目录
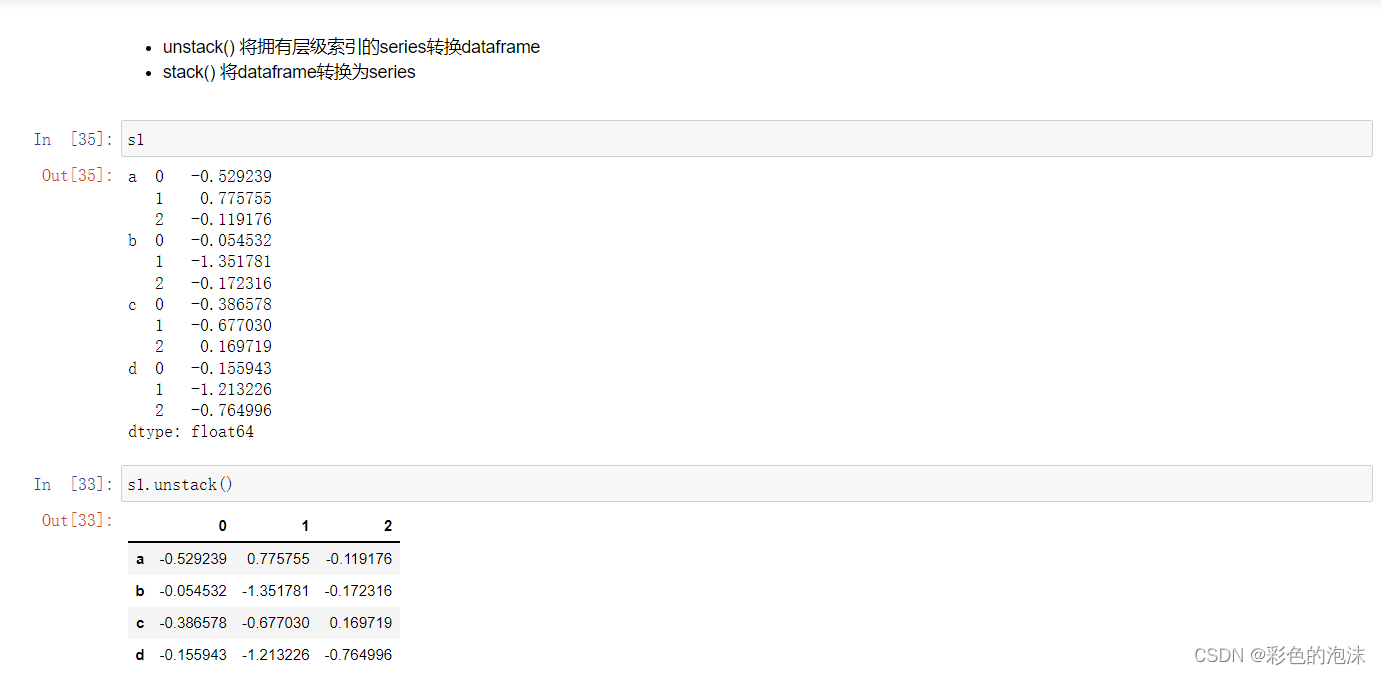
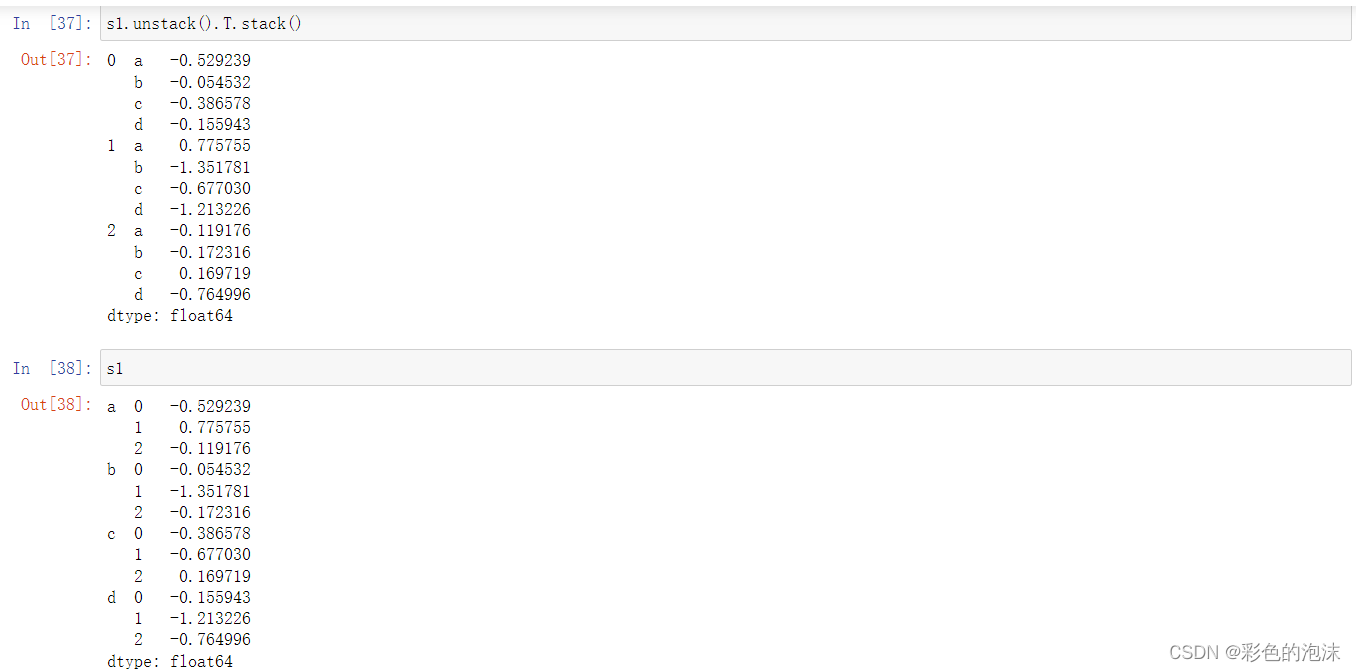
索引与分层索引
索引
- 查看索引:df.index
- 指定索引:df.index = [,] 个数必须一致
- 重置索引:df.reset_index(drop=True) 无需个数一致
- 指定某一列作为index:df.set_index("M",drop=False)
- 返回index的唯一值:df.set_index("M").index.unique()
- df.reset_index():将分层索引层级移动到列中
分层索引
分层索引是Pandas一个重要的特性,允许在一个轴上拥有多个所以层级。

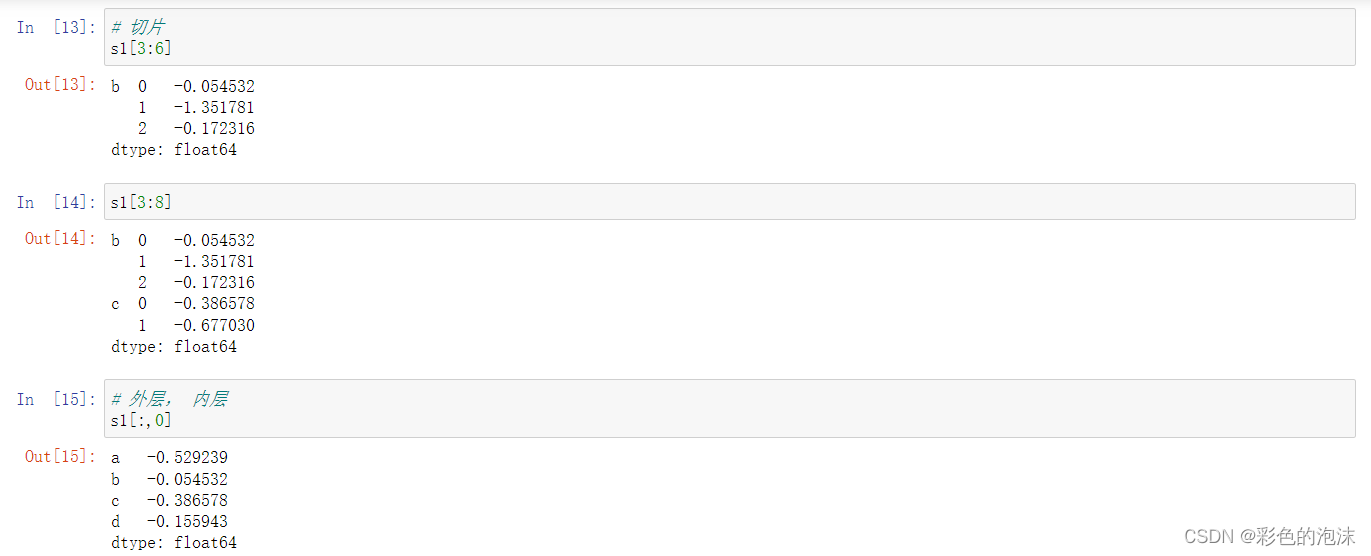
分层索引的切片


数据重塑

数据合并
数据合并也就是说将多个数据集拼接在一起,但是合并的方式主要分为:pandas.merge,pandas.concat,df.join。以下,我们来详细的介绍。
merge()
