一、分析目的
了解数据分析这个职位的招聘情况以及发展前景。
二、分析维度
根据分析目的,主要提出了以下三个分析维度:
1、职位地区分布
主要对地区进行分组,对各地区职位分布数量进行对比分析;
2、工资待遇
通过对最低薪酬进行描述分析,观察整体的一个最低工资分布;
3、工作年限要求
通过对工作年限进行分组,观察岗位需求主要分布在哪几个年限段,并对工作年限对工资的影响进行了分析,有助于自己今后对职业进行规划;
4、技能要求
主要了解进入该行业所需要必备的技能;
5、学历要求
了解该职位对学历的最低要求;
6、公司福利待遇
主要分析大部分公司给与的福利有哪些,共同点是什么。
三、分析工具
这里主要想熟悉python的使用,所以主要使用了python中的pandas包、以及matplotlib。
四、数据清洗
1、数据集描述
数据集名称:拉勾网数据分析招聘情况
数据集来源:通过八爪鱼爬取拉勾网数据分析招聘数据(对于python爬虫还不太熟悉)
数据集量:431*9
2、添加列
2.1、添加最高工资(high_salary)列和最低工资(low_salary)列;
由于需要分析最低工资情况,而数据表中是按范围给出的(图a),因此需要将工资范围拆分为最高工资(high_salary)和最低工资(low_salary)(图b)。
2.2、添加地区(location)列
数据表中的地区是按每个区域的详细信息给出的(图a),而我只需要分析整个区域的情况,因此需要将区域信息中的详细信息去掉,添加location列(图b)。

图a

图b
3、处理’工作年限’列中多余字符
将’工作年限一列中的’经验’(图a)去掉(图b)。
4、处理缺失值
经过检查未出现缺失值。
5、处理重复值
未出现重复记录
五、数据分析
1、对职位的地区分布进行分析:

通过以上分析可以看出:北京和上海对数据分析岗位需求较大,其次就是广州、深圳、杭州了,如果对地区没有特别要求的话,还是很建议去北京上海等地区发展的。
2、对工资待遇进行分析
由于获取的数据是一个最低到最高工资的区间,所以本文只对最低工资进行了分析;
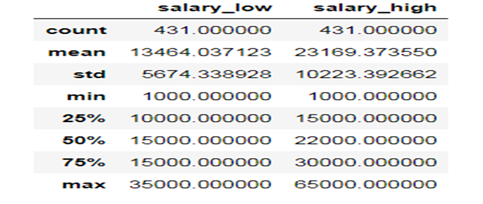
从上表可以看到最低工资是1000(实习生),最高工资是65000,平均工资在13k-22k,所以说该职业的薪资情况还是很可观的。
3、工作年限要求
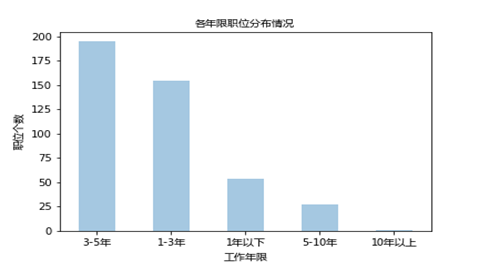
通过分析可以看出:公司对该职位的工作年限要求主要集中在1-5年,3-5年的需求最多,其次是具有1-3年工作经验的,对于一年以下工作经验的需求量很少,5年以上需求基本上就呈现下降趋势了,基本上不需要十年以上工作经验的员工;所以打算入行的需要做好自己的职业规划,在工作中积累经验。
另外,还分析了薪资随着工作年限的变化情况,由于获取的数据是一个最低到最高工资的区间,所以只对最低工资进行了分析;如下:
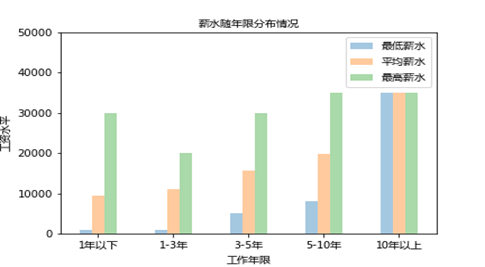
由此看出:在10年内,工资无论是从最低工资、最高工资还是平均工资来看,工资水平都是随着工作年限的增加而上涨的,而且上升的幅度很大;由此可知,工作经验非常重要,所以,要做好规划,努力积累经验,至少在十年内,得到的回报是很可观的。
4、技能要求
利用wordart进行分词处理,生成了词云图如下:

从词云图可以看出,进入该行业需要学习的技能有很多,主要共同点就是需要具备统计学、excel、python/R、MySQL(sql)等知识,当然了,这些都只是工具,最重要的是数据分析的思维以及与业务知识的结合,这些都是需要在工作中不断培养的。
5、学历要求
这部分主要想分析哪些学历对该职位来说比较吃香,如下图:
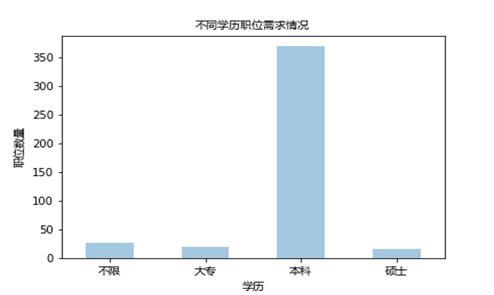
很明显,大多数公司都要求有本科学历,对于大专和学历不限的需求量很少,仅从上图来看,还是有一部分公司对学历的要求是很高的,由此可以看出,该职业对于学历来说,门槛还是相对比较低的。
6、公司福利待遇
这部分依然是采用了词云图的方式来展示公司的福利构成;词云图如下所示:

可以看出,公司的共同点基本上是五险一金、带薪年假、周末双休等,其实从目前所有行业来看,五险一金基本上都是有的,只不过很难找到双休的工作,所以说,从福利来看,如果是更倾向于双休的人士,进入该行业的选择还是没错的,至少从以上分析来看,周末双休的工作还是不少的。
六、结论
通过以上几个方面的分析,大致可以得出以下几点:
(1)数据分析这个行业发展前景是很不错的,薪资水平也相对较高;
(2)就目前分布的区域来看,北上广地区相对来说发展机会多一些;
(3)从入行门槛来看,大部分公司都要求本科学历;
(4)从公司要求来看,除了一些硬性的技能要求外,工作经验也尤为重要;
(5)从各公司福利来看,各公司福利都大同小异。
最后说明一下:本文数据来源于拉勾网,所以大多数是针对的互联网行业,所以分析的不是很全面;另外,由于本人想借此熟悉python相关知识,所以利用的是python相关知识进行分析,但是该数据量很小,完全可以用excel进行分析,还有就是想绘出的图表美观最好使用其他绘图工具,比如pyecharts、tableau以及excel等相关工具。
还有就是想转行的朋友,也包括自己啦,要坚定信心哦,不要半途而废!
import pandas as pd from matplotlib import pyplot as plt from matplotlib import font_manager df = pd.read_excel('C:/Users/Administrator/Desktop/拉勾网数据分析招聘情况(最新).xlsx') salary_low = [] salary_high = [] for i in range(0,len(df)): df1 = df.iloc[i]['工资待遇'].split('-') salary_low .append(df1[0]) salary_high.append(df1[1]) # print(salary_low) # print(salary_high) df['salary_low'] = salary_low df['salary_high'] = salary_high # 将工资中的看转化为'000',才能转化为int类型 df['salary_low'] = df['salary_low'].str.replace('k','000') df['salary_high'] = df['salary_high'].str.replace('k','000') # 将工资列转换为int类型 # df['salary_low'].astype(np.int16) # print(df['salary_high']) # df['salary_high'].astype(np.int64) #方法1 df['salary_low'] = df['salary_low'].astype('i8') #方法2 df['salary_high'] = df['salary_high'].astype('i8') df""" # 将工作地点进行拆分,只对市进行分组 # location = [] # for j in range(0,len(df)): # location1 = df.iloc[j]['工作地点'].split('·') # location.append(location1[0]) # df.insert(2,'location',location) df # 这里把经验不限和应届毕业生改为1年以下 # df['工作年限'] = df['工作年限'].str.replace('经验','') #df['工作年限'] = df['工作年限'].str.replace('不限','1年以下') # df['工作年限'] = df['工作年限'].str.replace('应届毕业生','1年以下') # 查看概况 df.info() # 查看是否重复 df.duplicated() # 删除重复值 df.drop_duplicates() df.shape # 对地区进行一个分组 group_by_location=df.groupby('location')[‘职位名称’].count().sort_values(ascending = False) my_font=font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttf',size = 10) group_by_location.plot(kind = 'bar',title = '岗位分布',label = '个数',alpha = 0.4,rot = 45) plt.title('各地区职位分布',fontproperties = my_font) plt.legend(prop = my_font,loc = 'upper right') plt.xticks(fontproperties = my_font) plt.xlabel('区域名称',fontproperties = my_font) plt.savefig('./picture1.png') plt.show() # 查看下工资的大概情况 df.describe() <代码> # 工作年限要求 df.groupby('工作年限')['公司名称'].count().sort_values(ascending = False).plot(kind = 'bar',alpha = 0.4,rot = 0) # 对中文标签进行处理 plt.xlabel('工作年限',fontproperties = my_font) plt.ylabel('职位个数',fontproperties = my_font) plt.xticks(fontproperties = my_font) plt.title('各年限职位分布情况',fontproperties = my_font) plt.savefig('./picture2') plt.show() # 工作经验与最低薪水之间的相关性 y1 = df.groupby('工作年限')['salary_low'].agg([('最低薪水','min'), ('平均薪水','mean'), ('最高薪水','max')]).sort_values(by = '平均薪水') y1.plot.bar(alpha = 0.4,rot = 0) plt.xticks(fontproperties = my_font) plt.xlabel('工作年限',fontproperties = my_font) plt.ylabel('工资水平',fontproperties = my_font) plt.title('薪水随年限分布情况',fontproperties = my_font) plt.legend(loc = 'upper right',prop = my_font) # 调整纵坐标刻度范围 plt.ylim(ymax = 50000) plt.savefig('./picture3') plt.show() df.groupby('学历要求')['公司名称'].count().plot.bar(alpha = 0.4,rot = 0) plt.xticks(fontproperties = my_font) plt.xlabel('学历',fontproperties = my_font) plt.ylabel('职位数量',fontproperties = my_font) plt.title('不同学历职位需求情况',fontproperties = my_font) plt.savefig('./picture5') plt.show()