youtube :词法规则
文章较长,是4节视频的合集,大家看的时候多思考吧。
4.1| Lexical Specification – 词法规则
回顾:

如何识别任意字符串是否属于某一语言?
步骤:
- 写出所有
token class的正则表达式
比如:
Number = ‘digit'
Keyword = 'if'+'else'+...
identifier = letter (letter+digit)*
OpenPar = '('
Lexical SpeicificationR = 所有token class的并
R = Keyword + identifier + Number + ...
= r1 + r2 + r3 + ...
- 输入字符串
x1...xn,针对字符串的某个前缀(即子串),判断其是否属于L(R)
for 1 <= i <= n 检查
x1...xi 属于 L(R)
- 如果3成立,那么
x1...xi就属于L(R),否则x1...xi不属于L(R)
x1...xi 属于 L(Rj) 成立对于一些j
- 将
x1...xi从x1...xn中删除,转入3继续判断,直到x为空(哦,原来如此,有点神奇呀!)
避免以上流程中的二义性:
- 总是选择最大的前缀
x1...xi(maximal match)
比如: ’==‘不会看成两个’=‘
- 对给定前缀
x1...xi,匹配其对应的token class中优先级最大的那个(正想问呢)
比如:'if'可能属于identifier或者keyword,此时优先识别为keyword
- 设定
error集合,表示不属于该语言的字符串。若输入此类字符串,则报错。(定义的规则好像很严谨耶,都是大神 /w\ )