基于列进行关联,是最常用的一种方法。函数为
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False)- left:拼接左侧的DataFrame对象;
- right:拼接右侧的DataFrame对象;
- on:待关联的同名列名,存在于左右两个DataFrame对象中;
- how:连接方式,inner(默认),其他可选:outer、left、right ;
- left_on:左侧DataFarme中用作连接键的列名;
- right_on:右侧DataFarme中用作连接键的列;
- left_index:将左侧的行索引用作其连接键;
- right_index:将右侧的行索引用作其连接键;




join()
join方法是基于index连接dataframe。join连接方法有内连接,外连接,左连接和右连接,与merge一致。


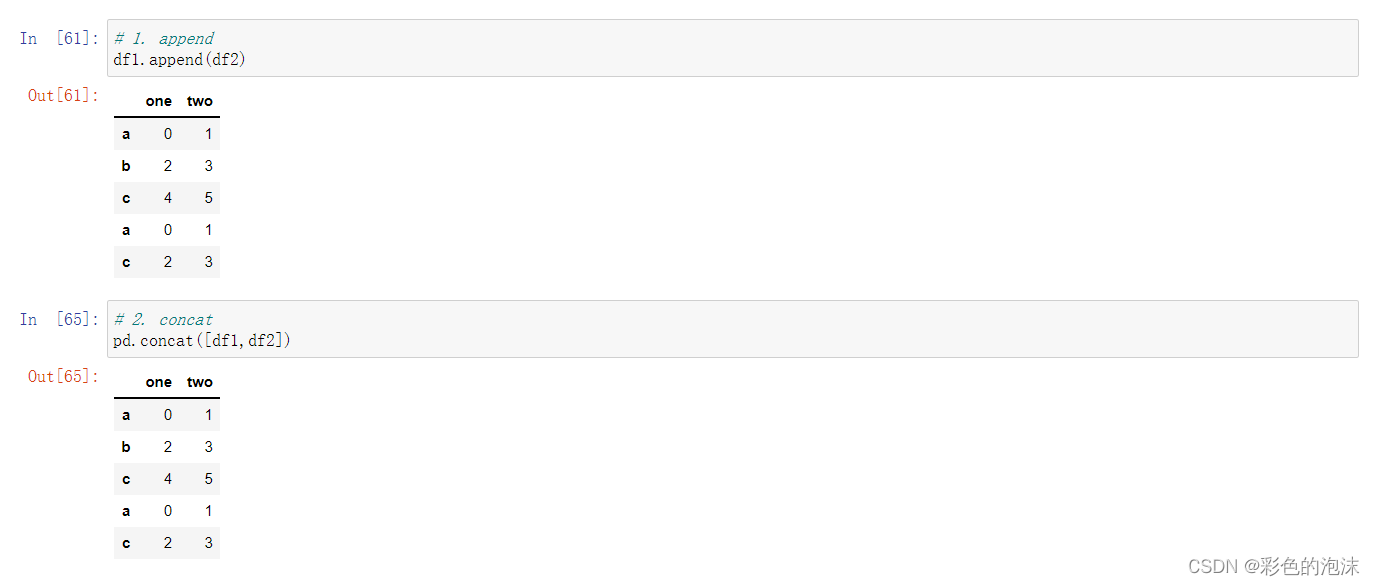
concat()
另外一种常用的数据整合方法是concat,即我希望按照某种方式把两个规整的数据集进行拼接。拼接原型函数非常简单:
pd.concat(objs, axis=0, join='outer', keys=None)- objs:带拼接的数据集,通常以列表的形式传入;
- join:可选inner、outer,含义同merge函数;
- keys:定义新的分组索引,用来区分传入的数据集;

数据的分组与聚合
数据包含在Series、DataFrame数据结构中,可以根据一个或多个键分离到各个组中。分组操作之后,一个函数就可以应用到各个组中,产生新的值。如下图则是简单的分组聚合过程。
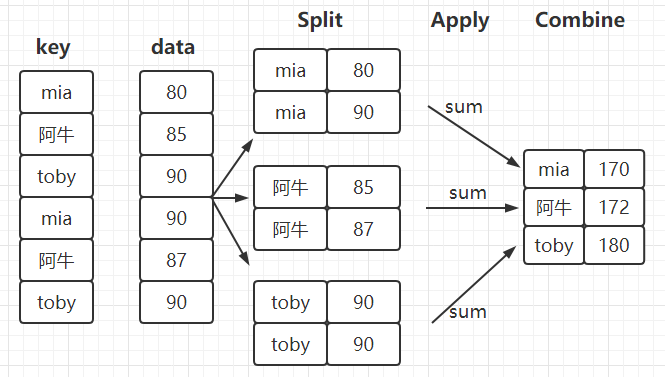
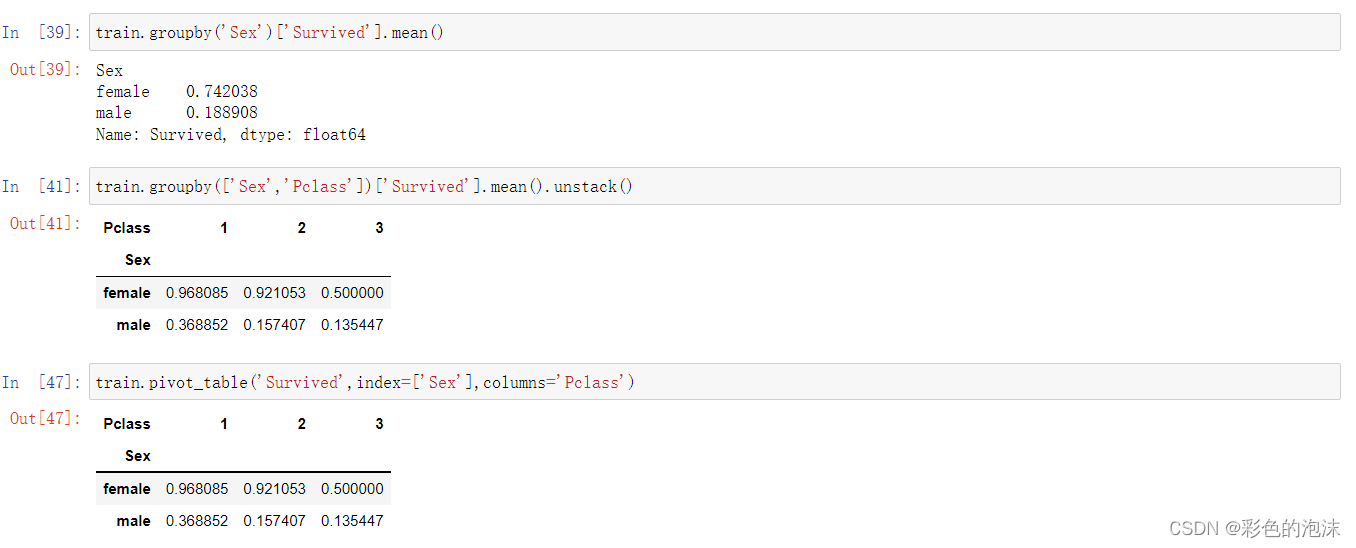
- df.groupby('key') key为指定分组的列
import pandas as pd
import numpy as np
df1 = pd.DataFrame(
{
"names":["菲菲","小可爱","mia","牛哥","老王","mia","狼人","药水哥","药水哥"],
