Contrastive Adaptation Network for Unsupervised Domain Adaptation
简述:
无监督域自适应(UDA)对目标域数据进行预处理,而手工注释只在源域可用。以往的方法在忽略类信息的情况下,会使域间的差异最小化,从而导致不一致和泛化性能低下。目前,虽然有ImageNet这种庞大的拥有精确标记的数据集,但是对于每个特定的目标域或任务,手工标签往往很难或很昂贵,域内标记数据的缺乏阻碍了数据拟合模型在实际问题中的应用。本文提出的CAN网络(Contrastive Adaptation Network)优化了一个显式地对类内域差异和类间域差异建模的新度量,设计了一种交替更新 (alternating update)的培训策略,可以端到端(end-to-end)的方式进行。
下图中,左:自适应之前,源和目标数据之间存在域移动;中:以往的方法,与类无关的调整将源和目标数据在域级别上对齐,忽略了样本的类标签,因此可能导致次优解决方案。因此,一个标签的目标样本可能与另一个标签的源样本不一致。右:我们的方法是执行跨域的类感知对齐。为了避免失配,最小化类内部域的差异,最大化类间域差异,增强模型的泛化能力。
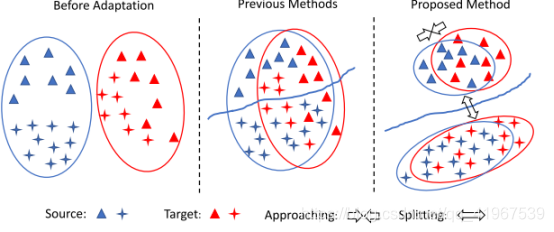
由于以下原因,这可能会影响适应性能。首先,不同类的样本可能排列不正确。其次,所学习的决策边界对目标域的泛化能力较差。为了解决上述问题,我们引入了一个新的对比域差异(CDD)目标来启用类感知的UDA。要使用CDD进行评估和优化,我们不能训练一个立即可以调用的深度网络,因为我们需要克服以下两个技术问题。首先,我们需要来自两个域的标签来计算CDD,然而,在UDA中目标标签是未知的。当然,一种直接的方法是通过训练过程中的网络输出来估计目标标签,然而,由于估计可能是噪声的,我们发现它会有损自适应性能。其次,在mini-batch训练中,对于一个类别 C,mini-batch可能只包含一个域(源或目标)的样本,使得估计C的类内域差异不可行,这可能导致更低效的适应。上述问题需要对网络和培训范式进行专门的设计。
所以,我们提出的CAN网络来促进CDD的优化。训练时除了最小化标记源数据的交叉熵损失外,还可以通过聚类来估计目标样本的潜在标记假设,并根据CDD度量调整特征表示。聚类后,模糊的目标数据(即离聚类中心较远)和模糊的类(即在聚类中心附近包含较少的目标样本)被归零以估计CDD。此外,为了简化CAN的小批量训练,我们对源域和目标域都使用了类感知抽样(Class-aware sampling),即在每次迭代中,我们对随机抽样的类子集中的每个类从两个域抽取数据。类感知抽样可以提高训练效率和适应能力。
知识点:
1.MMD距离(Maximum mean discrepancy)
最大均值差异(Maximum mean discrepancy),度量在再生希尔伯特空间中两个分布的距离,是一种核学习方法。两个随机变量的距离为:
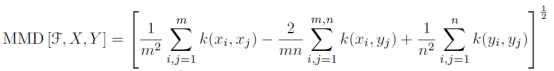
其中k(.)是映射,用于把原变量映射到高维空间中。X,Y表示两种分布的样本,F表示映射函数集。
基于两个分布的样本,通过寻找在样本空间上的映射函数K,求不同分布的样本在K上的函数值的均值,通过把两个均值作差可以得到两个分布对应于K的mean discrepancy。寻找一个K使得这个mean discrepancy有最大值,就得到了MMD。最后取MMD作为检验统计量(test statistic),从而判断两个分布是否相同。如果这个值足够小,就认为两个分布相同,否则就认为它们不相同。更加简单的理解就是:求两堆数据在高维空间中的均值的距离。