将Error放到最后(优先级最低),因为可能我们定义的Error太草率,和前面的正确的正则表达式有重合。
4.2| Finite Automata – 有穷自动机
本节主要讲了:如何用有穷自动机实现正则表达式
-
Finite Automata用于等价地实现正则表达式 -
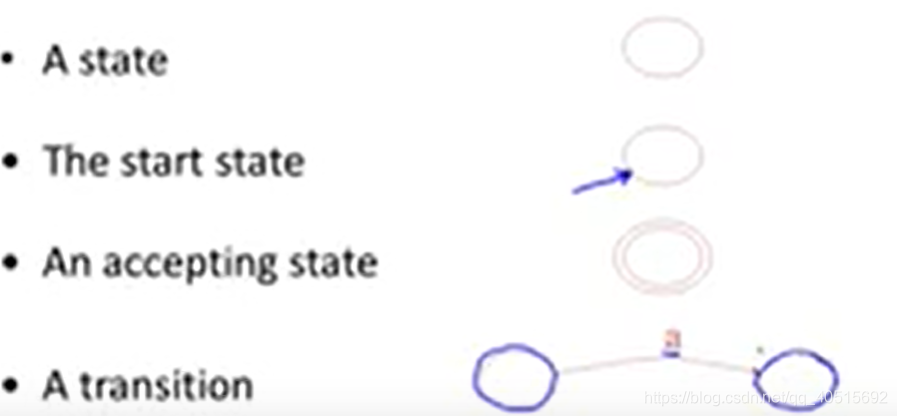
Finite Automata组成:
An input alphabet – 字母表E
A finite set of states – 有限的状态集合S
A start states – 开始状态n
A set of accepting states – 终止状态
A set of transitions – 状态转换
- 有穷自动机的图示:
language of a FA=set of accepted strings– 有穷自动机对应的语言:其接受(终止状态)的字符串组成的集合
比如输入为字符串'110',经过有穷自动机后,Accepts(接受):
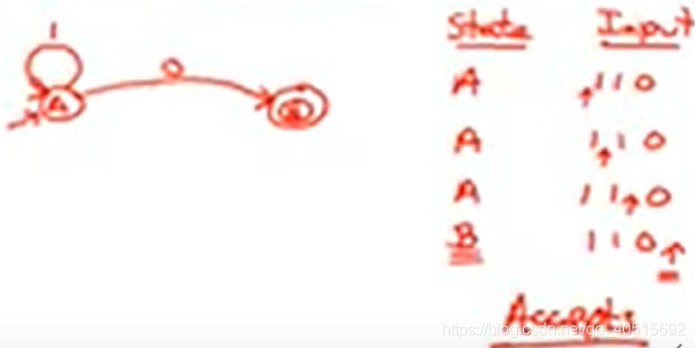
epsilon move 空转换,不用输入就可以从状态A转换到状态B
- DFA 确定型的有穷自动机
-
一个输入对应一个确定的状态转换(即一个确定的输入不会转换到两个状态)
-
没有空转换
- NFA 非确定型的有穷自动机
-
一个输入可以同时对应多个状态转换
-
可以有空转换
4.3| Regular Expressions into NFAs – 正则表达式转换为NFAs
