##Scrapy框架之初窥门径
※使用 Scrapy抓取一个网站一共分为四个步骤:
—创建一个Scrapy项目;
—定义Item容器;
—编写爬虫;
—存储内容。
(学习使用 Scrapy 之前,先来了解一下 Scrapy 框架以及它的组件之间的交互,下面这个图展现的就是 Scrapy 的框架,包括组件以及在系统中发生的数据流。(数据流就是绿色的线,描述各个组件之间是如何通信的))
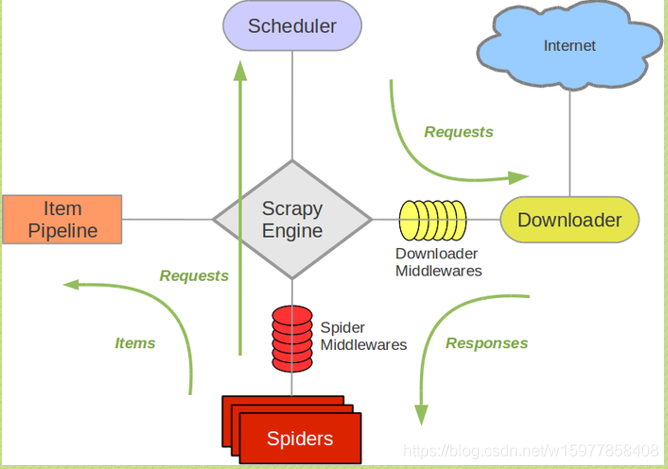
※首先是五个组件
※Scrapy Engine:它是 Scrapy 的核心,爬虫工作的核心。它负责控制数据流在系统中所有组件之间的流动,大家可以看到,无论哪两个组件之间进行交流,都必须经过它。
※Downloader:下载器,下载器负责获取页面的数据,然后提供给 Spiders,数据是从 Scheduler(调度器)这里获得的。
※Scheduler:调度器,是从Scrapy Engine(引擎)这里接收 Requests 数据,事实上,Requests 数据需要的 requests的网页的地址是存放在 Spiders 这里,Spiders 提供给 Scrapy Engine ,Scrapy Engine(引擎)发送 Requests 给 Scheduler(调度器),调度器再把 Requests 传给 Downloader,Downloader 获得内容(也就是 Responses)之后,就发给 Scrapy Engine,然后发给 Spiders 分析。
※Spiders:用于分析下载器返回回来的 Responses,然后提取出 Items 和 需要跟进 的url 的类。
※Item Pipeline:负责处理被 Spiders 提取出来的 Items,Items 就是一个容器,存放我们需要的内容的一个容器,它把 Items 进行存储化,例如存到数据库,存到文件,就是由 Item Pipeline 来处理的。
※两个中间件
(两个中间件事实上就是提供一个简便的机制,通过让你插入自定义的代码来扩展 Scrapy 的功能。)
※Downloader Middlewares:下载器的中间件,是在引擎和下载器之间的 特定钩子,是处理 Downloader 发到引擎的Responses,Responses 要发给 Spiders 需要经过 引擎,下载器中间件就在中间 hook 一下。
※Spiders Middlewares:Spiders 中间件,是处理Spiders 和引擎之间交互的 hook,首先它是接收来自 Downloader 的数据,接收Response 要先从Spiders中间件这里过滤一下,进行额外的操作,然后再给Spiders,然后呢,这个中间件也会接收spiders 的输出,例如 Requests请求的输出和 Items的输出。
##使用Scrapy框架做项目
一、创建一个Scrapy项目
※打开cmd,先创建好tutorial 文件夹。文件夹的位置自己选,可以放在自己专门用来学习的地方,也可以直接放桌面,输入如下命令:
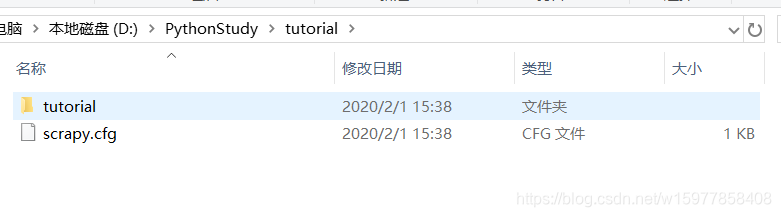
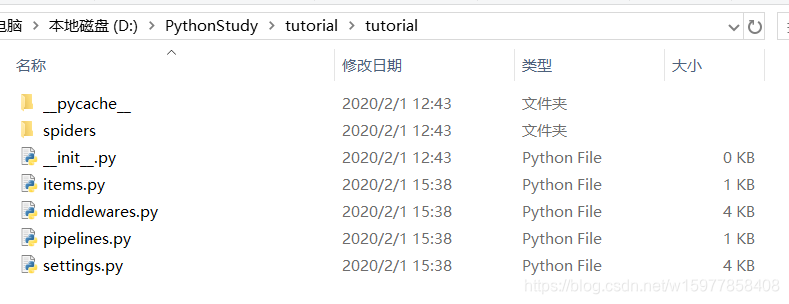
※tutorial 文件夹的目录结构
tutorial/
scrapy.cfg #项目的配置文件
tutorial/ #存放的是模块的代码,也是我们要填充的代码
__init__.py
items.py #是项目中的容器
pipelines.py
settings.py
spiders/
__init__.py
...
二、定义Item容器
(Item是保存爬取到的数据的容器,其使用方法和Python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。)
※首先对你想要获取的数据进行建模
那么我们的任务现在是从这两个网页http://www.dmozdir.org/Category/?SmallPath=242和http://www.dmozdir.org/Category/?SmallPath=226爬取他们的标题,超链接,和描述信息,所以我们就根据这三部分进行建模就可以了
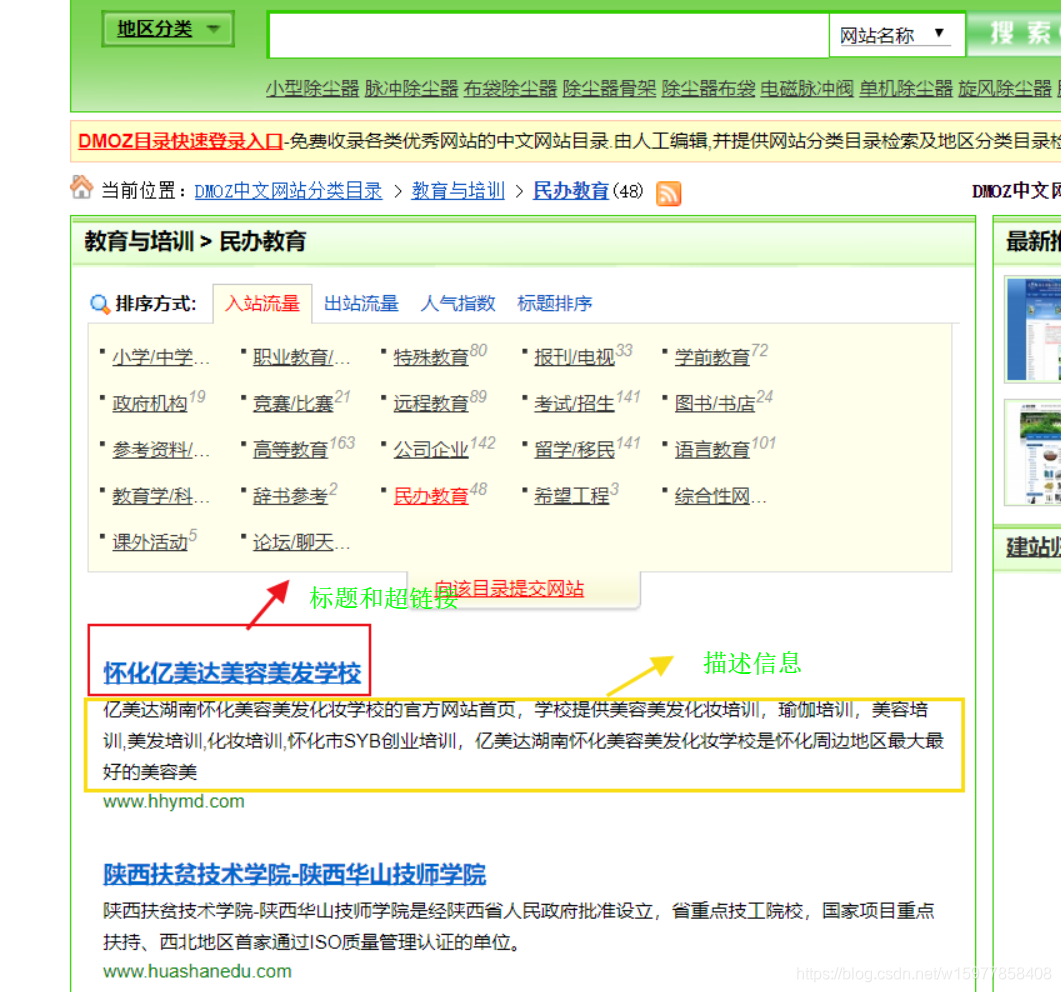
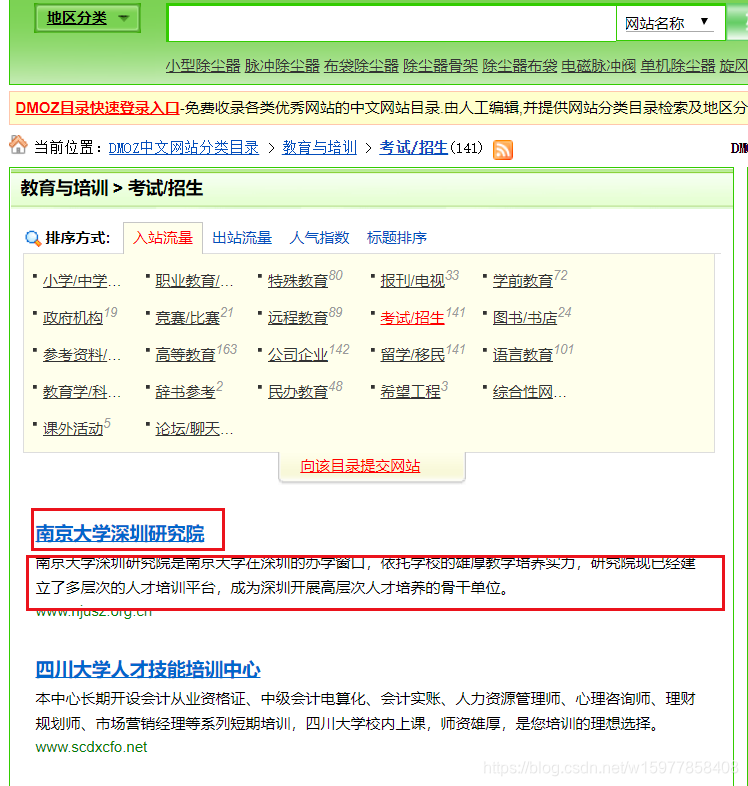
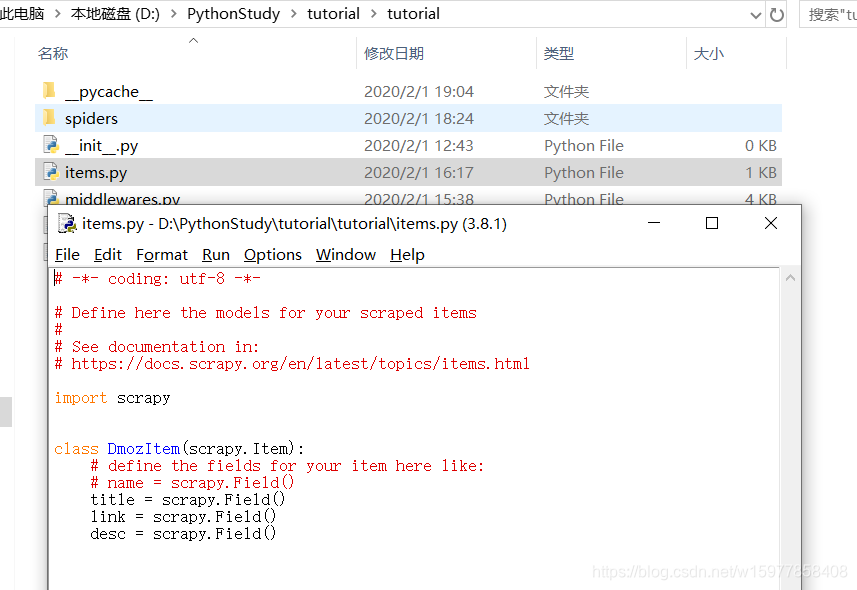
※在 items.py 文件里建立相应的字段:
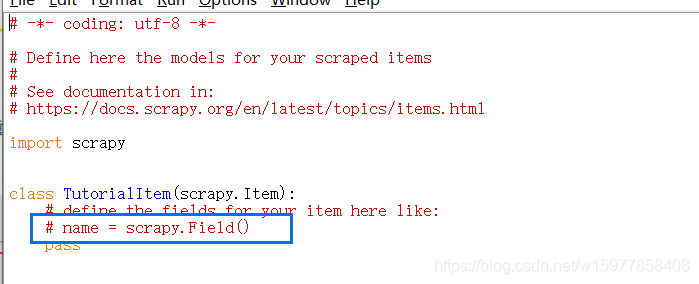
(按照他给的格式左边的name 就是你要建立的字段的名字,scrapy.Field() 就是对应的占位符。)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DmozItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #标题
link = scrapy.Field() #超链接
desc = scrapy.Field() #描述信息
三、编写爬虫
(编写爬虫写在 spiders 文件夹里面,Spider 就是用户编写用于从网站上爬取数据的类。其包含了一个用于下载的初始化的URL,然后是如何跟进网页中的链接以及如何分析页面中的内容,还有提取生成item的方法,这就包含了两个部分)
※第一个部分就是写一个初始化 URL,例如我们初始化需要从刚刚那两个网址URL下载,然后就把它列到 spider 里面,还有就是要写一个方法,如何分析页面中的内容,还有生成 item 。
import scrapy
class DmozSpider(scrapy.Spider):
#爬虫的名字,必须唯一
name = "dmoz"
#蜘蛛爬取的范围
allowed_domains = ["dmozdir.org/Category"]
#开始爬的网址
start_urls = ['http://www.dmozdir.org/Category/?SmallPath=226',
'http://www.dmozdir.org/Category/?SmallPath=242']
#分析的方法,相当于(Spiders组件)
def parse(self,response):
#因为url是以/分隔,然后去/后边的3位做文件名
filename = response.url.split('/')[-1][-3:]
with open(filename,"wb") as f:
f.write(response.body)
(解析代码:首先写一个 Spider 类,这里命名为 DmozSpider,然后要求这个类必须是继承 scray.Spider 类,接着类里边首先要有一个 name,name 这里必须是唯一的,就像我们网页的ID,用来确认蜘蛛的名字。)
(接着有一个 allowed_domains,是一个列表,确定这只蜘蛛要爬取的范围,比如现在要规定只能 爬取在 dmozdir.org/Category 网址里面,这样它在一个网址里面找到其他网页的链接,也不会跑过去了,它只会在这个域名里面去爬,要是没有规定这个的话,蜘蛛爬着爬着就回不来了。)
( start_urls ,这里是开始爬取的网址,规定从哪里开始爬。。)
( 接着我们需要写一个分析的方法叫做 parse,这个方法有一个唯一的参数 response,事实上,我们看一下 Scrapy 的框架图,我们前面写的内容就是由 Scrapy Engine 从 Spiders 提取,然后把它变成 Requests 给 Schedulder,然后我们刚刚说了,downloader 会下载出来的 Reponses 数据给 Scrapy Engine ,然后给 Spiders,我们要一个分析机来处理,这就是我们的parse方法,这个方法接收 Responses,然后对它进行分析处理,并且提取成 Items 给 Item Pipeline,所以我们这里要在这个方法里写一些指定的代码,文件名是取url/的后边三个字符,最后是保存response.body 的内容,response.body 就是这个网页的源代码。)
※爬取分为先爬后取,下面打开cmd测试一下能否爬到:先将目录切到 tutorial 根目录,然后 输入scrapy crawl dmoz:(crawl就是爬的意思,dmoz是刚刚起名的那个蜘蛛,dmoz_spider 里写了一个 name 叫做 dmoz,它就知道调用哪个爬虫去工作了)
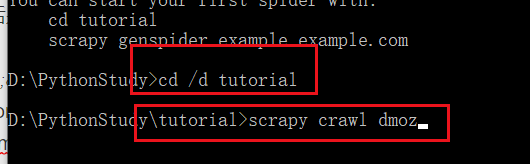
(自己因为电脑问题,需要中间加个//d才能完成切换目录,一般的应该不用加)
2020-02-01 19:04:51 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: tutorial)
2020-02-01 19:04:51 [scrapy.utils.log] INFO: Versions: lxml 4.4.2.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0
2020-02-01 19:04:51 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tutorial', 'NEWSPIDER_MODULE': 'tutorial.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tutorial.spiders']}
2020-02-01 19:04:52 [scrapy.extensions.telnet] INFO: Telnet Password: 639924f998ad51f8
2020-02-01 19:04:52 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2020-02-01 19:04:53 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-02-01 19:04:53 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-02-01 19:04:53 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-02-01 19:04:53 [scrapy.core.engine] INFO: Spider opened
2020-02-01 19:04:53 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-02-01 19:04:53 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-02-01 19:04:53 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2020-02-01 19:04:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=226> (referer: None)
2020-02-01 19:04:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=242> (referer: None)
2020-02-01 19:04:54 [scrapy.core.engine] INFO: Closing spider (finished)
2020-02-01 19:04:54 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 698,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 15099,
'downloader/response_count': 3,
'downloader/response_status_count/200': 3,
'elapsed_time_seconds': 0.982371,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 2, 1, 11, 4, 54, 532880),
'log_count/DEBUG': 3,
'log_count/INFO': 10,
'response_received_count': 3,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/200': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2020, 2, 1, 11, 4, 53, 550509)}
