根据师兄的建议看了DenseNet论文。
还有其他人的一些笔记https://blog.csdn.net/malele4th/article/details/79429028
https://blog.csdn.net/u014380165/article/details/75142664
DenseNet仍然是针对出现的新问题:输入或者梯度信息穿过多层网络后,会在到达网络的结尾(对于梯度是开头)消失。面对此问题,作者认为,之前的ResNet,Highway Networks,Stochastic depth,FractalNets等等虽然在网络拓扑和训练过程中有所差异,但他们都创建了从浅层到深层的short paths。
基于这种理念,作者提出DenseNet,即直接连接所有层。为了保留前馈的本质(这里不太明白),每一层从之前的层获得输入,并将自己的特征图传向后面的层。关键的一点是,与ResNet相比,DenseNet没有在特征传向一层之前通过求和的方式组合,相反,我们通过连接的方式组合。示意图如下:
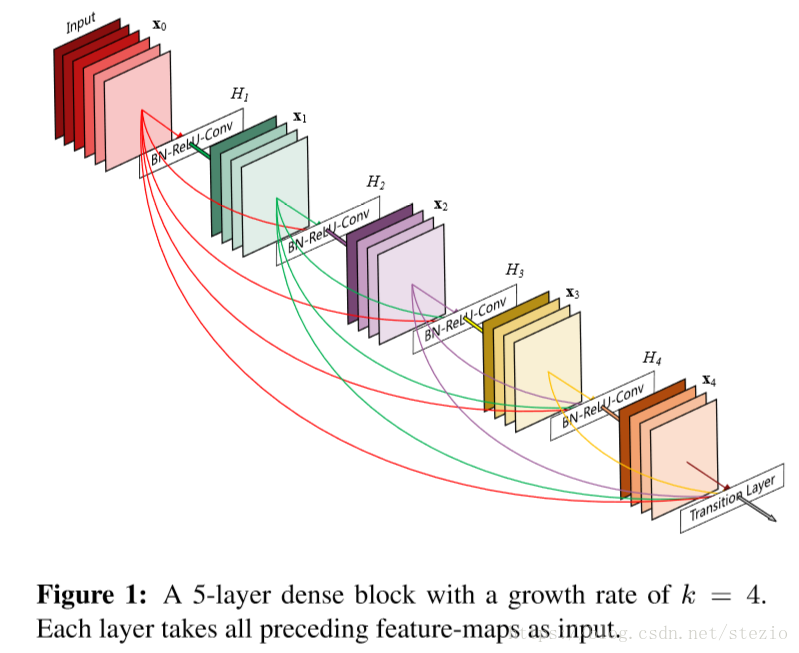
因为其稠密连接的特性,称为DenseNet。
DenseNet相较于传统神经网络有更少的参数,因为没有必要重新学习多余的特征图。DenseNet明确区分了加入网络中的信息和保存的信息。DenseNet很窄(比如每层12个filter),之将一小部分特征图加入到整个网络的“共同知识”中(作为保存的信息?),不改变其他的特征图,然后由最终分类器根据网络中的特征图做出决定。
DenseNet每一层对原始输入信号和损失函数中的梯度有直接访问权,从而获得一种隐含的深层监督,有助于训练更深层网络。作者还发现了DenseNet有正则化的效果,在更小的训练集上减小过拟合。
作者分析了其他研究者之前的相关工作,提到了“cascade structure”,“bypassing path”,“increase the network width”等方法,但作者并没有从极度深层或宽的网络下手,而通过“特征重用”开发出了“网络的潜力”,产出了“利于训练且具有高参数利用率”的浓缩模型。作者认为,连接不同层学习的特征图以增加后续层输入的变化并提升效率,是DenseNet和ResNet主要的不同之处。而相较于Inception networks,DenseNet更简单有效。
DenseNet中,第L层网络将接受所有前置网络的特征图作为输入,如下:
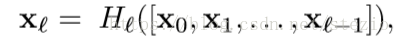
