※search() :search() 方法既有模块级别的,就是直接调用 re.search() 来实现,然后呢,编译后的正则表达式模式对象也同样拥有 search() 方法,他们之间有区别吗?肯定不是多一个参数的区别
1、模块级别的 search() 方法:re.search(pattern, string, flags=0)
(注意它的参数,它有一个 flags 参数, flags 参数就我们上节课讲得 编译标志位,作为一个模块级别的,它没办法复印,它直接在这里使用它的标志位就可以了。)
※pattern: 是正则表达式的模式
※string :是要搜索的字符串
※ flags: 编译标志位
2、编译后的模式对象的 search() 方法:regex.search(string[, pos[, endpos]])
(可以看到前面的模式对象的参数pattern,就不需要了,因为他是正则表达式编译出来的模式对象。
然后第一个参数就是待搜索的字符串,后面有两个可选参数是我们模块级别的 search() 方法没有的,分别代表了需要搜索的起始位置(pos)和结束位置(endpos,如:
rx.search(string, 0, 50) 或 rx.search(string[:50], 0)
还有就是 search() 方法并不会立刻返回你所需要的字符串,取而代之,它是返回一个匹配对象:如下)

※匹配对象有一些方法,你使用这些方法才能够获得你所需要的匹配的字符串:
※group()方法:

(值的一提的是,如果正则表达式中存在着 子组,子组会将匹配的内容进行捕获,通过这个 group()方法中设置序号,可以提取到对应的子组 捕获的字符串。例如:)