2020-02-01 19:04:54 [scrapy.core.engine] INFO: Spider closed (finished)
中间的内容:

(200就是网页状态码,表示链接成功,后面接的网址跟我们在Spider里编写的两个初始化的网址是一样的,除此看到根目录会发现有两个文件生成,里边分别就是两个网页的源代码)
(刚刚发生的事情就是,首先引擎Scrapy Engin 从Spider 这里获取到两个 初始化的地址,那为什么他知道从那两个地址去获取呢,因为刚才给它的命令是 scrapy crawl dmoz,那它就会来找这个叫做 dmoz 的 spider,所以我们说这个 name 不能重复,重复的话它就不知道找哪一只蜘蛛了,这个 dmoz 是唯一的蜘蛛,它的名字叫做 dmoz。找到它之后,它知道它的两个初始化的地址,所以就提交给 Scheduler,Scheduler 再安排好顺序,发给 Downloader 去下载,下载之后就返回一个 Responses 给 Spiders,Spiders 的这个 parse 方法,其实是个回调函数,当他接收到 Responses 后,就会执行函数体的内容,就会分别保存为两个文件。然后把他接收到的内容写进去,response.body就是网页上的body内容)
※爬完了,接着就要取了
(之前定义好的Item容器)

※下面的任务就是要从这个 226 和 242 这个偌大的内容中找出 title 、link 和 desc ,然后分别保存提取出来,大家知道,这就是一个大浪淘沙的过程。将得到的网页提取出我们需要的数据,之前使用 的是正则表达式,在Scrapy 里面,是使用一种基于 XPath 和 CSS 的表达式机制:Scrapy Selectors。
※Selectors 是一个选择器,它有4个基本方法:
—xpath():传入 xpath 表达式,返回该表达式所对应的所有节点的 selector list 列表。
—css():传入 css 表达式,返回该表达式所对应的所有节点的 selector list 列表。
—extract():序列化该节点为 unicode 字符串并返回 list。
—re():根据传入的正则表达式对数据进行提取,返回 unicode 字符串 list 列表
※为了介绍 selector 的使用方法,接下来我们使用内置的 scrapy shell,首先你需要在CMD中进入项目的根目录,输入:scrapy shell "http://www.dmozdir.org/Category/?SmallPath=226"

D:\PythonStudy\tutorial>scrapy shell "http://www.dmozdir.org/Category/?SmallPath=226"
2020-02-01 19:54:15 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: tutorial)
2020-02-01 19:54:15 [scrapy.utils.log] INFO: Versions: lxml 4.4.2.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0
2020-02-01 19:54:15 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tutorial', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'tutorial.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tutorial.spiders']}
2020-02-01 19:54:15 [scrapy.extensions.telnet] INFO: Telnet Password: e1badfb19e83bab9
2020-02-01 19:54:15 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2020-02-01 19:54:16 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-02-01 19:54:16 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-02-01 19:54:16 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-02-01 19:54:16 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-02-01 19:54:16 [scrapy.core.engine] INFO: Spider opened
2020-02-01 19:54:17 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2020-02-01 19:54:17 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=226> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x0000023A759A39D0>
[s] item {}
[s] request <GET http://www.dmozdir.org/Category/?SmallPath=226>
[s] response <200 http://www.dmozdir.org/Category/?SmallPath=226>
[s] settings <scrapy.settings.Settings object at 0x0000023A759A35E0>
[s] spider <DefaultSpider 'default' at 0x23a75d198e0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>>
(当出现 >>>,就说明已经进入了 shell,在shell 载入之后,你将得到 Responses 回应,我们就可以对它进行操作:
例如,我们输入 response.headers ,就会得到网页的 头:)

>>> response.headers
{b'Cache-Control': [b'private'], b'Date': [b'Sat, 01 Feb 2020 11:53:46 GMT'], b'Content-Type': [b'text/html; Charset=utf-8'], b'Server': [b'Microsoft-IIS/6.0'], b'X-Powered-By': [b'ASP.NET'], b'Set-Cookie': [b'DmozDir=MemHashKey=&MemName=&MemMail=; path=/', b'DmozDirSetting=ViewType=Hide; expires=Sat, 30-Jan-2021 16:00:00 GMT; path=/', b'ASPSESSIONIDAQCCDRBD=PNELGGKCMACCHJKPFPIGGIGL; path=/'], b'Vary': [b'Accept-Encoding']}
输入 response.body,就会得到这个网页的代码:
可以看到这个response.body 很多内容,
我们要从里面找到 title、link 和 desc ,事实上就是一个沙中淘金的过程,所以接下来我们就要找到一个筛子,把沙子给去掉,淘出金子。selector 选择器就是这么一个筛子,正如我们刚才所讲到的,可以使用 response.selector.xpath() 或者 response.selector.css() 或者 response.selector.extract() 或者 response.selector.re() 这四个基本方法来进行筛选。
※ xpath():XPath 是一门在网页中查找特定信息的语言。所以用 Xpath 来筛选数据,比使用正则表达式容易些。
(事实上,你使用正则表达式来查找 html 这类的网页文件的话,经常会出现一些问题,用 XPath 就不会,因为它是针对性的。)
—XPath 表达式的例子,以及对应的含义:
/html/head/title:选择HTML文档中<head>标签中的<title>元素
/html/head/title/text():选择上面提到的<title>元素的文字
//td:选择所有的 <td> 元素
//div[@class="mine"]:选择所有具有 class="mine"属性的 div 元素
(reponse.xpath() 已经映射到了 response.selector.xpath() ,所以,我们以后就直接使用 response.xpath()就好了 )

(上面的语句得到 title,’//标签的名字’ 表示选出这个网页里面所有这个标签的元素,大家可以看到,title只有一个。返回的是一个 Selector 对象的列表。
如果想把这个列表给字符串化,可以使用 extract() ,如下,就得到了一个 unicode 的字符串。 )

(如果想要得到 title 里面的文字(只显示title 的文字,不要标签),如下: )

(非常方便,比你挖空心思去写正则表达式要容易得多,而且不会出错,因为它是根据节点(也就是网页中的标签)来一个一个去查找的。 )
※ 我们接下来就是提取数据了,尝试从页面中提取出对我们有用的数据。你可以从 response.body 里面去找,但我们极力不建议这样做,因为这浪费时间又不讨好,之前不是说了,有一个审查元素吗,我们来看看 我们想要的 title,link 和 desc 的规律。
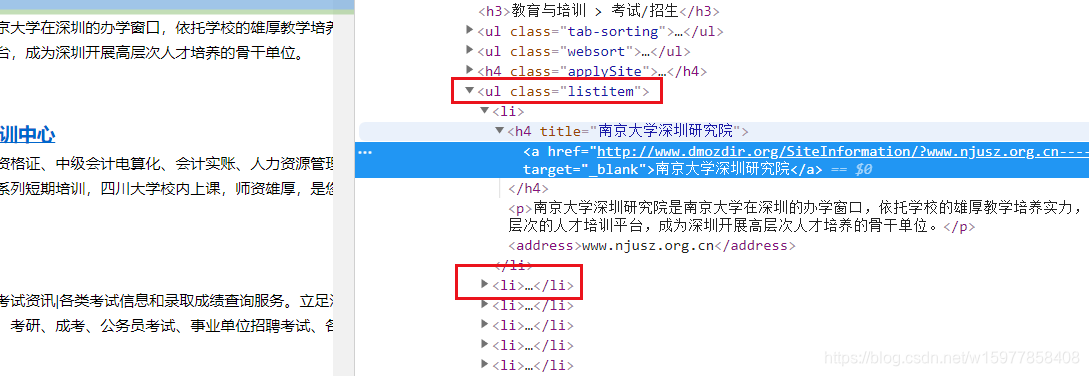
(可以发现,在一个 ul 标签 和 li 标签中间,而且每个 li 标签对应一组数据,所以,我们先找 ul ,再找 li 就对了。 )
>>> response.selector.xpath('//ul/li')
[<Selector xpath='//ul/li' data='<li class="first"><a href="javascript...'>,
<Selector xpath='//ul/li' data='<li><a href="javascript:;" οnclick="c...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/U...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/U...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/U...'>,
<Selector xpath='//ul/li' data='<li class="userinfo">您好,欢迎来DMOZ中文网站分类...'>,
<Selector xpath='//ul/li' data='<li class="thome"><a href="http://www...'>,
<Selector xpath='//ul/li' data='<li class="tadd"><a href="http://www....'>,
<Selector xpath='//ul/li' data='<li class="tline">|</li>'>,
<Selector xpath='//ul/li' data='<li class="tnew"><a href="http://www....'>,
<Selector xpath='//ul/li' data='<li class="tline">|</li>'>,
<Selector xpath='//ul/li' data='<li class="tgoin"><a href="http://www...'>,
<Selector xpath='//ul/li' data='<li class="tline">|</li>'>,
<Selector xpath='//ul/li' data='<li class="tnews"><a href="http://www...'>,
<Selector xpath='//ul/li' data='<li class="tline">|</li>'>,
<Selector xpath='//ul/li' data='<li class="tnews"><a href="http://www...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li class="first">排序方式:</li>'>,
<Selector xpath='//ul/li' data='<li class="check"><a href="?SmallPath...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=226&O=GoO...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=226&O=Dig...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=226&O=Tit...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=216" title="小...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=217" title="职...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=219" title="特...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=220" title="报...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=221" title="学...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=223" title="政...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=224" title="竞...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=225" title="远...'>,
<Selector xpath='//ul/li' data='<li class="check"><a href="?SmallPath...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=228" title="图...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=230" title="参...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=231" title="高...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=233" title="公...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=234" title="留...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=236" title="语...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=237" title="教...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=238" title="辞...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=242" title="民...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=243" title="希...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=244" title="综...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=245" title="课...'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=248" title="论...'>,
<Selector xpath='//ul/li' data='<li><h4 title="南京大学深圳研究院"><a href="ht...'>,
<Selector xpath='//ul/li' data='<li><h4 title="四川大学人才技能培训中心"><a href=...'>,
<Selector xpath='//ul/li' data='<li><h4 title="江西招生考试网"><a href="http...'>,
<Selector xpath='//ul/li' data='<li><h4 title="西安.NET培训"><a href="htt...'>,
<Selector xpath='//ul/li' data='<li><h4 title="北京中清研信息技术研究院广州分院"><a h...'>,
<Selector xpath='//ul/li' data='<li><h4 title="山东专升本考试网"><a href="htt...'>,
<Selector xpath='//ul/li' data='<li><h4 title="软考网-软考信息网-最专业的软考网站"><a...'>, <Selector xpath='//ul/li' data='<li><h4 title="天津大学EMBA深圳教育中心"><a hre...'>,
<Selector xpath='//ul/li' data='<li><h4 title="考试人论坛"><a href="http:/...'>,
<Selector xpath='//ul/li' data='<li><h4 title="南开大学深圳研究院"><a href="ht...'>,
<Selector xpath='//ul/li' data='<li><div class="img-preview"><a href=...'>,
<Selector xpath='//ul/li' data='<li><div class="img-preview"><a href=...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/A...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/U...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/U...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/U...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/N...'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/C...'>,
<Selector xpath='//ul/li' data='<li><a href="javascript:;" target="_s...'>,
<Selector xpath='//ul/li' data='<li><a href="Javascript:;" _fcksavedu...'>]
>>>
(response.selector.xpath(’//ul/li’) 命令就把 response 里面所有的 ul/li 给打印出来了,我们要获得网站的描述的内容(desc),就还需要再加上一个 /p: ,在加个 extract():把他变成一个字符串)
>>> response.selector.xpath('//ul/li/p').extract()
['<p>南京大学深圳研究院是南京大学在深圳的办学窗口,依托学校的雄厚教学培养实力,研究院现已经建立了多层次的人才培训平台,成为深圳开展高层次人才培养的骨干单位。</p>',
'<p>本中心长期开设会计从业资格证、中级会计电算化、会计实账、人力资源管理师、心理咨询师、理财规划师、市场营销经理等系列短期培训,四川大学校内上课,师资雄厚,是您培训的理想选择。</p>',
'<p>江西招生考试网提供招生考试资讯|各类考试信息和录 取成绩查询服务。立足江西省,辐射全国,提供江西省高考、中考、自考、考研、成考、公务员考试、事业单位招聘考试、各类社会考试信息查询的首 选网站。</p>',
'<p>西安.NET技术实训中心是由多名IT精英策划成立的高科技企业,秉承专业、创新的理念,积极开拓,与时俱进,积极投身于软件开发、网站策划、设计、制作、电子商务和企业信息化建设等行业。</p>',
'<p>提供考研,专升本,自考大专的培训机构。北京中清研信息技术研究院主要承办以清华长三角研究院、北京航空航天大学软件学院等机构联合主办的战略管理与产业信息化高管班,战略财务与金...</p>',
'<p>山东专升本,新 明医学专升本,山东医学专升本培训专业品牌,发布山东专升本考试科目、山东专升本学校、山东专升本报名时间、山东专升本考试时间、2013山东专 升本、山东专升本政策信息。</p>',
'<p>软考,软考网,软考信息网,全国软考,软考网络工程师,软考软件设计师,软考网络管理员,软考信息系统监理师,软考程序员,软考系统分析师,软考网络规划师,软考电子商务设计师,软考信息处理技术员</p>',
'<p>天津大学于2010年起在深圳开办EMBA教学项目。深圳作为中国经济特区,已经建设成为中国高新技术产业基地和区域性金融中心、信息中心、商贸中心、运输中心,现代化的国际性城市。</p>',
'<p>升学考试,出国考试,英语考试,等级考试,资格考试,考研,高考,成人高考,考博士,硕士研究生考试,TOEFL,GRE,GMAT,教育,培训,辅导班,托福 考试,雅思考试</p>',
'<p>南开大学深圳研究院是南开大学在深圳的直属单位,主要开展高级工商管理硕士EMBA,在职金融硕士、高层次培训等办学项 目和科技成果转化。</p>']
>>>
(如果再加上 text() ,就可以只显示文本内容,删除了标签 p)
>>> response.selector.xpath('//ul/li/p/text()').extract()
['南京大学深圳研究院是南京大学在深圳的办学窗口,依托学校的雄厚教学培养实力,研究院现已经建立了多层次的人才培训平台,成为深圳开展高层 次人才培养的骨干单位。',
'本中心长期开设会计从业资格证、中级会计电算化、会计实账、人力资源管理师、心理咨询师、理财规划师、市场营销经 理等系列短期培训,四川大学校内上课,师资雄厚,是您培训的理想选择。',
'江西招生考试网提供招生考试资讯|各类考试信息和录取成绩查询服务。立足江西省,辐射全国,提供江西省高考、中考、自考、考研、成考、公务员考试、事业单位招聘考试、各类社会考试信息查询的首选网站。',
'西安.NET技术实训中心是由多名IT精英策划成立的高科技企业,秉承专业、创新的理念,积极开拓,与时俱进,积极投身于软件开发、网站策划、设计、制作、电子商务和企业信息化建设等行业。',
'提供考研,专升本,自考大专的培训机构。北京中清研信息技术研究院主要承办以清华长三角研究院、北京航 空航天大学软件学院等机构联合主办的战略管理与产业信息化高管班,战略财务与金...',
'山东专升本,新明医学专升本,山东医学专升本培训专业品牌,发布山东专升本考试科目、山东专升本学校、山东专升本报名时间、山东专升本考试时间、2013山东专升本、山东专升本政策信息。',
'软考,软 考网,软考信息网,全国软考,软考网络工程师,软考软件设计师,软考网络管理员,软考信息系统监理师,软考程序员,软考系统分析师,软考网络 规划师,软考电子商务设计师,软考信息处理技术员',
'天津大学于2010年起在深圳开办EMBA教学项目。深圳作为中国经济特区,已经建设成为中国高 新技术产业基地和区域性金融中心、信息中心、商贸中心、运输中心,现代化的国际性城市。',
'升学考试,出国考试,英语考试,等级考试,资格考试,考研,高考,成人高考,考博士,硕士研究生考试,TOEFL,GRE,GMAT,教育,培训,辅导班,托福考试,雅思考试',
'南开大学深圳研究院是南开大学在深圳的直属 单位,主要开展高级工商管理硕士EMBA,在职金融硕士、高层次培训等办学项目和科技成果转化。']
>>>
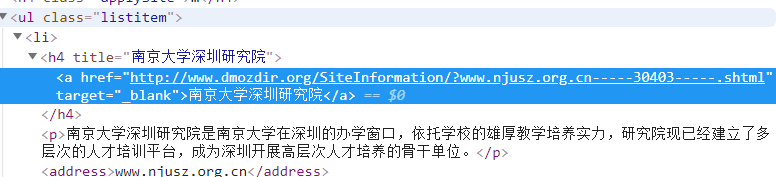
(如果想要得到各网站的标题(title):我们审查元素看到,标题的内容是在 h4 标签里面的 a 标签的文本里面,所以:)
>>> response.selector.xpath('//ul/li/h4/a/text()').extract()
['南京大学深圳研究院',
'四川大学人才技能培训中心',
'江西招生考试网', '西安.NET培训',
'北京中清研信息技术研究院广州分院',
'山东专升本 考试网',
'软考网-软考信息网-最专业的软考网站',
'天津大学EMBA深圳教育中心',
'考试人论坛',
'南开大学深圳研究院']
>>>
(想得到网址的超链接(link),我们可以使用 response.selector.xpath(’//ul/li/h4/a/@href’).extract())
>>> response.selector.xpath('//ul/li/h4/a/@href').extract()
['http://www.dmozdir.org/SiteInformation/?www.njusz.org.cn-----30403-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.scdxcfo.net-----9471-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.jxzsks.com-----9662-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.xapeixun.cn-----13207-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.gd-sinotsing.org-----20495-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.xinmingedu.com-----28769-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.51softexam.com-----14225-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.emba-tjusz.com-----30404-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.examren.com-----22187-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.nkusz.org.cn-----30875-----.shtml']
>>>
上面的命令如果没有假设 extract() ,就是得到 selector 对象的列表,加上 extract() 之后呢,得到的就是 将 selector 对象中的 data 变成字符串 提取出来。
(还可以写一个循环来打印内容:)
>>> a=response.selector.xpath('//ul/li/h4/a/text()').extract()
>>> for each in a:
... print(each)
南京大学深圳研究院,
四川大学人才技能培训中心,
江西招生考试网', '西安.NET培训,
北京中清研信息技术研究院广州分院,
山东专升本 考试网,
软考网-软考信息网-最专业的软考网站,
天津大学EMBA深圳教育中心,
考试人论坛,
南开大学深圳研究院
※接下来就是继续写我们的代码了,使用命令 exit(),退出 shell
(修改我们的 Spider 代码,也就是 dmoz_spider.py。我们就按刚才从 shell 获得的经验来写 parse() 函数。)
import scrapy
class DmozSpider(scrapy.Spider):
#必须唯一
name = "dmoz"
#蜘蛛爬取的范围
allowed_domains = ["dmozdir.org/Category"]
#开始爬的网址
start_urls = ['http://www.dmozdir.org/Category/?SmallPath=226',
'http://www.dmozdir.org/Category/?SmallPath=242']
#分析的方法,相当于(Spiders组件)
def parse(self,response):
titles = response.selector.xpath('//ul/li/h4/a/text()').extract() #标题 title
links = response.selector.xpath('//ul/li/h4/a/@href').extract() #超链接 link
decss = response.selector.xpath('//ul/li/p/text()').extract() #描述 decs
if len(titles) == len(links) == len(decss):
for i in range(len(titles)):
print(titles[i], links[i], decss[i])
(写好之后,保存,进入 CMD,在 tutorial 根目录下执行命令:scrapy crawl dmoz)
D:\PythonStudy\tutorial>scrapy crawl dmoz
2020-02-01 21:26:17 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: tutorial)
2020-02-01 21:26:17 [scrapy.utils.log] INFO: Versions: lxml 4.4.2.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0
2020-02-01 21:26:17 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tutorial', 'NEWSPIDER_MODULE': 'tutorial.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tutorial.spiders']}
2020-02-01 21:26:17 [scrapy.extensions.telnet] INFO: Telnet Password: a670edfc15d56c59
2020-02-01 21:26:17 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2020-02-01 21:26:18 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-02-01 21:26:18 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-02-01 21:26:18 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-02-01 21:26:18 [scrapy.core.engine] INFO: Spider opened
2020-02-01 21:26:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-02-01 21:26:18 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-02-01 21:26:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2020-02-01 21:26:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=226> (referer: None)
南京大学深圳研究院 http://www.dmozdir.org/SiteInformation/?www.njusz.org.cn-----30403-----.shtml 南京大学深圳研究院是南京大学在深圳的办学窗口,依托学校的雄厚教学培养实力,研究院现已经建立了多层次的人才培训平台,成为深圳开展高层次人才培养的骨干单位。
四川大学人才技能培训中心 http://www.dmozdir.org/SiteInformation/?www.scdxcfo.net-----9471-----.shtml 本中心长期开设会计从业资格证、中级会计电算化、会计实账、人力资源管理师、心理咨询师、理财规划师、市场营销经理等系列短期培训,四川大学校内上课,师资雄厚,是您培训的理想选 择。
江西招生考试网 http://www.dmozdir.org/SiteInformation/?www.jxzsks.com-----9662-----.shtml 江西招生考试网提供招生考试资讯|各类考试信息和录取成绩查询服务。立足江西省,辐射全国,提供江西省高考、中考、自考、考研、成考、公务员考试、事业单位招聘考试、各类社会考试信息查询的首 选网站。
西安.NET培训 http://www.dmozdir.org/SiteInformation/?www.xapeixun.cn-----13207-----.shtml 西安.NET技术实训中心是由多名IT精英策划成立的 高科技企业,秉承专业、创新的理念,积极开拓,与时俱进,积极投身于软件开发、网站策划、设计、制作、电子商务和企业信息化建设等行业。
北京中清研信息技术研究院广州分院 http://www.dmozdir.org/SiteInformation/?www.gd-sinotsing.org-----20495-----.shtml 提供考研,专升本,自考大专的培训机构。北京中清研信息技术研究院主要承办以清华长三角研究院、北京航空航天大学软件学院等机构联合主办的战略管理与产业信息化高管班 ,战略财务与金...
山东专升本考试网 http://www.dmozdir.org/SiteInformation/?www.xinmingedu.com-----28769-----.shtml 山东专升本,新明医学专升本,山东医学专升本培训专业品牌,发布山东专升本考试科目、山东专升本学校、山东专升本报名时间、山东专升本考试时间、2013山东专升本、山东专升本政策信息。
软考网-软考信息网-最专业的软考网站 http://www.dmozdir.org/SiteInformation/?www.51softexam.com-----14225-----.shtml 软考,软考网,软考信息网,全国软考,软考网络工程师,软考软件设计师,软考网络管理员,软考信息系统监理师,软考程序员,软考系统分析师,软考网络规划师,软考电 子商务设计师,软考信息处理技术员
天津大学EMBA深圳教育中心 http://www.dmozdir.org/SiteInformation/?www.emba-tjusz.com-----30404-----.shtml 天津大学于2010年起在深圳开办EMBA教学项目。深圳作为中国经济特区,已经建设成为中国高新技术产业基地和区域性金融中心、信息中心、商贸中心、运输中心,现代化的国际性城市。
考试人论坛 http://www.dmozdir.org/SiteInformation/?www.examren.com-----22187-----.shtml 升学考试,出国考试,英语考试,等级考试,资格考试,考研,高考,成人高考,考博士,硕士研究生考试,TOEFL,GRE,GMAT,教育,培训,辅导班,托福考试,雅思考试
南开大学深圳研究院 http://www.dmozdir.org/SiteInformation/?www.nkusz.org.cn-----30875-----.shtml 南开大学深圳研究院是南开大学在深圳的直属单位,主要开展高级工商管理硕士EMBA,在职金融硕士、高层次培训等办学项目和科技成果转化。
2020-02-01 21:26:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=242> (referer: None)
怀化亿美达美容美发学校 http://www.dmozdir.org/SiteInformation/?www.hhymd.com-----21874-----.shtml 亿美达湖南怀化美容美发化妆学校的官方 网站首页,学校提供美容美发化妆培训,瑜伽培训,美容培训,美发培训,化妆培训,怀化市SYB创业培训,亿美达湖南怀化美容美发化妆学校是怀化周边地 区最大最好的美容美
陕西扶贫技术学院-陕西华山技师学院 http://www.dmozdir.org/SiteInformation/?www.huashanedu.com-----21519-----.shtml 陕西扶贫技术学院-陕西华山技师学院是经陕西省人民政府批准设立,省重点技工院校,国家项目重点扶持、西北地区首家通过ISO质量管理认证的单位。
北京化妆学校-MUS时尚造型 http://www.dmozdir.org/SiteInformation/?www.musfr.com-----14968-----.shtml 北京化妆学校-M.U.S时尚造型是全国首 家全法式教学的化妆培训机构。学校集时尚、影视化妆、整体形象设计为一体,从职业规划的角度出发,培养顶尖级化妆造型师。学校特为白领开设一对 一彩妆课程......
苑昕彩妆培训学校 http://www.dmozdir.org/SiteInformation/?www.yxbeauty.com-----39411-----.shtml 苑昕时尚彩妆培训学校成立于连云港,由沙雪带领北京资深彩妆造型团队共创时尚新坐标。校长沙雪有长达二十余年的美术功底,随后开始专研彩妆造型专业,2005年进驻北京时尚界,多年成功的彩 妆教学经验。
阳朔美城英语培训 http://www.dmozdir.org/SiteInformation/?www.mcischool.net-----19196-----.shtml 阳朔英语培训,英语口语培训,英语培训
成都力方数字科技有限公司 http://www.dmozdir.org/SiteInformation/?www.lf-jy.com-----41026-----.shtml 设在环境优美的成都青羊工业总部基地 电子商务大厦力方公司11楼,办公面积1400余平方米,先进教学设备200余件,自有学员宿舍,该网站是力方教育所成立的网站,方便学员更好的了解力方教育
成都驾校学车 http://www.dmozdir.org/SiteInformation/?www.028jiakao.com-----43633-----.shtml 成都驾校一点通,成都学车网,成都驾校考试网上 预约报名,专业成都陪练陪驾公司,选择史老师驾考服务中心。口碑教学,绝不坑爹
郑大一附中 http://www.dmozdir.org/SiteInformation/?www.iuawgwpfn.com-----43397-----.shtml 郑州大学第一附属中学紧紧依靠位居河南教育龙头 的郑州大学,以“团结务实,开拓创新”为校风,以“现代化、高质量、创特色、争一流”为办学目标,以先进的教育理念,一流的师资.
成都世纪精英培训学校 http://www.dmozdir.org/SiteInformation/?www.cdsjjy.com-----13945-----.shtml 我校是一所主要从事白领类职业资格认证和多种成人考试培训的专业机构,同时,也是四川省人事厅批准的“四川省专业技术人员继续教育基地”。
孙进技校 http://www.dmozdir.org/SiteInformation/?www.sunjinxueyuan.com-----13013-----.shtml 孙进技校是全国连锁技工培训学校,包括8大系20多个专业,实践教学培养技工人才
2020-02-01 21:26:20 [scrapy.core.engine] INFO: Closing spider (finished)
2020-02-01 21:26:20 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 698,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 15099,
'downloader/response_count': 3,
'downloader/response_status_count/200': 3,
'elapsed_time_seconds': 1.128977,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 2, 1, 13, 26, 20, 10619),
'log_count/DEBUG': 3,
'log_count/INFO': 10,
'response_received_count': 3,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/200': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2020, 2, 1, 13, 26, 18, 881642)}
2020-02-01 21:26:20 [scrapy.core.engine] INFO: Spider closed (finished)
D:\PythonStudy\tutorial>
(中间的部分和网页对比)
2020-02-01 21:26:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2020-02-01 21:26:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=226> (referer: None)
南京大学深圳研究院 http://www.dmozdir.org/SiteInformation/?www.njusz.org.cn-----30403-----.shtml 南京大学深圳研究院是南京大学在深圳的办学窗口,依托学校的雄厚教学培养实力,研究院现已经建立了多层次的人才培训平台,成为深圳开展高层次人才培养的骨干单位。
四川大学人才技能培训中心 http://www.dmozdir.org/SiteInformation/?www.scdxcfo.net-----9471-----.shtml 本中心长期开设会计从业资格证、中级会计电算化、会计实账、人力资源管理师、心理咨询师、理财规划师、市场营销经理等系列短期培训,四川大学校内上课,师资雄厚,是您培训的理想选 择。
江西招生考试网 http://www.dmozdir.org/SiteInformation/?www.jxzsks.com-----9662-----.shtml 江西招生考试网提供招生考试资讯|各类考试信息和录取成绩查询服务。立足江西省,辐射全国,提供江西省高考、中考、自考、考研、成考、公务员考试、事业单位招聘考试、各类社会考试信息查询的首 选网站。
西安.NET培训 http://www.dmozdir.org/SiteInformation/?www.xapeixun.cn-----13207-----.shtml 西安.NET技术实训中心是由多名IT精英策划成立的 高科技企业,秉承专业、创新的理念,积极开拓,与时俱进,积极投身于软件开发、网站策划、设计、制作、电子商务和企业信息化建设等行业。
北京中清研信息技术研究院广州分院 http://www.dmozdir.org/SiteInformation/?www.gd-sinotsing.org-----20495-----.shtml 提供考研,专升本,自考大专的培训机构。北京中清研信息技术研究院主要承办以清华长三角研究院、北京航空航天大学软件学院等机构联合主办的战略管理与产业信息化高管班 ,战略财务与金...
山东专升本考试网 http://www.dmozdir.org/SiteInformation/?www.xinmingedu.com-----28769-----.shtml 山东专升本,新明医学专升本,山东医学专升本培训专业品牌,发布山东专升本考试科目、山东专升本学校、山东专升本报名时间、山东专升本考试时间、2013山东专升本、山东专升本政策信息。
软考网-软考信息网-最专业的软考网站 http://www.dmozdir.org/SiteInformation/?www.51softexam.com-----14225-----.shtml 软考,软考网,软考信息网,全国软考,软考网络工程师,软考软件设计师,软考网络管理员,软考信息系统监理师,软考程序员,软考系统分析师,软考网络规划师,软考电 子商务设计师,软考信息处理技术员
天津大学EMBA深圳教育中心 http://www.dmozdir.org/SiteInformation/?www.emba-tjusz.com-----30404-----.shtml 天津大学于2010年起在深圳开办EMBA教学项目。深圳作为中国经济特区,已经建设成为中国高新技术产业基地和区域性金融中心、信息中心、商贸中心、运输中心,现代化的国际性城市。
考试人论坛 http://www.dmozdir.org/SiteInformation/?www.examren.com-----22187-----.shtml 升学考试,出国考试,英语考试,等级考试,资格考试,考研,高考,成人高考,考博士,硕士研究生考试,TOEFL,GRE,GMAT,教育,培训,辅导班,托福考试,雅思考试
南开大学深圳研究院 http://www.dmozdir.org/SiteInformation/?www.nkusz.org.cn-----30875-----.shtml 南开大学深圳研究院是南开大学在深圳的直属单位,主要开展高级工商管理硕士EMBA,在职金融硕士、高层次培训等办学项目和科技成果转化。
2020-02-01 21:26:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=242> (referer: None)
怀化亿美达美容美发学校 http://www.dmozdir.org/SiteInformation/?www.hhymd.com-----21874-----.shtml 亿美达湖南怀化美容美发化妆学校的官方 网站首页,学校提供美容美发化妆培训,瑜伽培训,美容培训,美发培训,化妆培训,怀化市SYB创业培训,亿美达湖南怀化美容美发化妆学校是怀化周边地 区最大最好的美容美
陕西扶贫技术学院-陕西华山技师学院 http://www.dmozdir.org/SiteInformation/?www.huashanedu.com-----21519-----.shtml 陕西扶贫技术学院-陕西华山技师学院是经陕西省人民政府批准设立,省重点技工院校,国家项目重点扶持、西北地区首家通过ISO质量管理认证的单位。
北京化妆学校-MUS时尚造型 http://www.dmozdir.org/SiteInformation/?www.musfr.com-----14968-----.shtml 北京化妆学校-M.U.S时尚造型是全国首 家全法式教学的化妆培训机构。学校集时尚、影视化妆、整体形象设计为一体,从职业规划的角度出发,培养顶尖级化妆造型师。学校特为白领开设一对 一彩妆课程......
苑昕彩妆培训学校 http://www.dmozdir.org/SiteInformation/?www.yxbeauty.com-----39411-----.shtml 苑昕时尚彩妆培训学校成立于连云港,由沙雪带领北京资深彩妆造型团队共创时尚新坐标。校长沙雪有长达二十余年的美术功底,随后开始专研彩妆造型专业,2005年进驻北京时尚界,多年成功的彩 妆教学经验。
阳朔美城英语培训 http://www.dmozdir.org/SiteInformation/?www.mcischool.net-----19196-----.shtml 阳朔英语培训,英语口语培训,英语培训
成都力方数字科技有限公司 http://www.dmozdir.org/SiteInformation/?www.lf-jy.com-----41026-----.shtml 设在环境优美的成都青羊工业总部基地 电子商务大厦力方公司11楼,办公面积1400余平方米,先进教学设备200余件,自有学员宿舍,该网站是力方教育所成立的网站,方便学员更好的了解力方教育
成都驾校学车 http://www.dmozdir.org/SiteInformation/?www.028jiakao.com-----43633-----.shtml 成都驾校一点通,成都学车网,成都驾校考试网上 预约报名,专业成都陪练陪驾公司,选择史老师驾考服务中心。口碑教学,绝不坑爹
郑大一附中 http://www.dmozdir.org/SiteInformation/?www.iuawgwpfn.com-----43397-----.shtml 郑州大学第一附属中学紧紧依靠位居河南教育龙头 的郑州大学,以“团结务实,开拓创新”为校风,以“现代化、高质量、创特色、争一流”为办学目标,以先进的教育理念,一流的师资.
