※你发现用python爬虫下载一个网页是很容易滴,但是要在网页中查找到你需要的内容,那就是困难的,可以发现字符串查找并没有我们想象中那么简单,并不是直接使用find方法找到匹配字符串的位置接可以了
※比如你想写一个脚本来自动获取最新的代理ip地址,但是肯定会遇到困难,
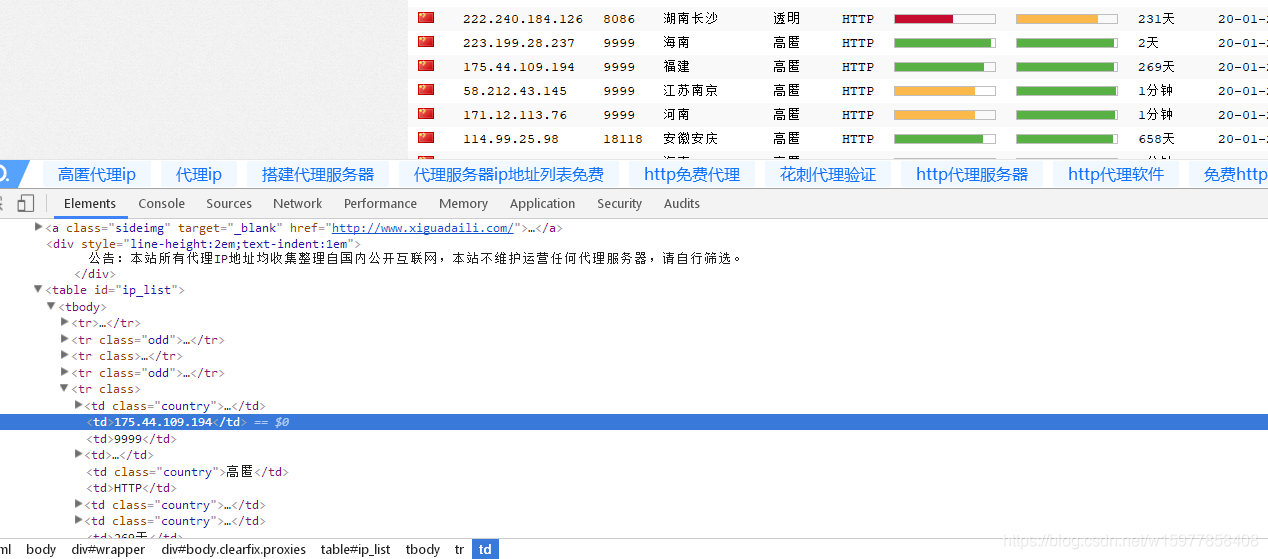
(解析:首先要写个这个爬虫肯定要先去这个网站审查元素踩点,随便选中一个ip审查元素,然后查看这个ip前后有什么标签,可以发现是被td标签包起来了,接着你会发现别的位置也会有td标签,但里边却不是ip而是别的信息,那你可能会花很多时间,先找一个table标签,然后tbody再到tr最后到td标签成功定位了ip地址的唯一特性,但是这样写不仅麻烦,而且有一个很大的问题就是不具备通用性,你在这个网站可行,在另外的网站就不可行了,
所以最好是可以按照自己需要的内容特征来进行自动查找,也就是说我要找一个ip地址,那这个ip地址的特征就是有四段组成,每段数字的范围是0~255,分别是三个英文的句号隔开,这就ip地址的特征嘛,然后就可以根据这个特征再去网页里边查找,但是字符串所附带的方法是无法做到的,但是呢,我们遇到的问题,计算机老前辈们也早就已经想到了,并且已经帮我们设计出了非常优秀的解决方案,那就是使用正则表达式)
※正则表达式很难学,但是却非常有用,在编写处理字符串程序或网页的时候,经常会有查找符合某些复杂规则字符串的需要,例如刚刚说的ip地址的特征和规则,如果使用 Pythob 自带的字符串方法,你一定会恼羞成怒,那么这时候,如果你懂得正则表达式,你会发现,这真是灵丹妙药啊。因为正则表达式就是用于描述这些复杂规则的一个 工具,正则表达式本身就是用于描述这些规则的,不同的编程语言也都有使用正则表达式的方法,但各不相同,Python 的话是使用 re 模块来实现的
※search():用于在字符串中搜索正则表达式模式第一次出现的位置
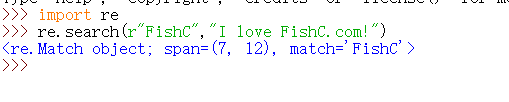
(第一个参数就是正则表达式模式,也就是你要描述的搜索规则,这里需要使用原始字符串r来编写,这样可以避免很多不必要的麻烦,上面匹配的就是(7~12),找不到就会返回None,)
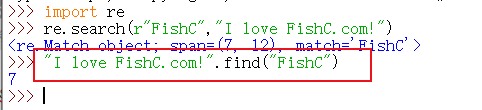
(find方法也可以完成,但显示的是起始地址)
※通配符.,可以可以匹配除了 换行符 以外的任何字符。
(通配符* 和 ?这一类可以表示任何字符的符号,正则表达式也有所谓的通配符,使用的是点号(.))