※ start()方法 :返回它匹配的开始位置
※ end()方法 :返回它匹配的结束位置
※ span()方法 :返回它匹配的范围

※findall() 方法:找到所有匹配的内容,然后把它们组织成列表的形式返回
(这是在正则表达式里没有子组的情况下所做的事,如果正则表达式里包含了子组,那么,findall() 会变得很聪明。)
举个例子吧,上贴吧爬图:例如我们想下载这个页
面的所有图片:http://tieba.baidu.com/p/5252578245
还是先踩点:我们看到了,图片开始标签是img,然后就是空格,src得到图片的地址,
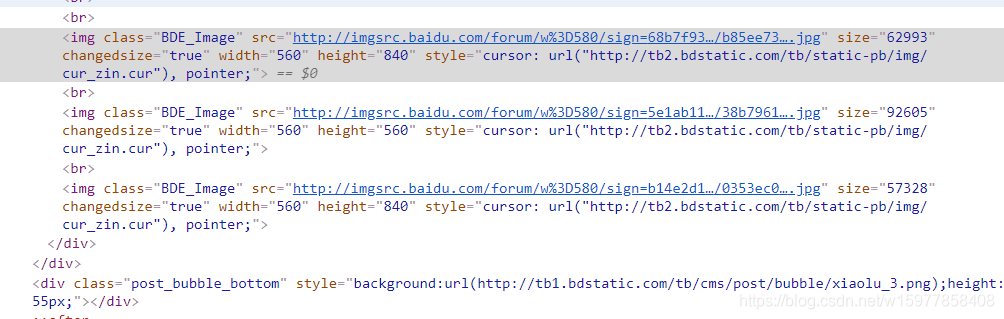
首先先来尝试爬下图片的地址,然后测试:
import urllib.request
import re
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400')
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
return html
def get_img(html):
#爬取图片的正则表达式
p = r'<img class="BDE_Image" src="[^"]+\.jpg"'
imglist = re.findall(p,html)
for each in imglist:
print(each)
if __name__ == '__main__':
url = "http://tieba.baidu.com/p/5252578245"
get_img(open_url(url))
打印测试结果,如下: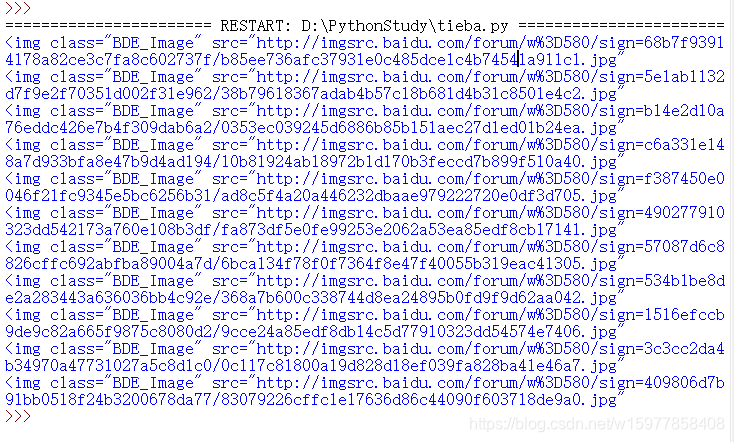
接下来要解决的问题就是如何把里边这些地址给提取出来,因为你直接复制上面一个地址去浏览器打开是下载不了,我们需要的是那个地址才可以访问到图片,改的方法也很简单,如下
p = r'<img class="BDE_Image" src="[^"]+\.jpg"' 改为 p = r'<img class="BDE_Image" src="([^"]+\.jpg)"',
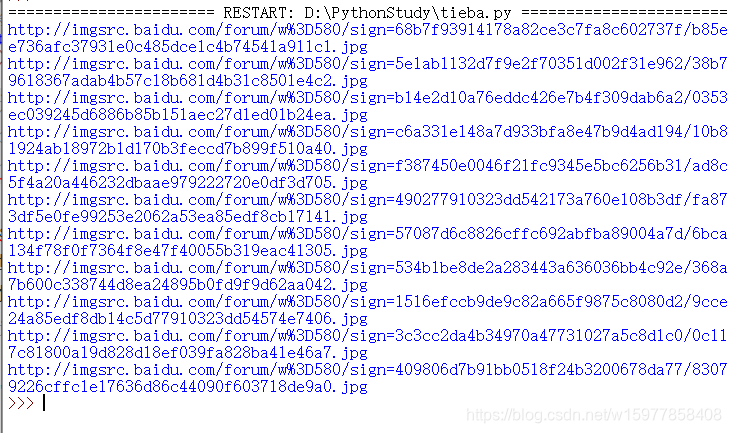
完整代码:运行完,就会在你源文件的位置下载图片了
import urllib.request
import re
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400')
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
return html
def get_img(html):
#爬取图片的正则表达式
p = r'<img class="BDE_Image" src="([^"]+\.jpg)"'
imglist = re.findall(p,html)
'''
for each in imglist:
print(each)
'''
for each in imglist:
filename = each.split("/")[-1] #因为图片的路径都是/隔开的,取最后一个就是文件名
#用urlretrieve()这个方法来获得他的内容,自动下载他的地址
urllib.request.urlretrieve(each,filename,None)
if __name__ == '__main__':
url = "http://tieba.baidu.com/p/5252578245"
get_img(open_url(url))
那为什么加个小括号会如此方便呢?这是因为在 findall() 方法中,如果给出的正则表达式是包含着子组的话,那么就会把子组的内容单独给返回回来。然而,如果存在多个子组,那么它还会将匹配的内容组合成元组的形式再返回。
再举个从国内免费HTTP代理IP中自动获取ip地址的例子
import urllib.request
import re
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400')
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
return html
def get_img(html):
#IP地址的正则表达式
p = r'(([0,1]?\d?\d|2[0-4]\d|25[0-5])\.){3}([0,1]?\d?\d|2[0-4]\d|25[0-5])'
iplist = re.findall(p,html)
for each in iplist:
print(each)
if __name__ == '__main__':
url = "https://www.xicidaili.com/wt/"
get_img(open_url(url))
运行结果:
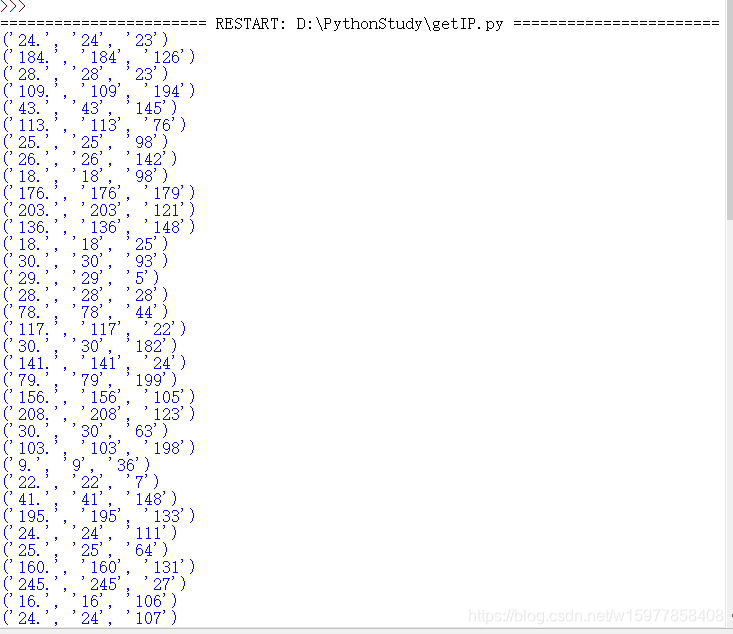
(可以看到让我们很迷茫,为什么会这样呢?这明显不是我们想要的结果,这是因为我们在正则表达式里面使用了 3 个子组,所以,findall() 会自作聪明的帮我们的结果做了分类,然后用元组的形式返回给我们。)
要解决这个问题,我们可以让子组不捕获内容。可以使用拓展语法,那么让子组不捕获内容那也就是非捕获组,扩展语法就是(?:…),如果小括号后面仅跟一个?那么表示为正则表达式的拓展语法,因为问号?是匹配他紧挨他前面的东西一次或者没有,左边是小括号,那么你加个?问号没有意义,因为小括号是元字符。

import urllib.request
import re
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400')
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
return html
def get_img(html):
#IP地址的正则表达式
p = r'(?:(?:[0,1]?\d?\d|2[0-4]\d|25[0-5])\.){3}(?:[0,1]?\d?\d|2[0-4]\d|25[0-5])'
iplist = re.findall(p,html)
for each in iplist:
print(each)
if __name__ == '__main__':
url = "https://www.xicidaili.com/wt/"
get_img(open_url(url))
※finditer()方法:是将结果返回一个迭代器,方便以迭代方式获取数据。
※sub() 方法:是实现替换的操作。
还有一些特殊语法,如下:也可以去Python3 正则表达式特殊符号及用法(详细列表)了解更多

