非常深的网络。
受到VGG-net启发,20层,用很高的学习率学习残差,用很高的学习率。
大型图片区域,可以联系附近的图
1 introduce
加速方法:residual-learning and gradient clipping
放大倍数,任意指定(16min)
2 related work
20 weight layers (3 × 3 for each layer). (41 × 41 vs. 13 × 13).
carrying the input to the end layer and reconstructing residuals,共享低频信息
放大倍数变化不需要重新训练模型
输出图片和输入图片一样大
每层用相同的学习率
6 Conclusion
可以用于去噪压缩伪影去除。
47mins
3 proposed method

d层,每层都是64个3364的滤波器。
输入:插值后图像
存在的问题:每次卷积操作后,特征图的大小就会减少。
receptive field:感受野
写作思路:我们的方法别人的方法。
把残差图像预测出来,然后加到原来的图像上面。
我们在卷积之前填充零保持所有要素图的大小(包括输出图片)相同。 事实证明,零填充效果很好。
(啥是零填充啊)
MSE
SRCNN:vanishing、exploding gradients梯度消失梯度爆炸,解决方法残差学习
loss function:1/2||r-f(x)||^2,f(x)不是预测的HR
我们的损失层接受三个输入:残差估计,网络输入(ILR图像)和真实HR图像。 loss计算为重建图像之间的欧几里得距离(网络输入和输出之和)
通过使用基于反向传播的小批量梯度下降来优化回归目标来进行训练。 我们动量参数设置为0.9。 训练通过权重下降进行正则化(L2罚分乘以0.0001)。
SRCNN在收敛之前就停下来了。学习率设置的太小了。
可调式的梯度裁剪,在抑制爆炸梯度的同时提高速度。调整学习率可以加快网络
Gradient clipping:渐变剪裁(36)
随机梯度下降法用于训练。使用裁剪时,梯度会在一定范围内。 通过通常用于训练的随机梯度下降,可以将学习率乘以梯度调整步长。 如果使用高学习率,则有可能将θ调整为较小以避免在高学习率方案中爆炸梯度。
但是,随着学习速率逐渐减小,有效梯度(梯度乘以学习速率)接近于零,并且如果学习速率在几何上降低,则训练可能需要进行指数级的多次迭代才能收敛。
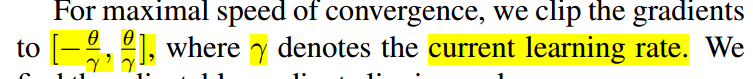
通过这种方法,可以在所有预定义比例因子之间共享参数,我们还训练了一个多尺度模型,几个指定比例的训练数据集被合并为一个大数据集。输入色块大小等于接受区域的大小,并且图像被分成没有重叠的子图像。 微型批处理包含64个子图像,其中不同比例的子图像可以在同一批处理中。
4 understanding properties
对于第一层,感受野的大小为3×3。
对于下一层,感受野的大小会增加
高度和宽度乘以2。 对于深度D网络,
感受野的大小为(2D + 1)×(2D + 1)。 它的大小是
与深度成比例。
现在,我们测试使用比例增强训练的模型是否能够在多个比例因子下执行SR。上面使用的同一网络使用多个比例因子应变= {2,3,4}进行训练。此外,我们尝试
案例应变= {2,3},{2,4},{3,4},以进行更多比较。
5. Experimental Results
We use a network of depth 20. Training uses batches of size 64. Momentum and weight decay parameters are set to 0.9 and 0.0001, respectively.We train all experiments over 80 epochs (9960 iterations
with batch size 64). Learning rate was initially set to 0.1 and
then decreased by a factor of 10 every 20 epochs
阅读论文用时:1.7h