Lexical specification --> Regular Expression --> NFA --> DFA --> Table-driven Implementation of DFA
(词法规范 --> 正则表达式 --> 不确定的有穷自动机 --> 确定的有穷自动机 --> 一组查询表和一些遍历表的代码)
前面的部分完成了前两步,定义了NFA、DFA。(瞬间明朗了haha…)
对于每一个正则表达式,定义NFA、以及空字符和字符a如下:
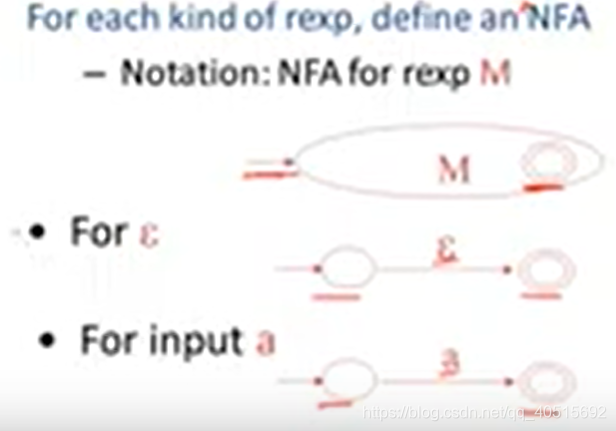
那么(好秀呀!),这样的话正则表达式可以直接按照模板套,变成NFA:
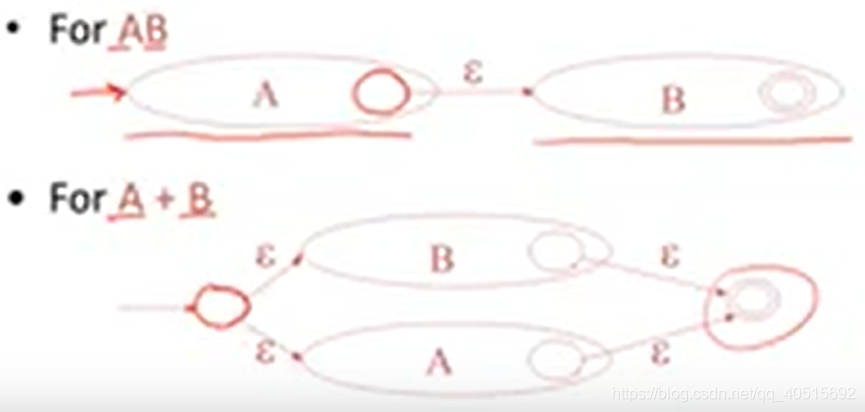
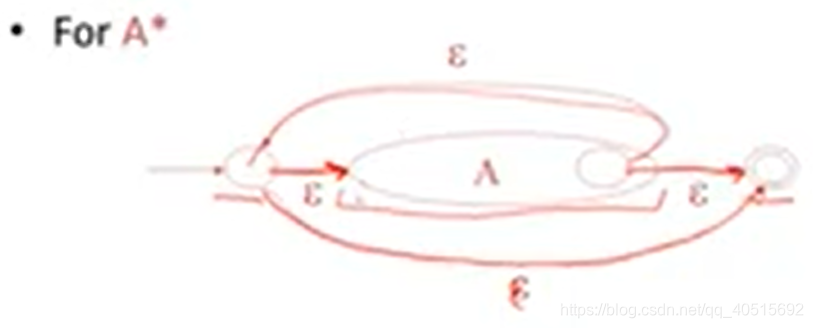
4.4| NFA to DFA – NFA to DFA
(上课是真滴没听懂这一块QAQ)
-
定义:
epsilon closure– 从某状态通过空转换可达到的所有状态的集合 -
定义:NFA
起始状态:A
转换得到的状态:a(X)=从X出发由输入a能达到的所有状态
终止状态:F
- 那么:从NFA转换到DFA
起始状态:epsilon closure(A)
转换得到的状态:X-a->Y if Y = epsilon closure(a(X)) (意思就是从X转换到一个状态集,包含所有从X出发,经过空转换或或其他转换能到达的状态)
终止状态:只要当前状态集中包含F,就是终止状态
- 简单来说:NFA一个输入可以转换到不同状态,DFA一个输入转换到一个唯一的状态集(包含不同状态)
