终于要开始正式的学习了。看了第一节课最大的印象是Ng老师的优雅,儒雅,偏英式的发音(突然意识到他从小在伦敦长大)。配着字幕看的视频,但还是希望能锻炼一下自己的听力,也只有在自己看过一遍印象才深刻,别人的读书笔记再好那也是二手资料。公共课是300人的大课程,感觉和国内的上课氛围也差不多,也是三人一个小组完成project,只不过Ng最后给了一些自己学生的作品确实很具有吸引力。恭维一个西电的图像说斯坦福课程和他们差不多,没想到同学还开始喘了,说西电可是中国斯坦福。
这节课就要用到大量的线性代数的知识linear algebra。
Ng首先展示了一个视频,利用监督学习实现汽车的自动驾驶,作者把他的算法称之为神经网络,其核心算法就是梯度下降法。称作监督是因为有司机为它展示了如何行驶在正确的道路上,屏幕上分别显示了司机选择的方向和机器的输出,在短短两分钟的学习之后,机器输出就近似了司机的方向,切换到自动驾驶,汽车Alvin就可以自己行驶了。要知道这比Ng的公开课还要早15年,即1992年,天哪,在我还没出生的时候就已经有人在实验汽车的自动驾驶了。这也是一个回归问题,已知当前的传感器捕捉的路况和对应的司机的正确驾驶的操作,在出现新的路况时机器自主选择驾驶路线。
这样我们可以得到一个假设h,当再输入其他特征值时就可以输出预测值。线性回归时,h就是一个线性函数如h=b+ax1,当特征不仅仅是房屋面积时,可能还有卧室数目,h=b+ax1+cx2.
我们的目标是使这个函数最小化。求最小值的问题有多种不同的算法。第一种是搜索算法。
给参数向量初始化为0,之后改变参数向量使J减小。一个方法就是Gradient Descent梯度下降法。在一个三维的坐标系中,J函数的值代表高度,随机选择一组参数初始值,对应的J值就就可以想象成所在在山坡高度,目的就好比是找到一条高度下降最快的路线,即最陡的路线,那就可以在当前点求梯度,达到小一点的时候继续求梯度方向,迭代直至找到最优解。当换取另外一个初始值时,找到的最佳路径可能不同,说明找到的都是局部最优解。
在梯度下降的过程中,我们需要时刻更新参数值
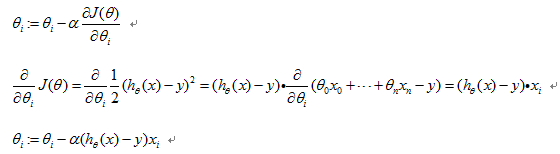
偏导前面的系数 称作learningrate,表示了每次迭代时的步长。事实上,J函数是二次函数,它是一个碗状的二次曲面,可以看到它只有一个最小值。J函数的等高线的投影则是椭圆形,下降最快的路径就是通过等高线最密的路径。收敛时梯度变为0,得到的就是最小二乘拟合。
上面的式子针对了一个样本,当有许多样本时还需要加上求和符号。所以说这种算法叫Batch Gradient Descent,每次迭代需要遍历整个训练样本。所以在训练样本很大时,考虑采用Stactastic Gradient descent随机梯度下降法,也叫增量梯度下降法,incrementalgradient descent。每次更新只利用一组样本,即把一组样本看成多个单个的样本进行计算。这样调整参数的速度会快很多。对海量训练数据,随机梯度下降会快很多,但不会精确收敛到全局最小值。从等高线看,这种算法不是直接收敛到最小值,而是徘徊到最小值附近。
用矩阵计算会更加简洁,先看几个定理:

具体推导过程可以看:https://blog.csdn.net/xiaocainiaodeboke/article/details/50371986
求解出解析表达式就不需要迭代求解了,正规方程直接得到最优解,而且正规方程不需要选择学习速率,但是正规方程只适用于线性模型,像逻辑回归就不适用了。且特征数量大于10000时运算量过大。
以上结果其实也可以通过线性代数直接解出:
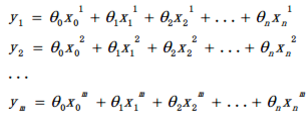
$Y = X * \theta $
$\begin{array}{l}
{X^T}Y = {X^T}X * \theta \\
{({X^T}X)^{ - 1}}{X^T}Y = {({X^T}X)^{ - 1}}({X^T}X) * \theta
\end{array}$
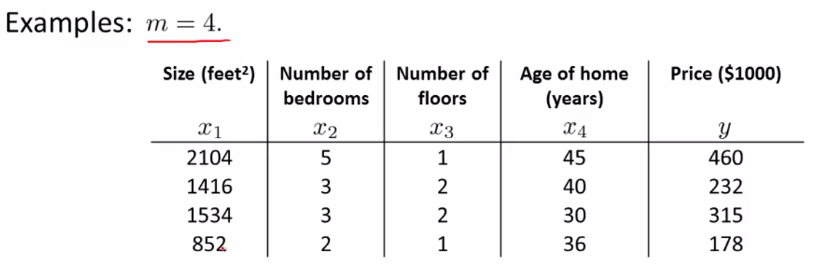
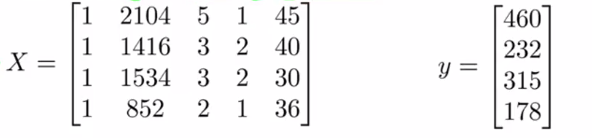
在这个例子中,各项特征是4x4的,但是假设函数有一个偏置项,所以矩阵X有一列全1
统计学和机器学习中,设计矩阵是一组观测结果中的所有解释变量的值构成的矩阵,常用X表示。设计矩阵常用于一些统计模型,如一般线性模型,方差分析中。
正规方程的解涉及X’X的求逆,在公开课就有人问会不会遇到不可逆的情况,其实确实会遇到X’X是奇异矩阵的情况,原因可能是两个特征值成比例,或者训练样本比参数少很多。前一种情况可以删除一种特征,后一种可以删除多余的特征或者正则化方法。实在不行还可以求伪逆。
参考:https://blog.csdn.net/u012790625/article/details/76906315
得知面对多维特征的时候,将特征值归一化成相近的尺度有利于加快收敛。比如房屋预测问题中,面积范围在0~2000平方英尺,而卧室数目在1~5,归一化后,等高线更近似为一个圆而不是椭圆,收敛更快。(为什么???)

关于迭代次数,当下降幅度小于一个阈值如 时就可以认为已经收敛了
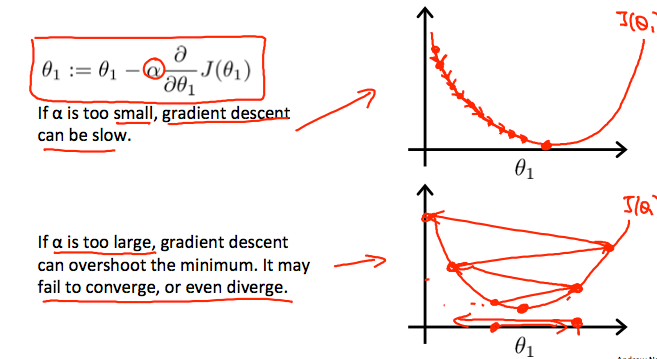
关于学习率,太小的话容易迭代次数过多收敛过慢,太大的话容易找不到最小值
在选取学习率的时候,我们通常都需要设置多个学习率进行测试,学习率之间的倍数通常是3倍和10倍,通过测试,我们就可以找到最好的那一个学习率
学习线性回归的原因不仅仅是因为它是最简单的拟合方法,当我们用高次函数去拟合训练数据时,就是多项式回归,多项式回归其实也可以用线性回归来表示,方法就是把非一次项用变量代换。具体是使用多少项,用几次项,就需要我们对训练数据有深刻的认识了。
Reference:
1.https://blog.csdn.net/u012790625/article/details/76906315
2.https://blog.csdn.net/xiaocainiaodeboke/article/details/50371986