(如上第一条语句,他找到了第一个字符I,因为这个(.)代表的是除了换行符之外的任何字符,I就被匹配到了,第二句没加C,(.)也可以匹配出来)

(同时可以通过反斜杠\来,这个时候(.)不再代表其他字符,就代表他本身,也就是说在正则表达式中,反斜杠仍然具有剥夺元字符的能力,元字符就是它本身代表着其他含义、有特殊功能的字符,例如 点号(.))

(解析:反斜杠还可以使得普通的字符用于特殊的能力,例如想要匹配到数字,就可以使用反斜杠加上一个d,来匹配任何数字)
※尝试匹配ip地址

(解析:可以看到匹配成功了,但这么写是有问题的,首先\d表示匹配的数字是0-9,而IP地址的约定范围是0-255,现在这里 \d\d\d 最大匹配数字是 999,而范围是最大范围才是255,然后第二个,你这里要求 ip 地址每组必须有三位数字,但实际上有些 ip 地址中的某组数字只有 1 位或者 2 位,这样就匹配不了)
※为了表示一个字符串的范围,我们可以创建一个叫做 字符类 的东西,使用中括号[] 来创建一个字符类,字符类的含义就是你只要匹配字符类中的一个字符,那么就算匹配

(可以看到正则表达式 是默认开启 大小字母敏感 模式的)
※可以在字符类中使用 横杆 ‘-’ 表示一个范围
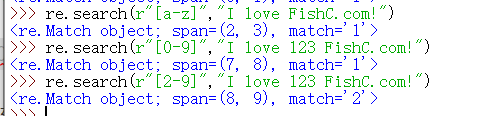
※使用大括号来解决限定重复匹配的次数

(解析:大括号里边的3表示的重复的次数,表示的前面的那个字符也就是b重复的次数,然后a和c没有那都是一次,所以匹配出了一个a三个b一个
c,第二句就匹配不到了因为b的重复次数超过了3)
※大括号里还可以给出重复匹配次数的范围

(解析:{3,10}表示的就是只要它前面那个字符b出现了3-8次都是可以匹配到的,然后a和c也只是一次)
※使用正则表达式来匹配 0~255

(解析:这两种方式都是错误的,匹配不到,因为正则表达式匹配的是字符串,所以呢数字对于字符来说只有0-9,例如123就是有‘1’、‘2’、‘3三个字符来组成的,那么上面的[0-255]这个字符类表示的就是0-2然后还有两个5,所以他就会匹配0125四个数字中的任何一个,所以得了个1)

(解析:[01]\d\d|2[0-4\d|25[0-5]]首先这个东东要分三个部分来看,第一部分是[01]\d\d,也就是可以匹配到百位上是0开头或者1开头,然后十位上是\d也就是0-9中的任意数字,个位也一样,所以这一部分表示数的范围就是000-199,接着第二部分和第一部分用逻辑或|接上,第二部分同理,百位上数字只能是2,十位上可以是0-4,个位随意,随意第二步可以匹配到的范围是200-249,第三部分也同理啦,也用逻辑或|连接,第三步就固定了百位和十位,百位只能是2,十位只能是5,个位可以是0-5,所以第三部分的范围是250-255,综合这三部分可以匹配到的范围就是0-255了,, 但是这样写还是有问题,只能要求匹配的数字必须是 3 位的,如下:)

(解析:可以看到88匹配不出,只有写088才可以匹配出来,因为每一位上是默认至少重复一次,所以把百位和十位改为可以重复0-1次就可以了,如下:
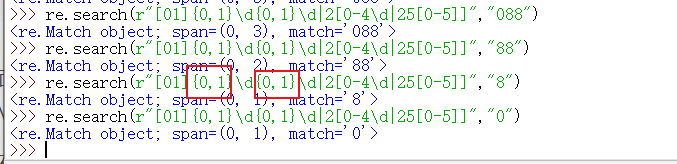
※最后可以来配 完整的IP地址
>>> re.search(r"(([01]{0,1}\d{0,1}\d|2[0-4\d|25[0-5]])\.){3}([01]{0,1}\d{0,1}\d|2[0-4\d|25[0-5]])","192.188.68.3")
<re.Match object; span=(0, 12), match='192.188.68.3'>

(解析:ip地址是有四个部分,如192.188.68.3,每一部分的范围是0-255,所以理论上要写4份一样的,然后他们之间用(.)隔开,然后每一部分用小括号括起来,但是可以看到前三个是一个,如192. 第二个188.,第三个68.所以直接写{3},重复三次就好,然后第四部分在写一遍,就得到上面的一堆长长的表达式了