"classes":["一班","二班","三班"]*3,
"grades":np.random.randint(60,100,size=9)
}
)
df1
df1.groupby(by="classes")["grades"].mean()聚合函数如下:
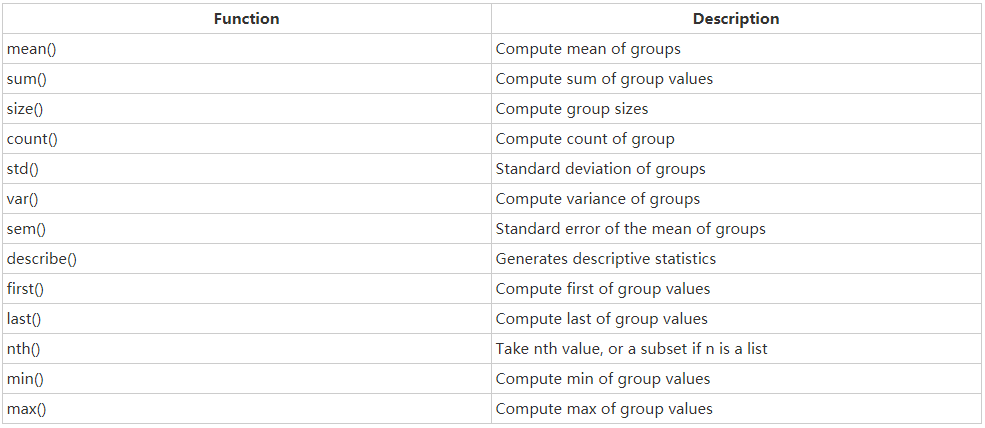
自定义聚合函数
实现步骤:
- 自定义函数
- 分组后通过apply,agg或者aggregate进行聚合
def classes_ptp(x):
return x.max()-x.min()
df1.groupby(by="classes")["grades"].apply(classes_ptp)
df1.groupby(by="classes")["grades"].agg(classes_ptp)
df1.groupby(by="classes")["grades"].aggregate(classes_ptp)数据透视表
- 一种可以对数据动态排布并且分类汇总的表格格式
- pivot_table() 方法
- 不常用