定义()由连续的3个连贯操作组成:batch nomalization,ReLU,和3*3的conv。后来为了减少参数,在3*3卷积层前加了1*1的bottleneck。
对于上式可能出现的特征图大小不一致的情况,卷积神经网络的重要部分之一就是改变特征图大小的下采样层。为了促进这种下采样,将结构分成danse块,中间加上包含batch nomalization,1*1卷积层和2*2池化层的transition layer(这里看的不太懂不知道为什么这种方法可以促进下采样,关于下采样的解释转载自https://blog.csdn.net/stf1065716904/article/details/78450997),在transition layer中设置简洁因子,使得该层输出
个特征图,当
时,称模型为DenseNet-BC,实验中设置
:

对于函数()设有k个特征图作为输出,那么第l层有
输入的特征图(
是输入层的
)。作者认为DenseNet和其他网络的重要不同在于DenseNet可以有“很窄”的层(比如k=12).k被定义为网络的growth rate。实验证明一个较小的k表现出色,对此解释是同一个block中每一层都能访问到前置层,作为网络的“network knowledge”,可以将特征图看作网络的“全局状态”,每一层在这个状态中加上k个特征图,因而称为增长率。
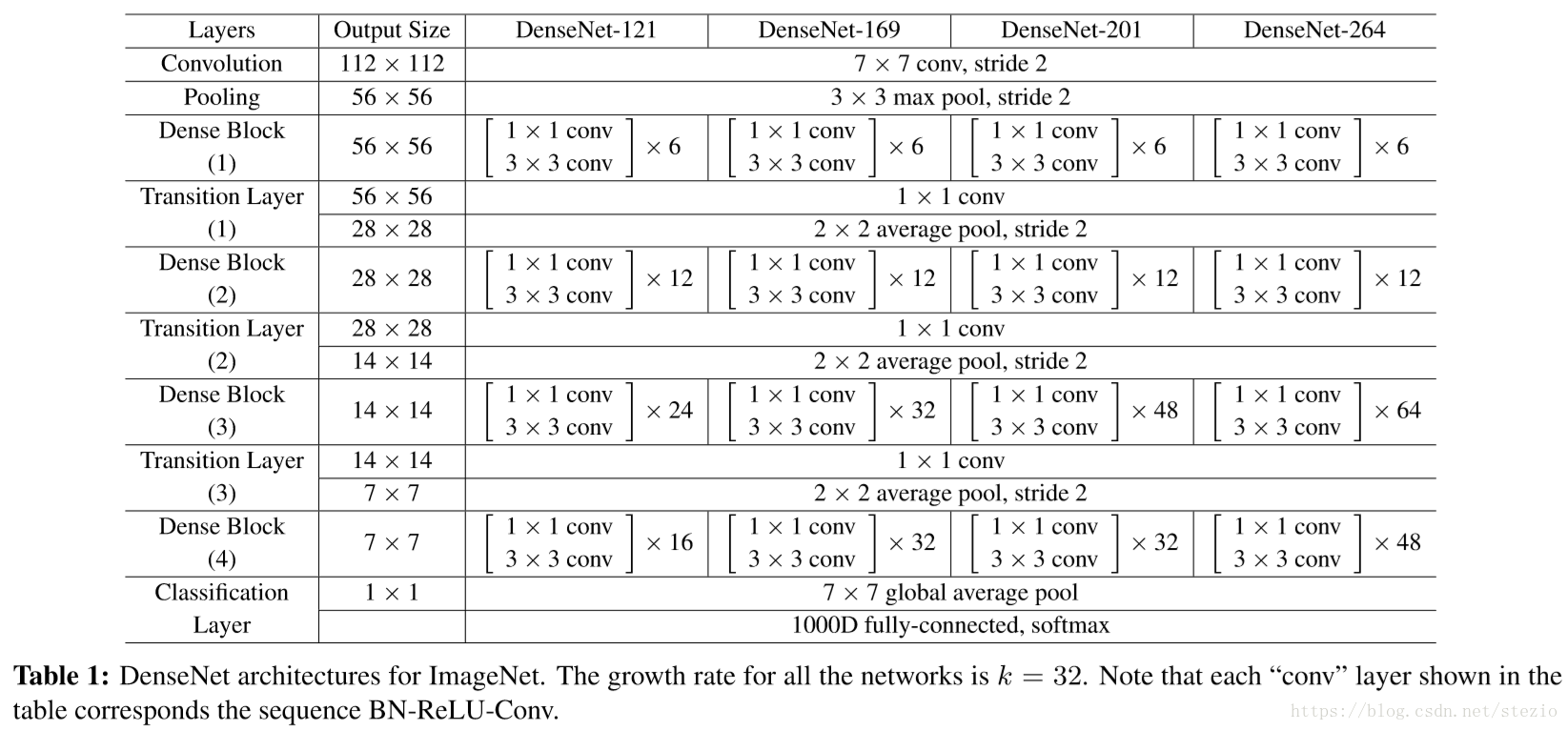
作者这里将DenseNet与传统神经网络作了比较。作者认为,传统神经网络可以被看作是带有状态的算法,层层传递。而DenseNet的“全局状态”可以在网络内部每一处直接访问,而且不需要层层复制。(这里需要借助代码理解,先记下)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
补全:找到了DenseNet的代码之后,发现在每一个由batch nomalization,ReLu,和卷积层组成的conv layer之后,用concat操作将输出与输入连结作为下一层的新输入:
def add_layer(name, l):
shape = l.get_shape().as_list()
in_channel = shape[3]
with tf.variable_scope(name) as scope:
c = BatchNorm('bn1', l)
c = tf.nn.relu(c)
