1.实验目的
通过PCL处理点云数据,从点云数据中提取出待装货货车的点云数据并将其可视化。
2.所处理点云的原始可视化图像及最终效果图
原始图:
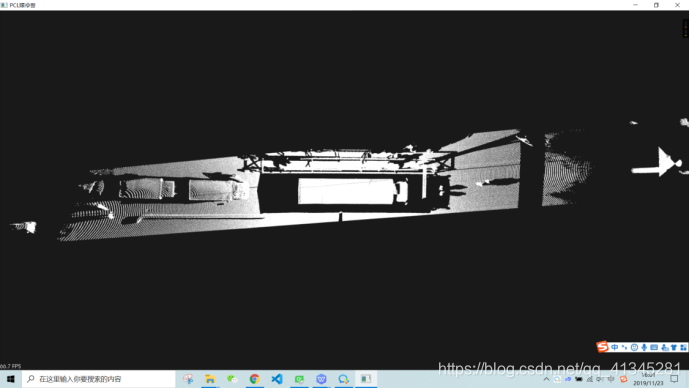
处理后:

3.处理过程概述
1.首先由于点云数据中点的数量很大,做一些处理时耗时较多,所以第一步是使用体素滤波,实现下采样,即在保留点云原有形状的基础上减少点的数量 减少点云数据,以提高后面对点云处理的速度。
2.通过随机采样一致性(前面多出用到)分割地面,将地面从点云中分离出来,这时候地面上的物体就悬空了。
3.去除地面后地面上物体都悬空了,这时候就使用统计滤波剔除掉离散点。
4.物体悬空后就更好分离了,现在就构建Kdtree通过欧几里得聚类提取获取路面上不同物体,然后车辆就提取了出来。
4.实验内容
4.1.上面的基本思路已经写出来了,下面就直接上代码。
#include <iostream>
#include <pcl/point_types.h>
#include <pcl/filters/passthrough.h>
#include <pcl/filters/voxel_grid.h>
#include <pcl/io/pcd_io.h>
#include <pcl/visualization/cloud_viewer.h>
#include <pcl/filters/statistical_outlier_removal.h>
#include <pcl/sample_consensus/method_types.h> //随机参数估计方法头文件
#include <pcl/sample_consensus/model_types.h> //模型定义头文件
#include <pcl/segmentation/sac_segmentation.h> //基于采样一致性分割的类的头文件
#include <pcl/filters/extract_indices.h>
#include <pcl/segmentation/extract_clusters.h>
#include <QDebug>
#include<iostream>
#include<algorithm>
using namespace std;
Int main (int argc, char** argv)
{
//点云对象
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZ>);
//处理后点云对象
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_handle(new pcl::PointCloud<pcl::PointXYZ>);
//从点云文件中读取点云数据
pcl::io::loadPCDFile("d:/2.pcd", *cloud);
cloud_handle = cloud;
/**
先使用体素滤波向下采样处理点云
* @brief sor
*/
pcl::VoxelGrid<pcl::PointXYZ> sor; //创建滤波对象
sor.setInputCloud (cloud); //设置需要过滤的点云给滤波对象
sor.setLeafSize (0.5, 0.5, 0.5); //设置滤波时创建的体素体积,单位m,因为保留点云大体形状的方式是保留每个体素的中心点,所以体素体积越大那么过滤掉的点云就越多
sor.filter (*cloud); //执行滤波处理
/**
平面分割,分割出地面
* 创建分割时所需要的模型系数对象,coefficients及存储内点的点索引集合对象inliers
* @brief coefficients
*/
pcl::ModelCoefficients::Ptr coefficients (new pcl::ModelCoefficients);
pcl::PointIndices::Ptr inliers (new pcl::PointIndices);
pcl::SACSegmentation<pcl::PointXYZ> seg; // 创建分割对象
seg.setOptimizeCoefficients (true); // 可选择配置,设置模型系数需要优化
// 必要的配置,设置分割的模型类型,所用的随机参数估计方法,距离阀值,输入点云
seg.setModelType (pcl::SACMODEL_PLANE); //设置模型类型
seg.setMethodType (pcl::SAC_RANSAC); //设置随机采样一致性方法类型
seg.setDistanceThreshold (1); //设定距离阀值,距离阀值决定了点被认为是局内点是必须满足的条件
//表示点到估计模型的距离最大值
seg.setInputCloud (cloud);
//引发分割实现,存储分割结果到点几何inliers及存储平面模型的系数coefficients
seg.segment (*inliers, *coefficients);
//创建点云提取对象,将处理后的点云提取出来
pcl::ExtractIndices<pcl::PointXYZ> extract;
extract.setInputCloud (cloud);
extract.setIndices (inliers);
extract.setNegative (true);
extract.filter (*cloud);
/**
统计滤波去除离散点
* @brief sta
*/
pcl::StatisticalOutlierRemoval<pcl::PointXYZ> sta; //创建滤波器对象
sta.setInputCloud (cloud); //设置待滤波的点云
sta.setMeanK (2000); //设置在进行统计时考虑查询点临近点数
sta.setStddevMulThresh (0.05); //设置判断是否为离群点的阀值,根据原理来说,阈值越小过滤掉的点就越多
sta.filter (*cloud); //存储
// 建立kd-tree对象用来搜索
pcl::search::KdTree<pcl::PointXYZ>::Ptr kdtree(new pcl::search::KdTree<pcl::PointXYZ>);
kdtree->setInputCloud(cloud);
// Euclidean 聚类对象.
pcl::EuclideanClusterExtraction<pcl::PointXYZ> clustering;
// 设置聚类的最小值 4m
clustering.setClusterTolerance(4);
// 设置聚类的小点数和最大点云数
clustering.setMinClusterSize(5000);
//clustering.setMaxClusterSize(25000);
//设置搜索方式
clustering.setSearchMethod(kdtree);
clustering.setInputCloud(cloud);
std::vector<pcl::PointIndices> clusters;
clustering.extract(clusters);
//处理后保存的聚类是已降序排序的,所以第一个聚类就是我们想要的聚类
long num = 0;
int j = 0;
for (std::vector<pcl::PointIndices>::const_iterator i = clusters.begin(); i != clusters.end();++i)
{
//添加所有的点云到一个新的点云中
pcl::PointCloud<pcl::PointXYZ>::Ptr cluster(new pcl::PointCloud<pcl::PointXYZ>);
for (std::vector<int>::const_iterator point = i->indices.begin(); point != i->indices.end(); point++)
cluster->points.push_back(cloud->points[*point]);
cluster->width = cluster->points.size();
cluster->height = 1;
cluster->is_dense = true;
j++;
qDebug()<<"编号"<<j<<"聚类点数量:"<<cluster->points.size();
}
//获取最大聚类将所有点添加到新点云中
std::vector<pcl::PointIndices>::const_iterator i = clusters.begin();
pcl::PointCloud<pcl::PointXYZ>::Ptr cluster(new pcl::PointCloud<pcl::PointXYZ>);
for (std::vector<int>::const_iterator point = i->indices.begin(); point != i->indices.end(); point++)
cluster->points.push_back(cloud->points[*point]);
cluster->width = cluster->points.size();
cluster->height = 1;
cluster->is_dense = true;
//处理后点云显示
pcl::visualization::CloudViewer viewer("PCL滤波");
viewer.showCloud(cluster);
while (!viewer.wasStopped()){
}
return (0);
}
控制台输出结果:
编号 1 聚类点数量: 20847 (装货机器旁边的货车)
编号 2 聚类点数量: 10410 (装货机器)
编号 3 聚类点数量: 7171 (后面显示不完整的或者)
4.2.代码分解
下面我们对上面的代码进行分解,为了更好地理解整个处理过程,也将对前面两篇文章未提及的知识进行拓展,尽量做到详细。
//点云对象
pcl::PointCloudpcl::PointXYZ::Ptr cloud(new pcl::PointCloudpcl::PointXYZ);
//从点云文件中读取点云数据
pcl::io::loadPCDFile(“d:/2.pcd”, *cloud);
首先是从磁盘中读取点云数据: 这里是从磁盘中读取点云数据到二进制存储块中。
pcl::VoxelGrid<pcl::PointXYZ> sor; //创建滤波对象