成都世纪精英培训学校 http://www.dmozdir.org/SiteInformation/?www.cdsjjy.com-----13945-----.shtml 我校是一所主要从事白领类职业资格认证和多种成人考试培训的专业机构,同时,也是四川省人事厅批准的“四川省专业技术人员继续教育基地”。
孙进技校 http://www.dmozdir.org/SiteInformation/?www.sunjinxueyuan.com-----13013-----.shtml 孙进技校是全国连锁技工培训学校,包括8大系20多个专业,实践教学培养技工人才

※ 上面是爬和取的过程,我们接下来就要使用 Items,我们前面说过,Items 是我们自定义的容器,用法和Python的字典是一样的,我们希望 Spider 将爬取然后筛选后的数据存放到 Items 容器里面,我们刚才也在 parse 里写了筛选出 Items 对应的数据的方法了。筛选之后,我希望将它存放到 Items 里边去。
(items 既是容器,也是一个类,类名我们在这个项目中定义为 DmozItem。
我们需要把 items 导入到 spider 中,才可以使用它,于是,我们在 dmoz_spider.py 文件中写道:)
import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ['dmozdir.org/Category']
start_urls = ['http://www.dmozdir.org/Category/?SmallPath=226',
'http://www.dmozdir.org/Category/?SmallPath=242']
def parse(self, response):
titles = response.selector.xpath('//ul/li/h4/a/text()').extract() #标题 title
links = response.selector.xpath('//ul/li/h4/a/@href').extract() #超链接 link
descs = response.selector.xpath('//ul/li/p/text()').extract() #描述 desc
items = []
if len(titles) == len(links) == len(descs):
for i in range(len(titles)):
#print(titles[i], links[i], decss[i])
item = DmozItem()
#每一组保存为一个字典
item['title'] = titles[i]
item['link'] = links[i]
item['desc'] = descs[i]
#将每个字典添加到列表中
items.append(item)
return items
※ 接着在CMD 中,tutorail 的根目录下,执行命令:scrapy crawl dmoz -o items.json -t json (-o 文件名 -t 保存形式)
D:\PythonStudy\tutorial>scrapy crawl dmoz -o items.json -t json
2020-02-01 21:57:52 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: tutorial)
2020-02-01 21:57:52 [scrapy.utils.log] INFO: Versions: lxml 4.4.2.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0
2020-02-01 21:57:52 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tutorial', 'FEED_FORMAT': 'json', 'FEED_URI': 'items.json', 'NEWSPIDER_MODULE': 'tutorial.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tutorial.spiders']}
2020-02-01 21:57:52 [scrapy.extensions.telnet] INFO: Telnet Password: 9f0ad10fa00439fc
2020-02-01 21:57:52 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats']
2020-02-01 21:57:53 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-02-01 21:57:53 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-02-01 21:57:53 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-02-01 21:57:53 [scrapy.core.engine] INFO: Spider opened
2020-02-01 21:57:53 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-02-01 21:57:53 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-02-01 21:57:53 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2020-02-01 21:57:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=226> (referer: None)
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '南京大学深圳研究院是南京大学在深圳的办学窗口,依托学校的雄厚教学培养实力,研究院现已经建立了多层次的人才培训平台,成为深圳开 展高层次人才培养的骨干单位。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.njusz.org.cn-----30403-----.shtml',
'title': '南京大学深圳研究院'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '本中心长期开设会计从业资格证、中级会计电算化、会计实账、人力资源管理师、心理咨询师、理财规划师、市场营销经理等系列短期培训, 四川大学校内上课,师资雄厚,是您培训的理想选择。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.scdxcfo.net-----9471-----.shtml',
'title': '四川大学人才技能培训中心'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '江西招生考试网提供招生考试资讯|各类考试信息和录取成绩查询服务。立足江西省,辐射全国,提供江西省高考、中考、自考、考研、成考、公务员考试、事业单位招聘考试、各类社会考试信息查询的首选网站。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.jxzsks.com-----9662-----.shtml',
'title': '江西招生考试网'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '西安.NET技术实训中心是由多名IT精英策划成立的高科技企业,秉承专业、创新的理念,积极开拓,与时俱进,积极投身于软件开发、网站策 划、设计、制作、电子商务和企业信息化建设等行业。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.xapeixun.cn-----13207-----.shtml',
'title': '西安.NET培训'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '提供考研,专升本,自考大专的培训机构。北京中清研信息技术研究院主要承办以清华长三角研究院、北京航空航天大学软件学院等机构联合主 办的战略管理与产业信息化高管班,战略财务与金...',
'link': 'http://www.dmozdir.org/SiteInformation/?www.gd-sinotsing.org-----20495-----.shtml',
'title': '北京中清研信息技术研究院广州分院'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '山东专升本,新明医学专升本,山东医学专升本培训专业品牌,发布山东专升本考试科目、山东专升本学校、山东专升本报名时间、山东专升 本考试时间、2013山东专升本、山东专升本政策信息。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.xinmingedu.com-----28769-----.shtml',
'title': '山东专升本考试网'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '软考,软考网,软考信息网,全国软考,软考网络工程师,软考软件设计师,软考网络管理员,软考信息系统监理师,软考程序员,软考系统 分析师,软考网络规划师,软考电子商务设计师,软考信息处理技术员',
'link': 'http://www.dmozdir.org/SiteInformation/?www.51softexam.com-----14225-----.shtml',
'title': '软考网-软考信息网-最专业的软考网站'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '天津大学于2010年起在深圳开办EMBA教学项目。深圳作为中国经济特区,已经建设成为中国高新技术产业基地和区域性金融中心、信息中心、 商贸中心、运输中心,现代化的国际性城市。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.emba-tjusz.com-----30404-----.shtml',
'title': '天津大学EMBA深圳教育中心'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '升学考试,出国考试,英语考试,等级考试,资格考试,考研,高考,成人高考,考博士,硕士研究生考试,TOEFL,GRE,GMAT,教育,培训,辅导班,托福考 试,雅思考试',
'link': 'http://www.dmozdir.org/SiteInformation/?www.examren.com-----22187-----.shtml',
'title': '考试人论坛'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=226>
{'desc': '南开大学深圳研究院是南开大学在深圳的直属单位,主要开展高级工商管理硕士EMBA,在职金融硕士、高层次培训等办学项目和科技成果转化 。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.nkusz.org.cn-----30875-----.shtml',
'title': '南开大学深圳研究院'}
2020-02-01 21:57:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=242> (referer: None)
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '亿美达湖南怀化美容美发化妆学校的官方网站首页,学校提供美容美发化妆培训,瑜伽培训,美容培训,美发培训,化妆培训,怀化市SYB创业培 训,亿美达湖南怀化美容美发化妆学校是怀化周边地区最大最好的美容美',
'link': 'http://www.dmozdir.org/SiteInformation/?www.hhymd.com-----21874-----.shtml',
'title': '怀化亿美达美容美发学校'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '陕西扶贫技术学院-陕西华山技师学院是经陕西省人民政府批准设立,省重点技工院校,国家项目重点扶持、西北地区首家通过ISO质量管理认 证的单位。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.huashanedu.com-----21519-----.shtml',
'title': '陕西扶贫技术学院-陕西华山技师学院'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '北京化妆学校-M.U.S时尚造型是全国首家全法式教学的化妆培训机构。学校集时尚、影视化妆、整体形象设计为一体,从职业规划的角度出发 ,培养顶尖级化妆造型师。学校特为白领开设一对一彩妆课程......',
'link': 'http://www.dmozdir.org/SiteInformation/?www.musfr.com-----14968-----.shtml',
'title': '北京化妆学校-MUS时尚造型'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '苑昕时尚彩妆培训学校成立于连云港,由沙雪带领北京资深彩妆造型团队共创时尚新坐标。校长沙雪有长达二十余年的美术功底,随后开始专 研彩妆造型专业,2005年进驻北京时尚界,多年成功的彩妆教学经验。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.yxbeauty.com-----39411-----.shtml',
'title': '苑昕彩妆培训学校'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '阳朔英语培训,英语口语培训,英语培训',
'link': 'http://www.dmozdir.org/SiteInformation/?www.mcischool.net-----19196-----.shtml',
'title': '阳朔美城英语培训'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '设在环境优美的成都青羊工业总部基地电子商务大厦力方公司11楼,办公面积1400余平方米,先进教学设备200余件,自有学员宿舍,该网站是力方教育所成立的网站,方便学员更好的了解力方教育',
'link': 'http://www.dmozdir.org/SiteInformation/?www.lf-jy.com-----41026-----.shtml',
'title': '成都力方数字科技有限公司'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '成都驾校一点通,成都学车网,成都驾校考试网上预约报名,专业成都陪练陪驾公司,选择史老师驾考服务中心。口碑教学,绝不坑爹',
'link': 'http://www.dmozdir.org/SiteInformation/?www.028jiakao.com-----43633-----.shtml',