c = conv('conv1', c, self.growthRate, 1)
l = tf.concat([c, l], 3)
return l这就是实现了所谓的“全局状态”。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
关于训练和实验结果这里就暂时略过。
作者认为表面上DenseNet和ResNet很像,DenseNet在输入时用连接取代求和,然而这导致两种网络结构的不同表现。
DenseNet任何一层学习的特征图能够被所有后面的层访问,这鼓励了网络中的特征重用。DenseNet与参数利用率较高的ResNet对比图如下:

对于DenseNet提升的准确率给出的解释是,独立的层通过short connection从损失函数中获得额外的监督,DenseNet展现了一种“深层监督”。这种深层监督的好处在”DSN“( C.-Y.Lee,S.Xie,P.Gallagher,Z.Zhang,andZ.Tu. Deeplysupervised nets. In AISTATS, 2015. 2, 3, 5, 7 )中讲过。DenseNet以一种隐藏的形式完成了一种相似的深层监督:在网络的头部一个单独的分类器通过最多2-3层transition layers对所有层执行监督。因为在所有层中损失函数被共享,损失函数和梯度会没有那么复杂。
在ResNet中的stochastic depth regularization中,层会被随即丢弃,导致周围层直接相连。因为池化层不会被丢弃,网络会和DenseNet有相似之处:在相同的池化层中间任意两层都有连接的概率,作者认为DenseNet对stochastic depth的解释可能会提供一些借鉴。
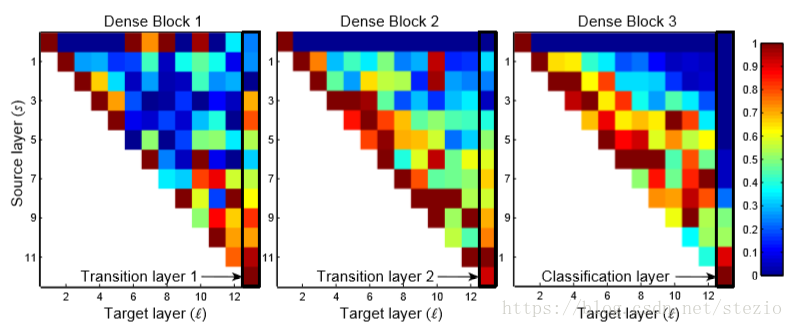

对于特征重用作者给出了几点结论:
所有层在相同block中传输权重,说明浅层提取的特征确实被同一block的深层直接使用。
transition layer在前面的block中对所有层传输权重,表明从最先到最后的层的信息流只经过较少的间接。(这里不太明白)
第二和第三block的层一致地向transition layer指派最小权重(三角第一行全是深蓝色),表明transition layer输出许多冗余特征(平均低权重)。这与DenseNet-BC获得的输出结果被压缩这一结果一致。
尽管最终分类层(最右边)仍对整个block使用权重,似乎对最终特征图有一个集中,表示在网络后层仍有高等级特征产生。