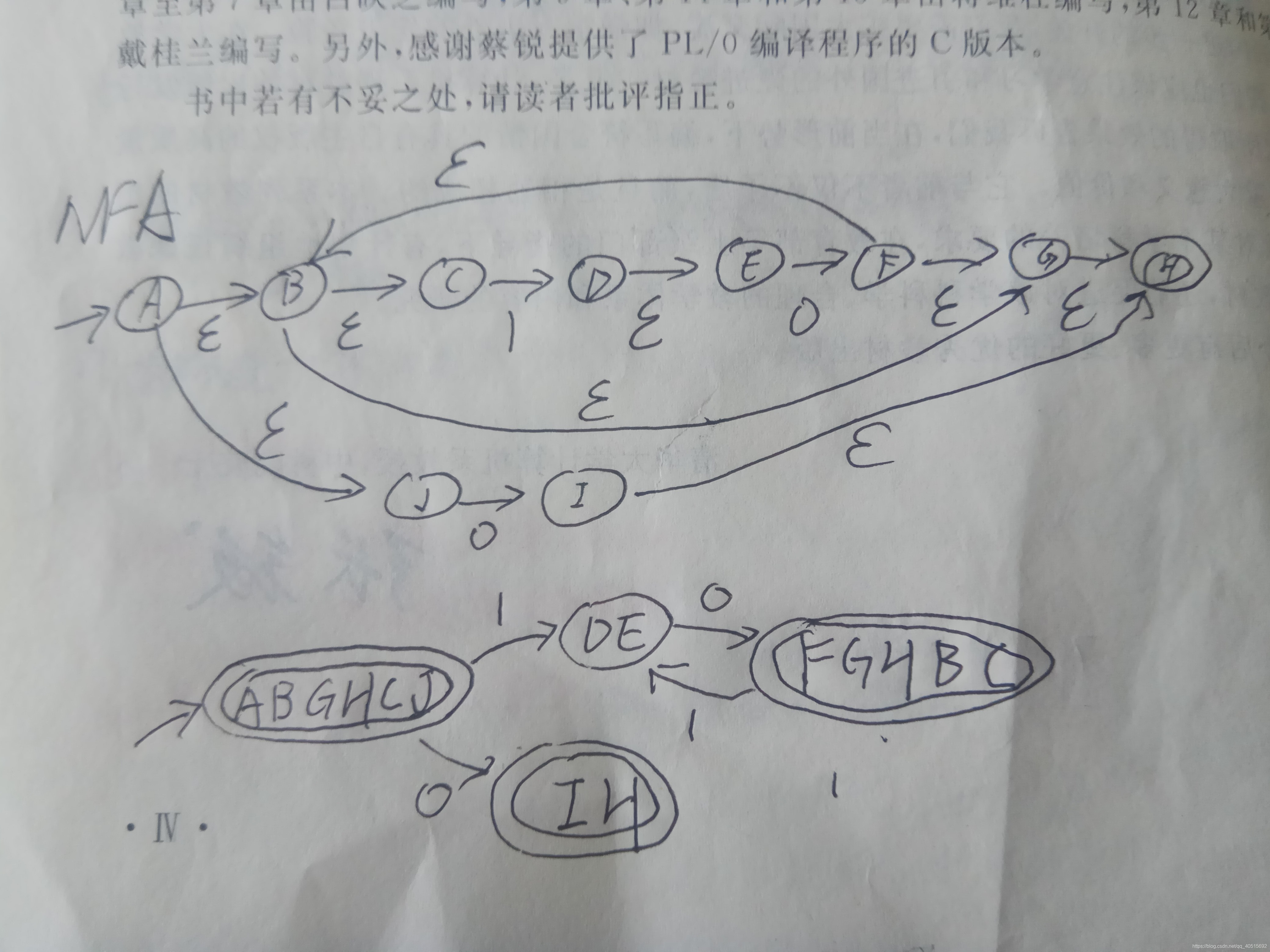
比如 (1+0)*1 NFA表示如下:

步骤:
-
从A(起始状态)开始,找出epsilon closure(A) = ABCDHI,作为DFA的起始状态。(如下图,紫色圈出)
-
可能的转换是’1’或者’0’,从’0’开始可以到达F,那么求epsilon closure(F) = FGHIABCD。(如下图,深蓝色圈出)
-
从’0’开始可以到达E或者J,那么求epsilon closure(E) + epsilon closure(F) = ABCDEGHIJ,因为包含J,所以说终止状态。(如下图,红色圈出)
-
对红圈、深蓝圈继续上面的步骤。
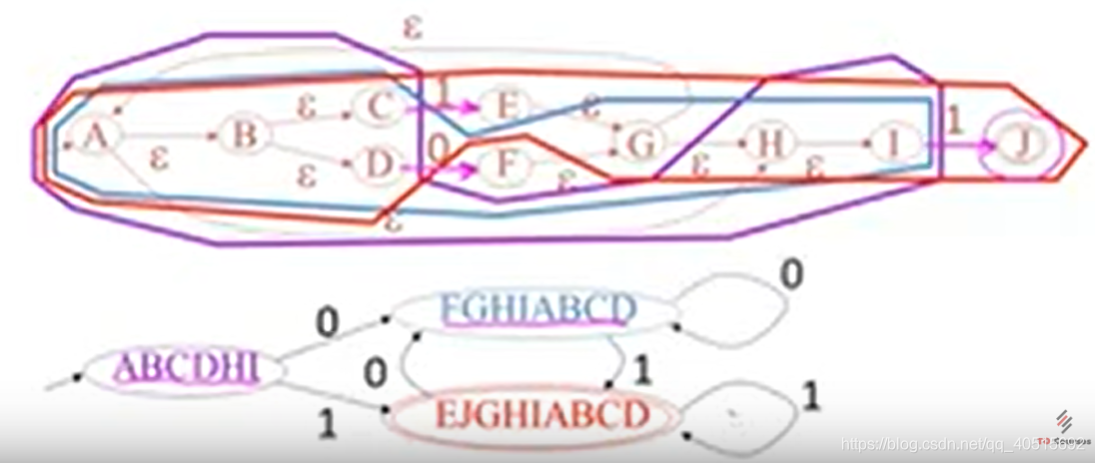
练习(字母我自己标的,不一定正确,结果是正确的):
4.4| Implementing Finite Automata – 实现有穷自动机
一个DFA可以用一个2维数组T实现
一个维度表示状态
一个维度表示输入符号
对于每一个转换 Si --a--> Sk , 定义T[i,a] = k
根据转换表A处理输入字符串(pretty cool)
i = 0; // 初始化指向开始状态
state = 0; // 表示当前状态
while(input[i]) { // 对于输入,更新state
state = A[state][input[i++]];
}
因为N个状态的NFA可能对应2^N-1个DFA状态,所以可以用指针压缩表,也可以直接将NFA转换为表格。
DFA – 更快、不太紧凑
NFA – 慢,简洁
