Abstract:
问题:SRCNN不够快,不能实际应用。
办法:提出一种沙漏型(hourglass-shape)的卷积神经网络。
1.网络最后一层去卷积层(deconvolution layer),不用插值不用预处理直接从原来低分辨率图像上进行映射
2.其次,我们通过在映射之前缩小输入要素的尺寸并在之后再扩展,来重新构造映射层。(映射层是干嘛的,现变小后变大吗?)
3.第三,我们采用较小的过滤器尺寸,但采用更多的映射层。
Introduction:
SRCNN太慢啦,发现了两个固有的局限性限制速度。
第一,预处理的时候,低分辨率图像要进行上采样。由低分辨率图像到插值图像。
解决方法:we need直接从低分辨率开始,采用去卷积层代替双线性插值(去卷积层的操作在哪?在最后一层),这样计算复杂度只和低分辨大小有关啦
详细说说去卷积:他不是一种传统插值内核,而是由多种自动学习上采样内核组成的,如果换成一种统一的插值内核,那么psrn会大大减少
第二,非线性映射阶段,在SRCNN中,输入图像块映射到高维LR特征空间上,然后映射到另一个高维HR特征空间。采用更宽的映射层。更大的映射层(a wider mapping layer)可以花费更多的时间但是更精确。
?如何压缩网络规模并能保持当前的精度呢?
解决办法:
1.为了限制在低维空间里面,在映射层最开始和结束的地方,增加了压缩和扩张层。
映射层有毛病
2.把单个宽的映射层进入多个固定大小的层。整个形状就像漏斗。两端薄中间厚。
结果:速度显著提升了,可以适应很多倍的放大效果,我们只需要调整去卷积层。可以促进不同类别的快速培训和测试在FSRCNN中,所有卷积层(
反卷积层)可以由不同放大因子的网络共享。
在训练中,通过训练有素的网络,我们只需要微调去卷积层。
在测试中,我们只需要进行一次卷积运算,相应的反卷积将图像放大不同倍数。
(为啥只需要一次呢,反卷积网络怎么进行调整呢)
2 Related Work
别人是模仿已经有的,我们不是。后面随随便便讲了一些。
3 Fast Super-Resolution by CNN
SRCNN:LR的双线性插值 HR
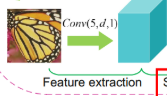
特征提取和表示是第一层,图像块表示成高维的特征向量。(patches of the input 是啥意思)
SRCNN和FSRCNN有三点不同
- 输入不同一个是低分辨率原图一个是bicubic之后的
- 非线性映射变成了三步压缩重建和扩张
- FSRCNN滤波大小变少,网络结构更深了,但是运算更简单。(Filter的解释不够明白:filter是卷积核。filter的最大的特点是其深度与输入层的深度是一致的。输入层是单通道,filter也是单通道。 输入层是三通道,filter也是三通道)

FSRCNN
1.特征提取:从LR中提取Ys,映射到高维特征向量。
FSRCNN55和SRCNN99。5*5patch,patch是啥呢?filter每次只查看图像的一个块,这一个小块就称为 patch,然后过滤器移动到图像的另一个patch,以此类推。当将CNN过滤器应用到图像时,它会一次查看一个 patch 。patch 就是内核 kernel 的输入。这时内核的大小便是 patch 的大小。d是一个敏感变量。
fi, ni, ci分别是滤波器大小。滤波器数目。滤波器通道数。1和图像本身的通道数一致。
输出的是通道d
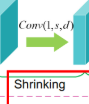
2.压缩:SRCNN中第一步特征提取第二步就是映射了。FSRCNN中为了减小计算量就是压缩。原来第一层输出是d,用一下卷积,s个滤波器,使输出变成s维的。s远小于d,s是一个敏感变量。
输出的是s通道数
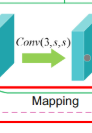
3.非线性映射:非常重要,fnc的选取
输出的是s通道
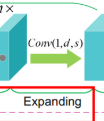
4.扩张:
把图像映射到高维HR图像
输出的是d通道
5.去卷积
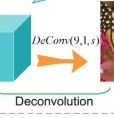
Conv(5, d, 1) − P ReLU − Conv(1, s, d) − P ReLU − m ×Conv(3, s, s)−P ReLU−Conv(1, d, s)−P ReLU−DeConv(9, 1, d).
训练样本。为了准备训练数据,我们首先以所需的比例因子n对原始训练图像进行降采样以形成LR图像。然后我们将LR训练图像裁剪为一组步长为k的fsub×fsub像素子图像。(为什么要剪裁)相应的HR子图像(大小为(nfsub)2)也是从真正的图像中裁剪出来。这些LR / HR子图像对是初级训练数据。对于填充问题,我们凭经验发现填充输入或输出映射对最终效果影响不大。因此我们采用零填充所有层均取决于过滤器的尺寸。这样,无需更改不同网络设计的子映像大小。影响子的另一个问题
图像大小是反卷积层。当我们使用Caffe训练模型时包[27],其反卷积滤波器将生成大小为(nfsub-n + 1)2,而不是(nfsub)2。因此,我们还在HR上裁剪了(n − 1)个像素边界子图像。最后,对于×2,×3和×4,我们设置LR / HR子图像的大小
分别为102 / 192、72 / 192和62/212。
(这个地方好麻烦需要的时候再去看)
学习率卷积层非卷积10^ -3、10^-4
fps是咋求出来的