'title': '成都驾校学车'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '郑州大学第一附属中学紧紧依靠位居河南教育龙头的郑州大学,以“团结务实,开拓创新”为校风,以“现代化、高质量、创特色、争一流” 为办学目标,以先进的教育理念,一流的师资.',
'link': 'http://www.dmozdir.org/SiteInformation/?www.iuawgwpfn.com-----43397-----.shtml',
'title': '郑大一附中'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '我校是一所主要从事白领类职业资格认证和多种成人考试培训的专业机构,同时,也是四川省人事厅批准的“四川省专业技术人员继续教育基 地”。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.cdsjjy.com-----13945-----.shtml',
'title': '成都世纪精英培训学校'}
2020-02-01 21:57:54 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=242>
{'desc': '孙进技校是全国连锁技工培训学校,包括8大系20多个专业,实践教学培养技工人才',
'link': 'http://www.dmozdir.org/SiteInformation/?www.sunjinxueyuan.com-----13013-----.shtml',
'title': '孙进技校'}
2020-02-01 21:57:54 [scrapy.core.engine] INFO: Closing spider (finished)
2020-02-01 21:57:54 [scrapy.extensions.feedexport] INFO: Stored json feed (20 items) in: items.json
2020-02-01 21:57:54 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 698,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 15099,
'downloader/response_count': 3,
'downloader/response_status_count/200': 3,
'elapsed_time_seconds': 0.983369,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 2, 1, 13, 57, 54, 432829),
'item_scraped_count': 20,
'log_count/DEBUG': 23,
'log_count/INFO': 11,
'response_received_count': 3,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/200': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2020, 2, 1, 13, 57, 53, 449460)}
2020-02-01 21:57:54 [scrapy.core.engine] INFO: Spider closed (finished)
D:\PythonStudy\tutorial>
※执行完毕后,在 tutorial 根目录 下就会有一个名为 items.json 的文件。
[
{"title": "\u5357\u4eac\u5927\u5b66\u6df1\u5733\u7814\u7a76\u9662", "link": "http://www.dmozdir.org/SiteInformation/?www.njusz.org.cn-----30403-----.shtml", "desc": "\u5357\u4eac\u5927\u5b66\u6df1\u5733\u7814\u7a76\u9662\u662f\u5357\u4eac\u5927\u5b66\u5728\u6df1\u5733\u7684\u529e\u5b66\u7a97\u53e3\uff0c\u4f9d\u6258\u5b66\u6821\u7684\u96c4\u539a\u6559\u5b66\u57f9\u517b\u5b9e\u529b\uff0c\u7814\u7a76\u9662\u73b0\u5df2\u7ecf\u5efa\u7acb\u4e86\u591a\u5c42\u6b21\u7684\u4eba\u624d\u57f9\u8bad\u5e73\u53f0\uff0c\u6210\u4e3a\u6df1\u5733\u5f00\u5c55\u9ad8\u5c42\u6b21\u4eba\u624d\u57f9\u517b\u7684\u9aa8\u5e72\u5355\u4f4d\u3002"},
{"title": "\u56db\u5ddd\u5927\u5b66\u4eba\u624d\u6280\u80fd\u57f9\u8bad\u4e2d\u5fc3", "link": "http://www.dmozdir.org/SiteInformation/?www.scdxcfo.net-----9471-----.shtml", "desc": "\u672c\u4e2d\u5fc3\u957f\u671f\u5f00\u8bbe\u4f1a\u8ba1\u4ece\u4e1a\u8d44\u683c\u8bc1\u3001\u4e2d\u7ea7\u4f1a\u8ba1\u7535\u7b97\u5316\u3001\u4f1a\u8ba1\u5b9e\u8d26\u3001\u4eba\u529b\u8d44\u6e90\u7ba1\u7406\u5e08\u3001\u5fc3\u7406\u54a8\u8be2\u5e08\u3001\u7406\u8d22\u89c4\u5212\u5e08\u3001\u5e02\u573a\u8425\u9500\u7ecf\u7406\u7b49\u7cfb\u5217\u77ed\u671f\u57f9\u8bad\uff0c\u56db\u5ddd\u5927\u5b66\u6821\u5185\u4e0a\u8bfe\uff0c\u5e08\u8d44\u96c4\u539a\uff0c\u662f\u60a8\u57f9\u8bad\u7684\u7406\u60f3\u9009\u62e9\u3002"},
{"title": "\u6c5f\u897f\u62db\u751f\u8003\u8bd5\u7f51", "link": "http://www.dmozdir.org/SiteInformation/?www.jxzsks.com-----9662-----.shtml", "desc": "\u6c5f\u897f\u62db\u751f\u8003\u8bd5\u7f51\u63d0\u4f9b\u62db\u751f\u8003\u8bd5\u8d44\u8baf|\u5404\u7c7b\u8003\u8bd5\u4fe1\u606f\u548c\u5f55\u53d6\u6210\u7ee9\u67e5\u8be2\u670d\u52a1\u3002\u7acb\u8db3\u6c5f\u897f\u7701\uff0c\u8f90\u5c04\u5168\u56fd\uff0c\u63d0\u4f9b\u6c5f\u897f\u7701\u9ad8\u8003\u3001\u4e2d\u8003\u3001\u81ea\u8003\u3001\u8003\u7814\u3001\u6210\u8003\u3001\u516c\u52a1\u5458\u8003\u8bd5\u3001\u4e8b\u4e1a\u5355\u4f4d\u62db\u8058\u8003\u8bd5\u3001\u5404\u7c7b\u793e\u4f1a\u8003\u8bd5\u4fe1\u606f\u67e5\u8be2\u7684\u9996\u9009\u7f51\u7ad9\u3002"},
{"title": "\u897f\u5b89.NET\u57f9\u8bad", "link": "http://www.dmozdir.org/SiteInformation/?www.xapeixun.cn-----13207-----.shtml", "desc": "\u897f\u5b89.NET\u6280\u672f\u5b9e\u8bad\u4e2d\u5fc3\u662f\u7531\u591a\u540dIT\u7cbe\u82f1\u7b56\u5212\u6210\u7acb\u7684\u9ad8\u79d1\u6280\u4f01\u4e1a\uff0c\u79c9\u627f\u4e13\u4e1a\u3001\u521b\u65b0\u7684\u7406\u5ff5\uff0c\u79ef\u6781\u5f00\u62d3\uff0c\u4e0e\u65f6\u4ff1\u8fdb\uff0c\u79ef\u6781\u6295\u8eab\u4e8e\u8f6f\u4ef6\u5f00\u53d1\u3001\u7f51\u7ad9\u7b56\u5212\u3001\u8bbe\u8ba1\u3001\u5236\u4f5c\u3001\u7535\u5b50\u5546\u52a1\u548c\u4f01\u4e1a\u4fe1\u606f\u5316\u5efa\u8bbe\u7b49\u884c\u4e1a\u3002"},
{"title": "\u5317\u4eac\u4e2d\u6e05\u7814\u4fe1\u606f\u6280\u672f\u7814\u7a76\u9662\u5e7f\u5dde\u5206\u9662", "link": "http://www.dmozdir.org/SiteInformation/?www.gd-sinotsing.org-----20495-----.shtml", "desc": "\u63d0\u4f9b\u8003\u7814,\u4e13\u5347\u672c,\u81ea\u8003\u5927\u4e13\u7684\u57f9\u8bad\u673a\u6784\u3002\u5317\u4eac\u4e2d\u6e05\u7814\u4fe1\u606f\u6280\u672f\u7814\u7a76\u9662\u4e3b\u8981\u627f\u529e\u4ee5\u6e05\u534e\u957f\u4e09\u89d2\u7814\u7a76\u9662\u3001\u5317\u4eac\u822a\u7a7a\u822a\u5929\u5927\u5b66\u8f6f\u4ef6\u5b66\u9662\u7b49\u673a\u6784\u8054\u5408\u4e3b\u529e\u7684\u6218\u7565\u7ba1\u7406\u4e0e\u4ea7\u4e1a\u4fe1\u606f\u5316\u9ad8\u7ba1\u73ed\uff0c\u6218\u7565\u8d22\u52a1\u4e0e\u91d1..."},
{"title": "\u5c71\u4e1c\u4e13\u5347\u672c\u8003\u8bd5\u7f51", "link": "http://www.dmozdir.org/SiteInformation/?www.xinmingedu.com-----28769-----.shtml", "desc": "\u5c71\u4e1c\u4e13\u5347\u672c\uff0c\u65b0\u660e\u533b\u5b66\u4e13\u5347\u672c\uff0c\u5c71\u4e1c\u533b\u5b66\u4e13\u5347\u672c\u57f9\u8bad\u4e13\u4e1a\u54c1\u724c\uff0c\u53d1\u5e03\u5c71\u4e1c\u4e13\u5347\u672c\u8003\u8bd5\u79d1\u76ee\u3001\u5c71\u4e1c\u4e13\u5347\u672c\u5b66\u6821\u3001\u5c71\u4e1c\u4e13\u5347\u672c\u62a5\u540d\u65f6\u95f4\u3001\u5c71\u4e1c\u4e13\u5347\u672c\u8003\u8bd5\u65f6\u95f4\u30012013\u5c71\u4e1c\u4e13\u5347\u672c\u3001\u5c71\u4e1c\u4e13\u5347\u672c\u653f\u7b56\u4fe1\u606f\u3002"},
{"title": "\u8f6f\u8003\u7f51-\u8f6f\u8003\u4fe1\u606f\u7f51-\u6700\u4e13\u4e1a\u7684\u8f6f\u8003\u7f51\u7ad9", "link": "http://www.dmozdir.org/SiteInformation/?www.51softexam.com-----14225-----.shtml", "desc": "\u8f6f\u8003\uff0c\u8f6f\u8003\u7f51\uff0c\u8f6f\u8003\u4fe1\u606f\u7f51\uff0c\u5168\u56fd\u8f6f\u8003\uff0c\u8f6f\u8003\u7f51\u7edc\u5de5\u7a0b\u5e08\uff0c\u8f6f\u8003\u8f6f\u4ef6\u8bbe\u8ba1\u5e08\uff0c\u8f6f\u8003\u7f51\u7edc\u7ba1\u7406\u5458\uff0c\u8f6f\u8003\u4fe1\u606f\u7cfb\u7edf\u76d1\u7406\u5e08\uff0c\u8f6f\u8003\u7a0b\u5e8f\u5458\uff0c\u8f6f\u8003\u7cfb\u7edf\u5206\u6790\u5e08\uff0c\u8f6f\u8003\u7f51\u7edc\u89c4\u5212\u5e08\uff0c\u8f6f\u8003\u7535\u5b50\u5546\u52a1\u8bbe\u8ba1\u5e08\uff0c\u8f6f\u8003\u4fe1\u606f\u5904\u7406\u6280\u672f\u5458"},
{"title": "\u5929\u6d25\u5927\u5b66EMBA\u6df1\u5733\u6559\u80b2\u4e2d\u5fc3", "link": "http://www.dmozdir.org/SiteInformation/?www.emba-tjusz.com-----30404-----.shtml", "desc": "\u5929\u6d25\u5927\u5b66\u4e8e2010\u5e74\u8d77\u5728\u6df1\u5733\u5f00\u529eEMBA\u6559\u5b66\u9879\u76ee\u3002\u6df1\u5733\u4f5c\u4e3a\u4e2d\u56fd\u7ecf\u6d4e\u7279\u533a\uff0c\u5df2\u7ecf\u5efa\u8bbe\u6210\u4e3a\u4e2d\u56fd\u9ad8\u65b0\u6280\u672f\u4ea7\u4e1a\u57fa\u5730\u548c\u533a\u57df\u6027\u91d1\u878d\u4e2d\u5fc3\u3001\u4fe1\u606f\u4e2d\u5fc3\u3001\u5546\u8d38\u4e2d\u5fc3\u3001\u8fd0\u8f93\u4e2d\u5fc3\uff0c\u73b0\u4ee3\u5316\u7684\u56fd\u9645\u6027\u57ce\u5e02\u3002"},
