##元字符
所有的元字符包括:. ^ $ * + ? { } [ ] \ | ( )
(另一部分就是 反斜杠加上普通符号组成的特殊符号,它拥有特殊的含义。)
※(.):是匹配除了换行符之外的任何字符。
※| :就相当于逻辑或,

※ 托字符(^):定位匹配,匹配字符串的开始位置,就是用来确定一个位置)。
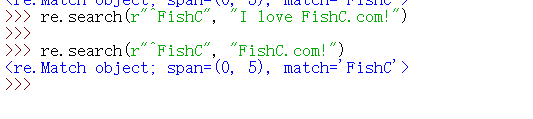
(第一句的时候匹配不了,因为托字符他是定位要确定他前面的那个是字符串的开始位置吗,如就要是F开始)
※ 美元符号($),$ 匹配输入字符串的结束位置.常与托字符(^)一起使用

※小括号(…):跟数学的括号是一样的,把一个东西当做一个整体,那么就把它括起来。
※ 反斜杠(\),反斜杠在正则表达式中应用是最广泛的,它既可以将一个普通的字符变为特殊字符,同时也可以解除元字符的特殊功能
(例如 \. 匹配的就不是除换行符之外的任何字符了,他匹配的就是一个点(.)了)
※如果在反斜杠后面加的是数字,那么还有两种表示方案:
1、如果数字的话呢是 1~99,那么它表示引用序号对应的值组所匹配的字符串
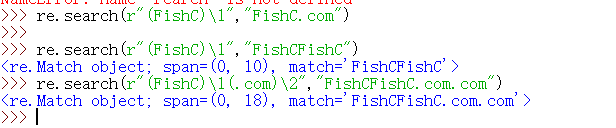
(解析:第一匹配FishC.com是匹配不到的,因为反斜杠加上一个序号,后边的数字是1-99那么他是表示对应的组所匹配的字符串,这里FishC就是第一个组,因为他用括号扩起来,r"(FishC)\1"就等价于r"FishCFishC",序号是从1开始计算的,因为0开始就表示一个八进制数了)
2、如果跟着的数字是 0 或者 3位的数字,那么它是一个八进制数。表示的是这个八进制数对应ASCII码的字符
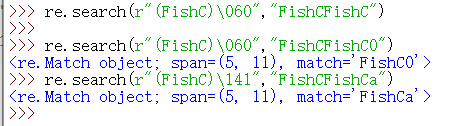
(解析:字符 0 对应的十进制数为 48,对应的八进制数为 60,所以写\60,匹配字符没有0就匹配不到,也可以直接输入三位数也表示三位数,141是ASCII97的八进制表示形式,可以匹配到字符a)
※中括号([ ]):可以用来生成一个字符类
(解析:字符类就是一个字符集合的意思,被他包围在里边的元字符,都会失去特殊功能,就像 反斜杠加上一个元字符是一样的)

(解析:字符类的意思就是将它里面的内容都当做普通的字符看待,除了几个特殊的字符,下面findall方法讲解,如下:)
※findall:在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个列表返回。
1、小横杠(-),我们用它表示范围

2、反斜杠(\),把反斜杠放在字符类[ ]中,它也不是表示本身,否则会报错,反斜杠在字符类里,表示Python 字符串的转义符。比如\n 表示回车的意思

3、托字符 ^,在字符类[ ]里,表示‘除了’也就是取反的意思,但是要注意的是,这个托字符 ^ 必须放在最前面:

(解析:如果放在后面,就是表示匹配托字符它本身:如下:)

※大括号{ }:是用于做重复的事情,如{M,N}(要求M,N均为非负整数,且M<=N)表示前面的RE匹配 M~N次间。
{M,}表示至少匹配M次,
{,N}等价于{0,N},
{N}则表示匹配N次
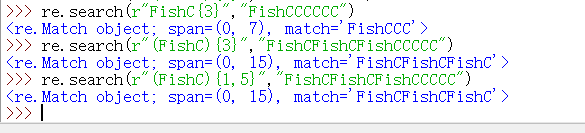
(解析:在正则表达式中,需要注意的是,大家在写编程的时候,可能会注意美观,可能会多加一些空格,但是在正则表达式里面,你千万不能加空格,因为空格会被解析为一个正则表达式)
##特殊的字符
※星号(*):匹配前面的子表达式零次或多次,等价于 {0,}
※加号(+):匹配前面的子表达式一次或多次,等价于 {1,}
※问号(?):匹配前面的子表达式零次或一次,等价于 {0,1}
(在正则表达式中,如果实现条件一样,建议大家使用左边的 * + ?这三个,不要使用 大括号{ }来表示的形式,因为:首先,星号、加号、问号更加简洁;其次,正则表达式内部会对这三个符号进行优化,效率会比使用大括号要高一些。)
##贪婪和非贪婪。
(关于重复这个的操作,有一点需要注意的就是正则表达式默认是启用 贪婪 的模式来进行匹配的)
※贪婪就是贪心,也就是说,只要在符合的条件下,它会尽可能多的去匹配

(解析:比如只想去匹配<html>标签,但他都匹配出来了,因为,+号表示重复前面任何内容,他遇到右尖括号的话,他会停下来,那尽可能多,他就会找找找到最后,然后最后不匹配,再倒着往回,找到第一个匹配的时候,他就停下来,那刚好字符串最后就是个尖括号,所以它匹配了整个字符串,这就是贪婪。)
(既然这样,我们就必须启用 非贪婪模式)
※非贪在表示重复的元字符后面再加上一个问号,这时候,问号就不代表0次或1次了,而是表示启用非贪婪模式:

