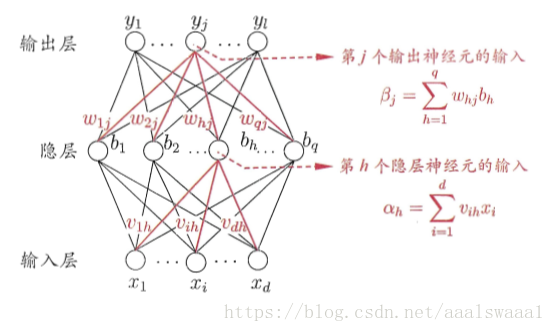

其中
任意参数的更新公式为
以下是其他的一些用到的公式:
均方误差
累积误差
可见,让累积误差最小是算法的最终目的。但是对于每一条数据,参数都会进行一次调整,这样参数的更新频率高,而且对不同样例的更新还可能会出现“抵消”,因此为了达到同样的目的,累积误差逆传播算法(ABP)可以直接针对累积误差来进行更新。
代码实现可以看这里https://blog.csdn.net/aaalswaaa1/article/details/83031937