一、Domain adaptation
在开始介绍之前,首先我们需要知道Domain adaptation的概念。Domain adaptation,我在标题上把它称之为域适应,但是在文中我没有再翻译它,而是保持它的英文原意,这也有助于我们更好的理解它的概念。Domain adaptation的目标是在某一个训练集上训练的模型,可以应用到另一个相关但不相同的测试集上。
给出source dataset(源数据,也就是初始的训练集)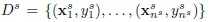
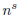
给出target dataset(目标数据,就是相关域的数据集)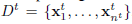
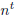
现在Domain adaptation的目标就是使用提供的所有数据训练一个统计模型,从而最小化预测误差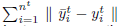
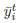
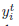
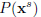
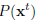
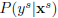
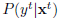
ok,问题就是上述的那样,关于Domain adaptation我们可以再扯一点闲话,所谓边缘分布就是数据在特征空间当中的分布,如果你不理解特征空间这个词,把它理解为数据分布就好。可能还会有人问现实当中数据分布很抽象,你怎么知道几万张图片,它们的分布是怎样的?这个问题是初入坑必须要搞明白的,衡量图像我们也是通过特征(例如,haar特征,梯度,颜色直方图等等),将图像特征量化成数字,分布就能看出来了,所以记住我们讨论分布的前提是我们已经确定用哪种特征来衡量数据。同样条件分布就是某个确定样本的分类概率分布了,如果是二分类问题,那么此条件分布就看作一个伯努利分布,其他情况以此类推。
Domain adaptation有哪些实现手段呢?几乎所有的手段都尝试去学习一个特征转换,使得在转换过后的特征空间上,source dataset和target dataset分布的区分度达到最小。现实世界当中这个问题又分为不同的类型:1)边缘分布相同,条件分布不同且相关2)边缘分布不同且相关,条件分布相同3)边缘分布和条件分布都不同且相关。这几种情况其实可以归纳到迁移学习domain和task的范畴中,以后我会写一篇文章专门对迁移学习和Domain adaptation作整理。
Instance reweighting和subspace learning是Domain adaptation中两种经典的学习策略,前者对source data每一个样本加权,学习一组权使得分布差异最小化,后者则是转换到一个新的共享样本空间上,使得两者的分布相匹配。另外比较重要的的一点是,实际训练当中,“最小化分布差异”这个约束条件是放在目标函数中和最小化误差一起优化的,而不是单独优化。
二、DTN之共享特征抽取层
Deep Transfer Network(这里简称DTN)就是一个用深度网络去做Domain adaptation的理念,这个网络被分为了两种类型的层,共享特征抽取层和判别层。第一层共享特征抽取层用于匹配边缘分布,共享特征抽取层可以是一个多层感知机,如果网络层数为l的话,我们一般会把前l-1层看作共享特征抽取层,而l-1层的输出则是一种分布相近的共享特征,它可用于后面做类别判断。
在这之前我们应该指定一个分布差异的度量标准,这里使用了empirical Maximum Mean Discrepancy(MMD),假设有source dataset和target dataset分别为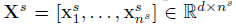
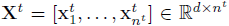
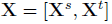


接下来我们讨论如何进行match,假设W是k*d的投影矩阵,它把d维特征向量x投影到k维上面,然后通过激活函数f做一个非线性变化,得到h:
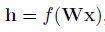
在经历了l-1层的类似变换以后,假设输出为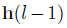
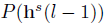
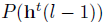
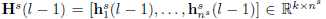
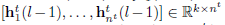
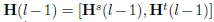
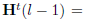
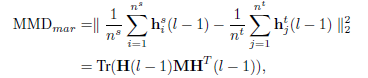
三、DTN之判别层
在判别层,其实和传统的神经网络没多大区别,多用softmax回归来做概率预测,这里也是一样,列出softmax的判别公式:
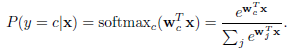
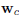
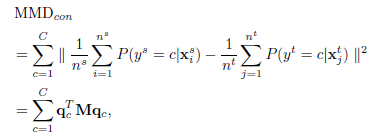
四、优化步骤
最后加上上述的两个约束条件,目标函数变为
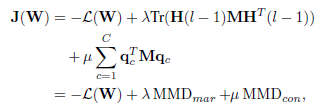
后面的λ和μ都是人为指定的,分别表示了约束的重要性程度,为0时,就退化成了传统神经网络。
优化还是使用的随机梯度下降,上面列出来的两个MMD公式当中,首先我们要确定哪个是变量,这是很重要的,虽然这个问题很弱智。在确定了变量之后,我们可以计算对于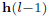
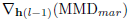
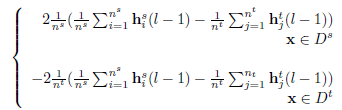
同样的对于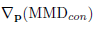
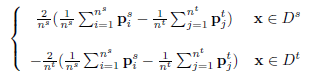
接下来只要求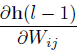
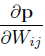
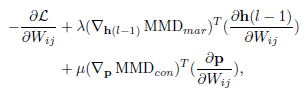
看似一切都解决了!但其实别忘了还有一个问题,就是MMD其实是对全部数据集来求的,但是在神经网络中不可能做到这一点,所以训练的时候采取了mini batch的方法,用一个batch来代替数据集的分布,mini batch其实并不会影响实验结果,因为假设将数据集切分为N份,在N上的MMD会大于总的数据集上的MMD,用公式表达如下:
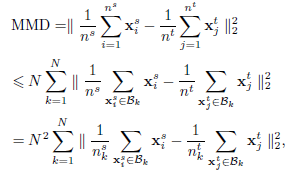
也就是说,只要我们约束了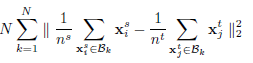
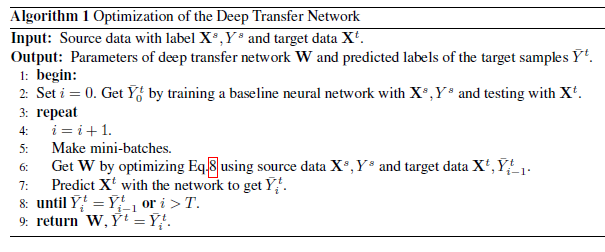
最后,总结一下算法的流程: