##网页的异常处理
(高级语言的一个优秀特性就是它可以从容不迫的处理每一个遇到的错误,不至于说因为遇到一个小错误就导致整个程序崩溃了,大部分高级语言处理错误的方法都是通过检测异常、处理异常来实现的,Python也是一样。)
※用程序用代码进行互联网访问的时候,会出现异常那是再正常不过的了,例如说之前实现了一个代理程序,通过十几个、几十个代理 ip 来实现爬虫访问,如果说其中一个代理 ip 突然不响应了,那就会报错,这种错误的触发率是极高的,全部 ip 你都可以使用那才是有鬼咧。但是,出现一个代理 ip 不能用并不会影响到整个脚本的任务,所以我们捕获此类的异常,处理它的方法只需要忽略它就可以了。

※URLError :当我们的 urlopen() 方法无法处理一个响应的时候,就会引发一个 URLError 的异常,通常在没有网络连接、或者对方服务器压根就不存在的时候,就会引发这个异常,同时,这个 URLError 的异常会同时伴随给一个 reason 属性,用于包含由错误编码和错误信息组成的元组。
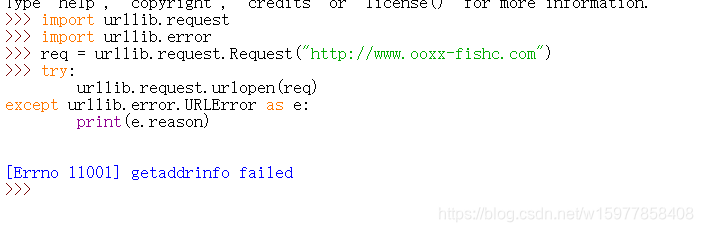
(解析:当我们试图访问一个不存在的域名时,下面的报错11001是错误号,然后伴随的错误信息是 getaddrinfo failed,就是获取地址信息错误,因为压根没有这个域名。)
※ HTTPError:是 URLError 的一个子类,服务器上每一个 http 的响应都会返回一个数字的状态码,例如我们看到的 404,表示资源找不到,有时候状态码会指出服务器无法完成的请求类型,一般情况下,Python 会帮你处理一部分的这类请求,例如说响应一个重定向—>(重定向及其特点) 要求客户端从别的地方来获取文档,那么这个 urllib 模块就会自动帮你处理这个响应,但是,在有一些情况下,它是无法帮你处理的,例如我们刚才说的 404,页面无法找到,它没办法帮你处理,需要你人工来进行过滤。也有 403(请求禁止),401(需要人工验证),想要了解更多最新的状态码,可以去百度搜索HTTP状态码就可以了http://tools.jb51.net/table/http_status_code
(那么当出现一个错误的时候,服务器就会返回一个 HTTP 错误号和错误的页面,你可以使用 HTTPError 实例对象作为页面返回的响应对象,它同样也拥有 read() 和 geturl() 或者说info() 这类方法)
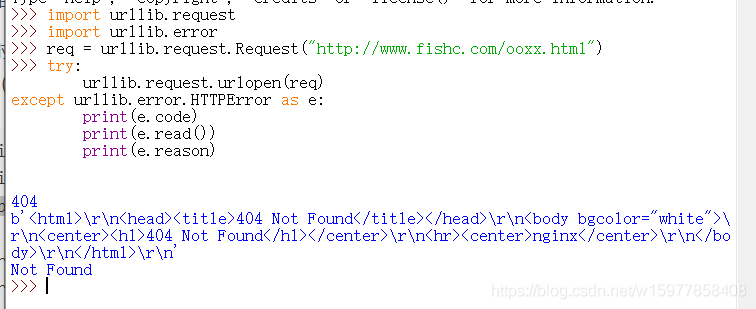
下面总结:
处理异常的第一种写法:
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
req = Request(someurl)
try:
response = urlopen(req)
except HTTPError as e:
print('The server couldn\'t fulfill the request.')
print('Error code: ', e.code)
except URLError as e:
print('We failed to reach a server.')
print('Reason: ', e.reason)
else:
# everything is fine
(这一种写法有一点需要注意的就是:except HTTPError 必须写在 except URLError 的前面,这样才会响应到 HTTPError ,因为 HTTPError是 URLError 的子类,如果 except URLError 写在前面,那么 except HTTPError 永远都响应不了。被上面拦截到了)
处理异常的第二种写法:
from urllib.request import Request, urlopen
from urllib.error import URLError
req = Request(someurl)
try:
response = urlopen(req)
except URLError as e:
if hasattr(e, 'reason'):
print('We failed to reach a server.')
print('Reason: ', e.reason)
elif hasattr(e, 'code'):
print('The server couldn\'t fulfill the request.')
print('Error code: ', e.code)
else:
# everything is fine
(用来hasattr是否拥有这个属性,先看有没有错误(包括URLError 和 HTTPError ),只要有 其中一个,就会打印 reason, 然后继续判断是否有 code ,如果有 code,就是 HTTPError ,然后也把 code 打印出来。第二种比较推荐)
