1.pd.read_csv(“文件名.csv”)
返回数据类型:DataFrame:二维标记数据结构,列可以是不同的数据类型
代码将有列索引但没有行索引的数据,read_csv会自动添加上行索引(即使原数据有行索引)。
可选参数
1 names 指定列索引的名字
2 header
header=None 即指明原始文件数据没有列索引
obj_2=pd.read_csv('f:/ceshi.csv',header=None,names=range(2,5))
print obj_2
2 3 4
0 c1 c2 c3
1 0 5 10
2 1 6 11
3 2 7 12
4 3 8 13
5 4 9 14
作者:yuanCruise
链接:https://www.jianshu.com/p/9c12fb248ccc
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
header=0
表示文件第0行(即第一行,索引从0开始)为列索引,这样加names会替换原来的列索引。
obj_2=pd.read_csv('f:/ceshi.csv',header=0,names=range(2,5))
print obj_2
2 3 4
0 0 5 10
1 1 6 11
2 2 7 12
3 3 8 13
4 4 9 14
2.grid=sns.facegrid(dataframe,row=(按行分的标签),col(按列分的标签),hue=(同一个图上不同的类型,size=图的大小)
grid.map(画图方法,横坐标,(纵坐标(如果需要)),(同一图上不同类型))
grid.add_legend() 加同一张表上不同类型数据的图例
grid = sns.FacetGrid(data_all, row='Sex', col='Pclass',
hue='Survived', palette='seismic', size=4)
grid.map(sns.countplot, 'Embarked', alpha=0.8)
grid.add_legend() hue
---------------------
作者:李威威
来源:CSDN
原文:https://blog.csdn.net/lw_power/article/details/82995772
版权声明:本文为博主原创文章,转载请附上博文链接!

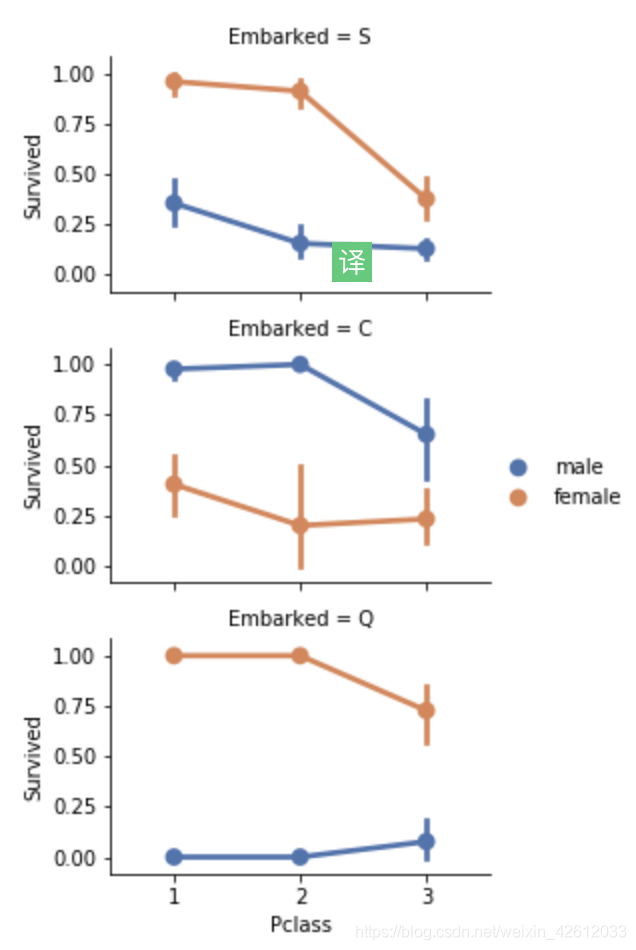
grid = sns.FacetGrid(train_df, row='Embarked', size=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()
#探索Embarked和survived之间的影响关系
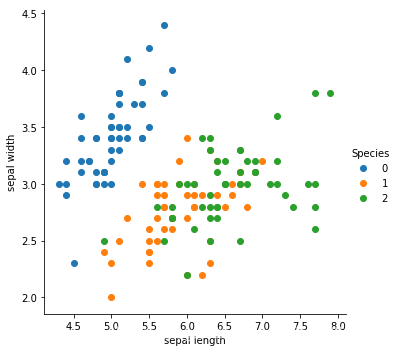
sns.FacetGrid(dataset, hue= 'Species', size = 5).map(plt.scatter, 'sepal length', 'sepal width').add_legend()
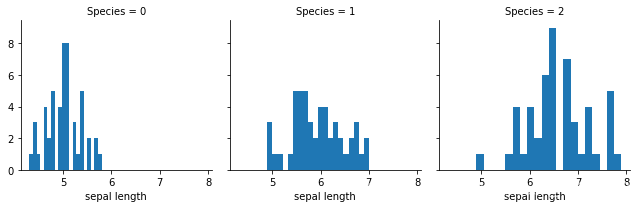
'''描述sepal length和类别之间的关系 FacetGrid,根据'''
g = sns.FacetGrid(dataset, col = 'Species')
g.map(plt.hist, 'sepal length', bins = 20)
bins 图分成多少段