近年来,MMD越来越多地应用在迁移学习中。在迁移学习环境下训练集和测试集分别取样自分布p和q,两类样本集不同但相关。我们可以利用深度神经网络的特征变换能力,来做特征空间的变换,直到变换后的特征分布相匹配,这个过程可以是source domain一直变换直到匹配target domain。匹配的度量方式就是MMD。
2.CDD(对比域差异)
将类内域差异最小化以压缩类内样本的特征表示,将类间域差异最大化以将彼此的表示进一步推离决策边界。对于两个类c1, c2(可以相同,也可以不同),平方DH(P, Q)的核均值嵌入估计为
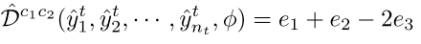
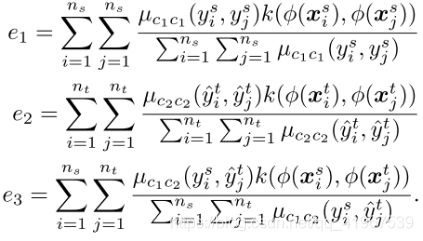
CDD计算为
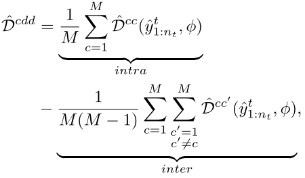
3.CAN(Contrastive Adaptation Network)对比适应网络
提取一般特征的卷积层具有更强的可移植性,而表现出抽象和领域特定特征的全连通(FC)层则具有更强的可适应性。本文先从ImageNet预训练网络开始,例如ResNet,并将最后一个FC层替换为任务特定的层。并遵循了将上一个FC层的域差异最小化的一般规则,并通过反向传播对卷积层进行了微调(fine-tune)。然后,前面所提出的CDD可以很容易地作为FC层激活的适应模块被引入目标。我们将我们的网络命名为对比适应网络(CAN)。
在深度CNN中,我们需要在多个FC层上最小化CDD:
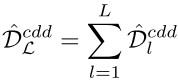
此外,我们通过最小化交叉熵损失来训练带标记源数据的网络:
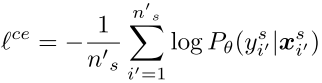
因此,总体目标可以表述为:
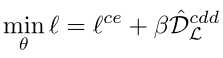
模型:
CAN的结构如图:
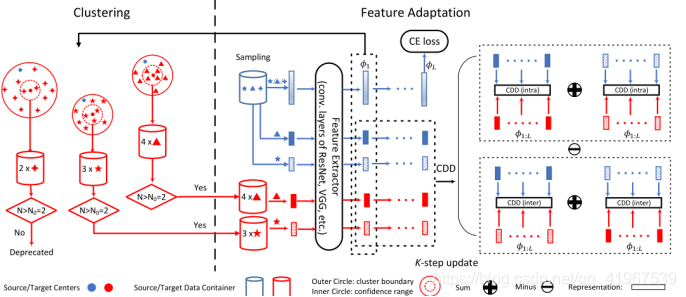
CAN的训练过程。为了最小化CDD,我们在通过聚类更新目标标签假设和通过反向传播适应特征表示之间进行交替优化。在聚类中,我们根据目标样本当前的特征表示,采用球面K均值聚类。集群的数量等于底层类的数量,每个类集群的初始中心设置为同一类内源数据的中心。然后丢弃不明确的数据(即远离附属的集群中心)和不明确的类(即在附属的集群中心周围包含很少的目标样本)。对于特征自适应,聚类阶段提供的标记目标样本与标记源样本一起通过网络实现多层特征表示。采用领域特定的FC层特征来估计CDD 。此外,我们将交叉熵损失应用于独立采样的源数据。通过最小化CDD和交叉熵损失进行反向传播适应了这些特性并提供了类感知对齐。
下图算法为AO过程的一个循环,即在集群阶段(步骤1- 4)和K-step网络更新阶段(步骤5-11)之间交替。在我们的实验中,AO循环重复多次。由于特征适应过程相对较慢,我们异步更新目标标签和网络参数,使训练更加稳定和有效。

成果:
下图为Office-31和VisDA-2017数据集展示:

数据集分为两种Office-31和VisDA-2017,其中Office-31分为三个域:Ama- zon website (Amazon domain), 2) web camera (Webcam domain), and 3) digital SLR camera (DSLR domain) ,下表中以A→W为例,意为Amazon为源域,Webcam为目标域,有A迁移到W的精确度。
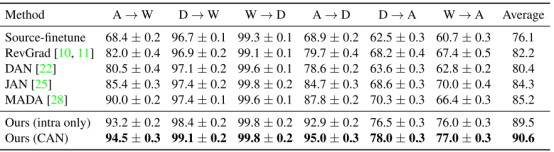
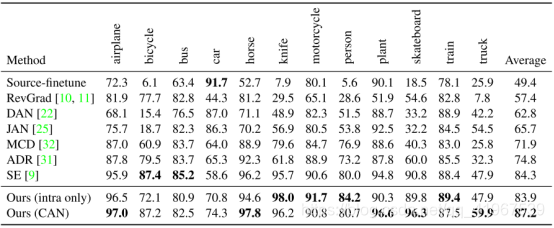
下图使用t-SNE可视化不同的适应方法(彩色显示)。左t-SNE of JAN右:CAN。最后一个的FC层的输入激活被用来计算t-SNE。该任务是在Office-31任务W →A的结果。可以看出来CAN网络的效果优于t-SNE of JAN。

