youtube : 词法分析器
3.1| Lexical Analysis – 词法分析器
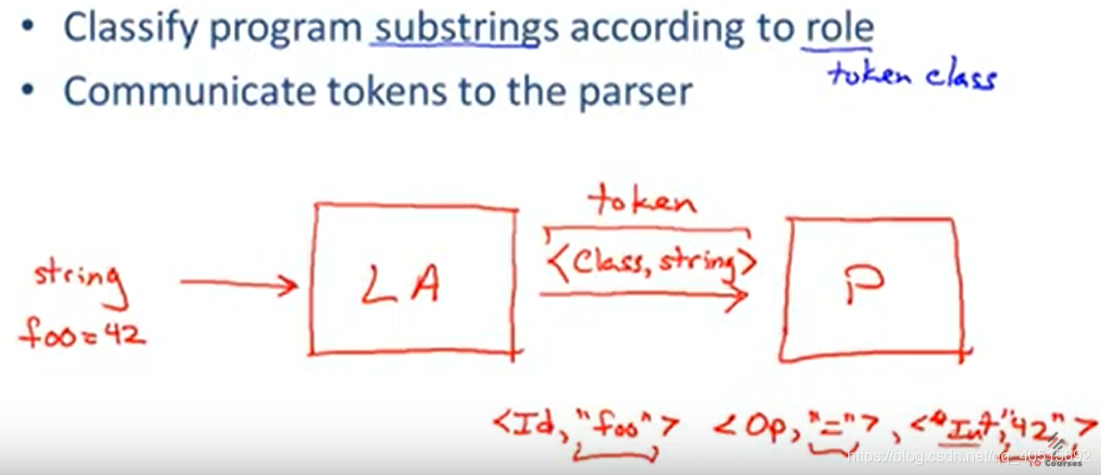
比如输入字符串foo = 42给词法分析器(Lexical Analysis)。
词法分析器生成<id,"foo">,<Operator,"=">,<Integral,"42">,给解析器(Parsing)。
词法分析器的功能:
- 分割输入串中的词素(
lexeme) - 识别出词素对应的词法单元(
token class)
输出<token class, lexeme>
词法分析器从左到右扫描输入串,有时需要向右边看(look ahead)消除部分子串的二义性。
3.2| Lexical Analysis Examples – 词法分析器举例
这一节分析一下过去编程语言可能出现的词法问题。
FORTRAN:空格无关紧要。
比如:VAR1和VA R1一样(纳尼?)
下面的例子来自龙书:
DO 5 I = 1,25
DO 5 I = 1.25
上一句 DO代表循环,变量I从1到25,5表示循环的标签(有点汇编的影子)。
下一句 DO5I=1.25。(变量名为DO5I)
要识别只能look ahead(从左向右扫描字符串时,一直到","才能正确的识别),因此设计词汇系统时要尽可能减小look ahead的量。
FORTRAN之所以有这个规则是因为早期电脑打孔机很容易不经意间添加额外的空格。(硬件不够,软件来凑,或许这就是大佬吧!)。
- PL/1 (IBM设计)关键字不被保留(前方高能!!!)。
比如:IF ELSE THEN THEN = ELSE; ELSE ELSE = THEN。
如果ELSE,然后THEN=ELSE,否则ELSE=THEN。(懂?)
再比如:DECLARE(ARG1,...,ARGN)
无法分辨DECLARE是数组还是关键字。只能看后面有没有等号。
- C++
比如:vector<vector<int>>,用过C++模板的应该懂吧,老版本C++不能这样写,会和流操作符冲突(cin>>x;),但是C++11好像已经支持这么写了。
3.3| Regular Languages – 正则语言
正则表达式用于描述正则语言
- 正则语言由5个要素构成
- 空串
Epsilon –

- 单个字母组成的子串
Single character – 比如:'c' = {"c"}
- 并
Union – (不要觉得'a'+'b'就是'ab' /w\)

- 乘积
Concatenation(级联) –
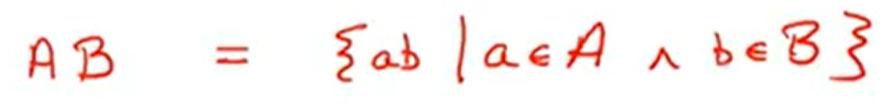
- n次幂
Iteration –
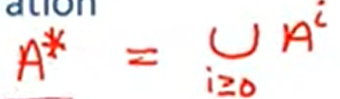
3.4| Formal Languages – 形式语言
- 形式语言:由字母表构成的串
Meaning Function L: Regular Expressions->Set Strings(一个将正则表达式映射为字符串集合的函数)

Meaning is many to one – 多对一的,永远不会一对多。(即字符串集合可有多种正则表达式,而正则表达式唯一确定一个字符串集合)
3.5| Lexical Specifications – 词法规则
- 如何用正则语言描述词法规则
keyword关键词:'if' 'else' 'then'
其中'if' == 'i''f'
integer整数: 非空digit串
digit = '0'+'1'+...+'9'(表示一位数字)
integer = digit digit* = digit+ (digit digit*表示非空的整数,简写为digit+)(乘号和加号都为上标)
identifier标识符:
letter = [a-zA-Z](letter = ‘a’+‘b’+…+‘z’+‘A’+…+'Z’的简写)
identifier = letter(letter+digit)*(字母开头,由letters或者digits组成)
whitespace空白:
whitespace = ( ' ' + '\n' + '\t' )+
PASCAL中浮点数的正则定义:
红色标出的是对于+Epsilon的一种简写方式。