{"title": "\u8003\u8bd5\u4eba\u8bba\u575b", "link": "http://www.dmozdir.org/SiteInformation/?www.examren.com-----22187-----.shtml", "desc": "\u5347\u5b66\u8003\u8bd5,\u51fa\u56fd\u8003\u8bd5,\u82f1\u8bed\u8003\u8bd5,\u7b49\u7ea7\u8003\u8bd5,\u8d44\u683c\u8003\u8bd5,\u8003\u7814,\u9ad8\u8003,\u6210\u4eba\u9ad8\u8003,\u8003\u535a\u58eb,\u7855\u58eb\u7814\u7a76\u751f\u8003\u8bd5,TOEFL,GRE,GMAT,\u6559\u80b2,\u57f9\u8bad,\u8f85\u5bfc\u73ed,\u6258\u798f\u8003\u8bd5,\u96c5\u601d\u8003\u8bd5"},
{"title": "\u5357\u5f00\u5927\u5b66\u6df1\u5733\u7814\u7a76\u9662", "link": "http://www.dmozdir.org/SiteInformation/?www.nkusz.org.cn-----30875-----.shtml", "desc": "\u5357\u5f00\u5927\u5b66\u6df1\u5733\u7814\u7a76\u9662\u662f\u5357\u5f00\u5927\u5b66\u5728\u6df1\u5733\u7684\u76f4\u5c5e\u5355\u4f4d\uff0c\u4e3b\u8981\u5f00\u5c55\u9ad8\u7ea7\u5de5\u5546\u7ba1\u7406\u7855\u58ebEMBA\uff0c\u5728\u804c\u91d1\u878d\u7855\u58eb\u3001\u9ad8\u5c42\u6b21\u57f9\u8bad\u7b49\u529e\u5b66\u9879\u76ee\u548c\u79d1\u6280\u6210\u679c\u8f6c\u5316\u3002"},
{"title": "\u6000\u5316\u4ebf\u7f8e\u8fbe\u7f8e\u5bb9\u7f8e\u53d1\u5b66\u6821", "link": "http://www.dmozdir.org/SiteInformation/?www.hhymd.com-----21874-----.shtml", "desc": "\u4ebf\u7f8e\u8fbe\u6e56\u5357\u6000\u5316\u7f8e\u5bb9\u7f8e\u53d1\u5316\u5986\u5b66\u6821\u7684\u5b98\u65b9\u7f51\u7ad9\u9996\u9875\uff0c\u5b66\u6821\u63d0\u4f9b\u7f8e\u5bb9\u7f8e\u53d1\u5316\u5986\u57f9\u8bad\uff0c\u745c\u4f3d\u57f9\u8bad\uff0c\u7f8e\u5bb9\u57f9\u8bad,\u7f8e\u53d1\u57f9\u8bad,\u5316\u5986\u57f9\u8bad,\u6000\u5316\u5e02SYB\u521b\u4e1a\u57f9\u8bad\uff0c\u4ebf\u7f8e\u8fbe\u6e56\u5357\u6000\u5316\u7f8e\u5bb9\u7f8e\u53d1\u5316\u5986\u5b66\u6821\u662f\u6000\u5316\u5468\u8fb9\u5730\u533a\u6700\u5927\u6700\u597d\u7684\u7f8e\u5bb9\u7f8e"},
{"title": "\u9655\u897f\u6276\u8d2b\u6280\u672f\u5b66\u9662-\u9655\u897f\u534e\u5c71\u6280\u5e08\u5b66\u9662", "link": "http://www.dmozdir.org/SiteInformation/?www.huashanedu.com-----21519-----.shtml", "desc": "\u9655\u897f\u6276\u8d2b\u6280\u672f\u5b66\u9662-\u9655\u897f\u534e\u5c71\u6280\u5e08\u5b66\u9662\u662f\u7ecf\u9655\u897f\u7701\u4eba\u6c11\u653f\u5e9c\u6279\u51c6\u8bbe\u7acb\uff0c\u7701\u91cd\u70b9\u6280\u5de5\u9662\u6821\uff0c\u56fd\u5bb6\u9879\u76ee\u91cd\u70b9\u6276\u6301\u3001\u897f\u5317\u5730\u533a\u9996\u5bb6\u901a\u8fc7ISO\u8d28\u91cf\u7ba1\u7406\u8ba4\u8bc1\u7684\u5355\u4f4d\u3002"},
{"title": "\u5317\u4eac\u5316\u5986\u5b66\u6821-MUS\u65f6\u5c1a\u9020\u578b", "link": "http://www.dmozdir.org/SiteInformation/?www.musfr.com-----14968-----.shtml", "desc": "\u5317\u4eac\u5316\u5986\u5b66\u6821-M.U.S\u65f6\u5c1a\u9020\u578b\u662f\u5168\u56fd\u9996\u5bb6\u5168\u6cd5\u5f0f\u6559\u5b66\u7684\u5316\u5986\u57f9\u8bad\u673a\u6784\u3002\u5b66\u6821\u96c6\u65f6\u5c1a\u3001\u5f71\u89c6\u5316\u5986\u3001\u6574\u4f53\u5f62\u8c61\u8bbe\u8ba1\u4e3a\u4e00\u4f53\uff0c\u4ece\u804c\u4e1a\u89c4\u5212\u7684\u89d2\u5ea6\u51fa\u53d1\uff0c\u57f9\u517b\u9876\u5c16\u7ea7\u5316\u5986\u9020\u578b\u5e08\u3002\u5b66\u6821\u7279\u4e3a\u767d\u9886\u5f00\u8bbe\u4e00\u5bf9\u4e00\u5f69\u5986\u8bfe\u7a0b......"},
{"title": "\u82d1\u6615\u5f69\u5986\u57f9\u8bad\u5b66\u6821", "link": "http://www.dmozdir.org/SiteInformation/?www.yxbeauty.com-----39411-----.shtml", "desc": "\u82d1\u6615\u65f6\u5c1a\u5f69\u5986\u57f9\u8bad\u5b66\u6821\u6210\u7acb\u4e8e\u8fde\u4e91\u6e2f\uff0c\u7531\u6c99\u96ea\u5e26\u9886\u5317\u4eac\u8d44\u6df1\u5f69\u5986\u9020\u578b\u56e2\u961f\u5171\u521b\u65f6\u5c1a\u65b0\u5750\u6807\u3002\u6821\u957f\u6c99\u96ea\u6709\u957f\u8fbe\u4e8c\u5341\u4f59\u5e74\u7684\u7f8e\u672f\u529f\u5e95\uff0c\u968f\u540e\u5f00\u59cb\u4e13\u7814\u5f69\u5986\u9020\u578b\u4e13\u4e1a\uff0c2005\u5e74\u8fdb\u9a7b\u5317\u4eac\u65f6\u5c1a\u754c\uff0c\u591a\u5e74\u6210\u529f\u7684\u5f69\u5986\u6559\u5b66\u7ecf\u9a8c\u3002"},
{"title": "\u9633\u6714\u7f8e\u57ce\u82f1\u8bed\u57f9\u8bad", "link": "http://www.dmozdir.org/SiteInformation/?www.mcischool.net-----19196-----.shtml", "desc": "\u9633\u6714\u82f1\u8bed\u57f9\u8bad\uff0c\u82f1\u8bed\u53e3\u8bed\u57f9\u8bad\uff0c\u82f1\u8bed\u57f9\u8bad"},
{"title": "\u6210\u90fd\u529b\u65b9\u6570\u5b57\u79d1\u6280\u6709\u9650\u516c\u53f8", "link": "http://www.dmozdir.org/SiteInformation/?www.lf-jy.com-----41026-----.shtml", "desc": "\u8bbe\u5728\u73af\u5883\u4f18\u7f8e\u7684\u6210\u90fd\u9752\u7f8a\u5de5\u4e1a\u603b\u90e8\u57fa\u5730\u7535\u5b50\u5546\u52a1\u5927\u53a6\u529b\u65b9\u516c\u53f811\u697c\uff0c\u529e\u516c\u9762\u79ef1400\u4f59\u5e73\u65b9\u7c73\uff0c\u5148\u8fdb\u6559\u5b66\u8bbe\u5907200\u4f59\u4ef6\uff0c\u81ea\u6709\u5b66\u5458\u5bbf\u820d\uff0c\u8be5\u7f51\u7ad9\u662f\u529b\u65b9\u6559\u80b2\u6240\u6210\u7acb\u7684\u7f51\u7ad9\uff0c\u65b9\u4fbf\u5b66\u5458\u66f4\u597d\u7684\u4e86\u89e3\u529b\u65b9\u6559\u80b2"},
{"title": "\u6210\u90fd\u9a7e\u6821\u5b66\u8f66", "link": "http://www.dmozdir.org/SiteInformation/?www.028jiakao.com-----43633-----.shtml", "desc": "\u6210\u90fd\u9a7e\u6821\u4e00\u70b9\u901a,\u6210\u90fd\u5b66\u8f66\u7f51,\u6210\u90fd\u9a7e\u6821\u8003\u8bd5\u7f51\u4e0a\u9884\u7ea6\u62a5\u540d,\u4e13\u4e1a\u6210\u90fd\u966a\u7ec3\u966a\u9a7e\u516c\u53f8,\u9009\u62e9\u53f2\u8001\u5e08\u9a7e\u8003\u670d\u52a1\u4e2d\u5fc3\u3002\u53e3\u7891\u6559\u5b66\uff0c\u7edd\u4e0d\u5751\u7239"},
{"title": "\u90d1\u5927\u4e00\u9644\u4e2d", "link": "http://www.dmozdir.org/SiteInformation/?www.iuawgwpfn.com-----43397-----.shtml", "desc": "\u90d1\u5dde\u5927\u5b66\u7b2c\u4e00\u9644\u5c5e\u4e2d\u5b66\u7d27\u7d27\u4f9d\u9760\u4f4d\u5c45\u6cb3\u5357\u6559\u80b2\u9f99\u5934\u7684\u90d1\u5dde\u5927\u5b66\uff0c\u4ee5\u201c\u56e2\u7ed3\u52a1\u5b9e\uff0c\u5f00\u62d3\u521b\u65b0\u201d\u4e3a\u6821\u98ce\uff0c\u4ee5\u201c\u73b0\u4ee3\u5316\u3001\u9ad8\u8d28\u91cf\u3001\u521b\u7279\u8272\u3001\u4e89\u4e00\u6d41\u201d\u4e3a\u529e\u5b66\u76ee\u6807\uff0c\u4ee5\u5148\u8fdb\u7684\u6559\u80b2\u7406\u5ff5\uff0c\u4e00\u6d41\u7684\u5e08\u8d44."},
{"title": "\u6210\u90fd\u4e16\u7eaa\u7cbe\u82f1\u57f9\u8bad\u5b66\u6821", "link": "http://www.dmozdir.org/SiteInformation/?www.cdsjjy.com-----13945-----.shtml", "desc": "\u6211\u6821\u662f\u4e00\u6240\u4e3b\u8981\u4ece\u4e8b\u767d\u9886\u7c7b\u804c\u4e1a\u8d44\u683c\u8ba4\u8bc1\u548c\u591a\u79cd\u6210\u4eba\u8003\u8bd5\u57f9\u8bad\u7684\u4e13\u4e1a\u673a\u6784\uff0c\u540c\u65f6\uff0c\u4e5f\u662f\u56db\u5ddd\u7701\u4eba\u4e8b\u5385\u6279\u51c6\u7684\u201c\u56db\u5ddd\u7701\u4e13\u4e1a\u6280\u672f\u4eba\u5458\u7ee7\u7eed\u6559\u80b2\u57fa\u5730\u201d\u3002"},
{"title": "\u5b59\u8fdb\u6280\u6821", "link": "http://www.dmozdir.org/SiteInformation/?www.sunjinxueyuan.com-----13013-----.shtml", "desc": "\u5b59\u8fdb\u6280\u6821\u662f\u5168\u56fd\u8fde\u9501\u6280\u5de5\u57f9\u8bad\u5b66\u6821\uff0c\u5305\u62ec8\u5927\u7cfb20\u591a\u4e2a\u4e13\u4e1a\uff0c\u5b9e\u8df5\u6559\u5b66\u57f9\u517b\u6280\u5de5\u4eba\u624d"}
]
※但是都是二进制编码的形式。
