Dataframe:数据帧
Dataframe VS Excel:一个DataFrame相当于一个Excel的sheet
#创建一个空Excel
import panda as pd
df = pd.DataFrame()
df.to_excel("D:/2019.上/3月/output.xlsx")
#在空Excel的表中填充数据
import panda as pd
df = pd.DataFrame({'ID' : [1,2,3], 'Name' : ['KX’ , 'CM' , 'LY']})
df.to_excel("D:/2019.上/3月/output.xlsx")
#设置ID为索引
import panda as pd
df = pd.DataFrame({'ID' : [1,2,3], 'Name' : ['KX’ , 'CM' , 'LY']})
df = df.set_index('ID')
df.to_excel("D:/2019.上/3月/output.xlsx")
import pandas as pd
#csv文件,多了一行,第一行是乱码,或者有一个脏数据
data = pd.read_csv('D:/大四上/毕业论文/deepin/url.csv', head=1)
#csv文件,第一行没有列名
data = pd.read_csv('D:/大四上/毕业论文/deepin/url.csv', head=None)
data.columns = ["url", "detail"]
data.set_index("url", inplace=True)
print(data.columns)
#正常的csv文件设置索引
data = pd.read_csv('D:/大四上/毕业论文/deepin/url.csv', index = "ID")
print(data.head()) #默认前五行 ,可设置
print(data.tail())
print(data.shape) #输出几行几列
print(data.columns) #输出列名
import pandas as pd
s1 = pd.Series([1, 2, 3], index=[1, 2, 3], name = "A")
s2 = pd.Series([10, 20, 30], index=[1, 2, 3], name = "B")
s3 = pd.Series([100, 200, 300], index=[1, 2, 3], name = "C")
df = pd.DataFrame([s1,s2,s3])
print(df)
运行结果:
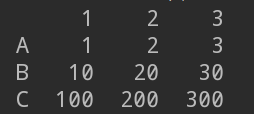
import pandas as pd
s1 = pd.Series([1, 2, 3], index=[1, 2, 3], name = "A")
s2 = pd.Series([10, 20, 30], index=[1, 2, 3], name = "B")
s3 = pd.Series([100, 200, 300], index=[1, 2, 3], name = "C")
df = pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3})
print(df)
运行结果:

import pandas as pd
s1 = pd.Series([1, 2, 3])
print(s1)
s2 = {"A":1, "B":2, "C":3}
print(s2.keys())
print(s2.values())
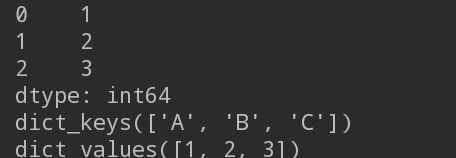
import pandas as pd
s1 = pd.Series([1, 2, 3])
print(s1.index[0])
print(s1.values[0])
s2 = {"A":1, "B":2, "C":3}
print(s2.keys())
print(s2.values())
s3 = pd.Series(s2)
print(s3)
运行结果:
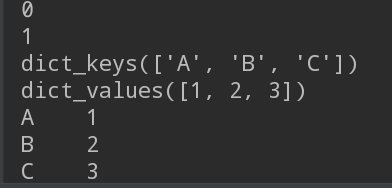
data["ID"][2] = data["ID"].at[2]
books= pd.read_excel("C:/Users/Administrator/Desktop/books.xlsx",index_col="ID")
#books["总价"] = books["单价"]*books["数量"] #使用于列运算
for i in books.index: #(使用于对特定单元格进行计算)
books["总价"].at[i] = books["单价"].at[i]*books["数量"].at[i]
print(books)
def add2(x):
return x+2
print(books)
#books["单价"] = books["单价"]+2
#等用于books["单价"] = books["单价"].apply(add2)
#等同于books["单价"] = books["单价"].apply(lambda x : x+2)
import pandas as pd
books= pd.read_excel("C:/Users/Administrator/Desktop/books.xlsx",index_col="ID")
books.sort_values(by=["值得于否","单价" ],inplace=True ,ascending = [True,False])
#inplace = True在当前books上进行排序,不生成新的.默认是从小到大排序=ascend = True
print(books)
#Excel筛选
import pandas as pd
books= pd.read_excel("C:/Users/Administrator/Desktop/books.xlsx",index_col="ID")
print(books)
def age_10_to_30(a):
return 10<=a<=30
def level_a(s):
return 75<=s<=100
books = books.loc[books['Age'].apply(age_10_to_30)].loc[books["Score"].apply(level_a)]
print(books)
相当于
books = books.loc[books['Age'].apply(lambda x :10<=x<30)]. \
loc[books["Score"].apply(lambda y:70<=y<100)]
#制作柱图
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
books= pd.read_excel("C:/Users/Administrator/Desktop/books.xlsx",index_col="ID")
print(books)
books = books.sort_values(by = "Score", ascending = False)
#books.plot.bar(x="Age", y="Score",color="orange",title="成绩与分数的关系")
plt.bar(books.Age, books.Score, color ="orange")
plt.xticks(books.Score, rotation = 90)
plt.xlabel("Score")
plt.ylabel("Age")
plt.title("年龄与成绩", fontsize =16)
plt.tight_layout() #紧凑型布局
plt.show()
制分组柱形图
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
books= pd.read_excel("C:/Users/Administrator/Desktop/books.xlsx",index_col="ID")
print(books)
books.sort_values(by="一", inplace=True, ascending =False )
books.plot.bar(x="Student", y=["一","二"],color=["orange","black"])
plt.title("学生与成绩", fontsize =16,fontweight="bold")
plt.xlabel("学生", fontweight="bold")
plt.ylabel("成绩", fontweight="bold")
ax = plt.gca() #获取轴
ax.set_xticklabels(books["Student"],rotation=45, ha="right")
f = plt.gcf()#调上下大小间距
f.subplots_adjust(left =0.2, bottom =0.3)
#plt.tight_layout()
plt.show()