sor.setInputCloud (cloud); //设置需要过滤的点云给滤波对象
sor.setLeafSize (0.5, 0.5, 0.5); //设置滤波时创建的体素体积,单位m,因为保留点云大体形状的方式是保留每个体素的中心点,所以体素体积越大那么过滤掉的点云就越多
sor.filter (*cloud); //执行滤波处理
使用体素滤波向下采样处理点云,这一步是十分关键的,我们实际的处理的点云文件中的数据可能很多,过多的点云数量会对后续分割工作带来困难。体素滤波器可以达到向下采样同时不破坏点云本身几何结构的功能。他的具体原理是将三维点云划分为众多的体素(立方体),然后在每个体素内,用体素中所有点的重心来近似显示体素中其他点,这样该体素就内所有点就用一个重心点最终表示,这样使用体素滤波下采样处理过后的点云虽然点的数量减少的,但是点云的基本形状还保留。他的设置参数主要就是setLeafSize (0.5, 0.5, 0.5); 参数单位都是m,分别代表体素的长宽高。下采样的程度就是通过这三个参数来设置的,很好理解,就是体素体积越大那么保留的点就会越少。

pcl::ModelCoefficients::Ptr coefficients (new pcl::ModelCoefficients);
pcl::PointIndices::Ptr inliers (new pcl::PointIndices);
pcl::SACSegmentation<pcl::PointXYZ> seg; // 创建分割对象
seg.setOptimizeCoefficients (true); // 可选择配置,设置模型系数需要优化
// 必要的配置,设置分割的模型类型,所用的随机参数估计方法,距离阀值,输入点云
seg.setModelType (pcl::SACMODEL_PLANE); //设置模型类型
seg.setMethodType (pcl::SAC_RANSAC); //设置随机采样一致性方法类型
seg.setDistanceThreshold (5); //设定距离阀值,距离阀值决定了点被认为是局内点是必须满足的条件
//表示点到估计模型的距离最大值
seg.setInputCloud (cloud);
//引发分割实现,存储分割结果到点几何inliers及存储平面模型的系数coefficients
seg.segment (*inliers, *coefficients);
//创建点云提取对象,将处理后的点云提取出来
pcl::ExtractIndices<pcl::PointXYZ> extract;
extract.setInputCloud (cloud);
extract.setIndices (inliers);
extract.setNegative (true);
extract.filter (*cloud);
平面分割,分割出地面,使货车等物体悬空,这样就方便后面提取聚类的操作。这里有三个必要的参数设置,一个是设置模型类型setModelType (pcl::SACMODEL_PLANE);这里设置的使平面类型,还有个是setMethodType (pcl::SAC_RANSAC)设置随机采样一致性方法类型,这里选择的是Ransac,它是基于Ransac的来做平面拟合的。具体原理是通过改变平面模型(ax+by+cz+d=0)的参数:a, b, c和d,找出哪一组的参数能使得这个模型一定程度上拟合最多的点。这个程度就是由第三个方法来设置的setDistanceThreshold (1)即distance threshold这个参数来设置。那找到这组参数后,这些能够被拟合的点就是平面的点。distance threshold就是平面模型分割的阈值,可以等同于平面厚度阈值,如果阈值设置过大那么平面上的其他物体也将被分割。

pcl::StatisticalOutlierRemovalpcl::PointXYZ sta; //创建滤波器对象
sta.setInputCloud (cloud); //设置待滤波的点云
sta.setMeanK (2000); //设置在进行统计时考虑查询点临近点数
sta.setStddevMulThresh (0.05); //设置判断是否为离群点的阀值,根据原理来说,阈值越小过滤掉的点就越多
sta.filter (*cloud); //存储
统计滤波去除离散点,在上篇总结中将去除离散点的操作放在了第二步,后来想想这是不对的,因为分离地面之后地面上的物体悬空,这时候将会有很多无用离散点,所以在分离地面之后也要使用一下统计滤波,那第二步使用的统计滤波就显得多余了。统计滤波的原理是计算每个点到其最近的k个点平均距离(假设得到的结果是一个高斯分布,其形状是由均值和标准差决定),那么平均距离在标准范围之外的点,可以被定义为离群点并从数据中去除。这里有两个重要的参数临近点数k和距离阈值d,阈值单位为m,设置方法分别为setMeanK (2000)、setStddevMulThresh (0.05)。

// 建立kd-tree对象用来搜索
pcl::search::KdTree<pcl::PointXYZ>::Ptr kdtree(new pcl::search::KdTree<pcl::PointXYZ>);
kdtree->setInputCloud(cloud);
// Euclidean 聚类对象.
pcl::EuclideanClusterExtraction<pcl::PointXYZ> clustering;
// 设置聚类的最小值 4m
clustering.setClusterTolerance(3);
// 设置聚类的小点数和最大点云数
clustering.setMinClusterSize(5000);
//clustering.setMaxClusterSize(25000);
//设置搜索方式
clustering.setSearchMethod(kdtree);
clustering.setInputCloud(cloud);
std::vector<pcl::PointIndices> clusters;
clustering.extract(clusters);
目前地面上的物体目前已经悬空了,现在就使用欧几里得聚类提取将物体提取出来。这个算法通俗来讲就是先从点云中找出一个点p0,然后寻找p0周围最近的n个点,如果这n个点与p0之间的距离小于预先设定的阈值,那么就把这个点取出,依次重复。setClusterTolerance(3);setMinClusterSize(5000);setMaxClusterSize(25000);
这三个方法分别设置阈值、聚类的最小点数和聚类的最大点数,其中阈值是指搜索半径,对于搜索半径我的理解是一个聚类的最小半径,不能太大也不能太小,太大了就会将多个聚类变成一个当做聚类,太小的就会将一个聚类分割为多个聚类,这里设置的是3m,差不多应该就是半挂车的宽度(不知道理解是否正确,实验结果是太小了就会将货车分割为多个聚类,太大了就会把旁边的设备包含到一个聚类)。
在这里其实还要引入一个知识点,那就是kd—tree。Kd-tree又称为k维树,是一种数据结构,本质上就是一种带有约束条件的二分查找树,使用kd-tree的目的其实就是将点云中的离散点建立拓扑关系,实现基于邻域关系的快速查找,加快欧几里得聚类提取的搜索速度。
//处理后保存的聚类是已降序排序的,所以第一个聚类就是我们想要的聚类
int j = 0;
for (std::vectorpcl::PointIndices::const_iterator i = clusters.begin(); i != clusters.end();++i)
{
//添加所有的点云到一个新的点云中
pcl::PointCloudpcl::PointXYZ::Ptr cluster(new pcl::PointCloudpcl::PointXYZ);
for (std::vector::const_iterator point = i->indices.begin(); point != i->indices.end(); point++)
cluster->points.push_back(cloud->points[*point]);
cluster->width = cluster->points.size();
cluster->height = 1;
cluster->is_dense = true;
j++;
qDebug()<<“编号”<<j<<“聚类点数量:”<points.size();
}
提取聚类之后将点云索引结果存到了clusters 中,想要从中提取点云聚类就需要迭代clusters,这里目的是在控制台打印分割出的聚类结果。
//获取最大聚类将所有点添加到新点云中
std::vectorpcl::PointIndices::const_iterator i = clusters.begin();
pcl::PointCloudpcl::PointXYZ::Ptr cluster(new pcl::PointCloudpcl::PointXYZ);
for (std::vector::const_iterator point = i->indices.begin(); point != i->indices.end(); point++)
cluster->points.push_back(cloud->points[*point]);
cluster->width = cluster->points.size();
cluster->height = 1;
cluster->is_dense = true;
我们要找的其实就是最大得那个聚类,因为火车就是最大的,离散点最多的,并且索引结果也是降序排序的,所以第一个就是我们想要的结果。
//处理后点云显示
pcl::visualization::CloudViewer viewer("PCL滤波");
viewer.showCloud(cluster);
while (!viewer.wasStopped()){
}
点云显示,这里就不做解释了。

