天池竞赛-津南数字制造算法挑战赛【赛场二】解决方案分享
一、前言
团队名BugFlow,最终排名35/2157
虽然成绩一般,但是作为一支目标检测领域的新手队伍,仅仅有一块1070显卡,从零开始拿到这个排名,也算有一些经验可以拿出来分享,包括一些针对这个比赛我们想出的一些idea,算是抛砖引玉吧,期待能够和排名靠前的大佬多多交流。
二、框架选择
这个比赛实际上就是一个目标检测比赛,初赛要求对图像中的违禁品出现的位置进行检测,复赛在有效检测目标的同时要求输出高质量的实例分割。
对于框架选择,如我们的队名BugFlow一样,由于我们队伍的成员都是以tensorflow作为工具的,我们最初选择的框架是google开源的Tensorflow Object Detection API, 无奈训练效果一直不理想。后面果断切换了FaceBook开源的Detectron, 成绩一下就上升不少,也是体会了一回判教一时爽,一直判教一直爽的感觉。
所以这里不得不说一下,一个好的目标检测框架真的是事半功倍,从我们组的经历来说,Detectron无论从准确性、易用性还是扩展性来说都是一个不错的框架。不知道排名前5的大佬使用的是什么框架,望赐教!很想学习一下~
三、解决方案概述
3.1 模型选择
复赛我们的选择的是 End-to-End Mask R-CNN 作为的baseline, backbone 选择的是 resnet101-FPN
之所以选择FPN结构是因为本竞赛中,待检测违禁品的尺度大小不一,且包含很多小物体,我们认为feature pyramid networks能够更好的解决这个问题。
3.2 数据增强
在我训练分类网络的经验中,在合理的范围内尽可能的进行丰富的数据增强能够大幅提升模型的性能。
显然,这个技能同样能应用于目标检测中,唯一的问题时,在变换图像的同时,需要同时对 bounding box 或 mask 进行相应的变换。当然,这仅仅是一个稍有难度的编程任务,难不倒大家的。
需要注意的是,Detectron自带了水平翻转的数据增强。
我们的数据增强文件实现在/path/to/project/code/second_round_pyfile/data_augmentation_position_bak.py,其中实现了水平、竖直翻转,放大(相当于crop操作),缩小这四个最基本的数据增强方法。
此外,我们还尝试了两种独特的数据增强,一种是类似于随机拼接两种图的增强,一种是随机贴图的增强,效果如下:
随机拼接两种图的效果示例:

随机使用违禁品进行贴图的示例:

遗憾的是,虽然这两种方法表面上极大的丰富了样本集的规模,但并没有取得很好的效果,我们认为这可能和一定程度的破坏了样本原有的数据分布有关。最终我们也没有使用这两种方法。
3.3 使用二分类网络辅助
比赛的过程中,我们发现有两个类型,蓝色小电池和大个的绿色铁壳打火机,特征不太清晰,很容易混淆。
如果单纯使用mask rcnn,模型会变得相对激进,将很多长相相似的物体误判为违禁品,造成成绩很低。
因此,为了权衡这个问题,我们考虑使用一个二分类网络,首先对待检测图片进行判别,若认为包含违禁品,再交给mask rcnn模型进行预测。
有了这个想法之后,我直接使用之前积累的Keras实现的resnet50 demo进行验证。
经过阈值的调试后,二分类能够达到100%召回,98%准确率。这样,大概率不会漏掉含违禁品的图片的情况下,mask rcnn 虚警的概率大大的降低了,成绩也提高了很多。
3.4 预处理
我们还对数据集进行了简单的分析,发现我们的目标场景的图片的像素值普遍偏高,类似下面这样:
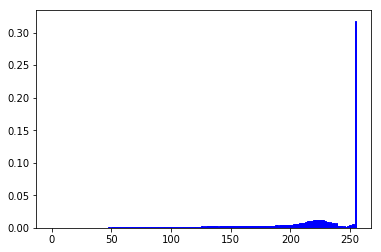
因此我们认为可以对数据进行预处理,大体思路是对像素值进行调整,使其更均匀的分布在0-255的范围内。
为此,我设计了3种不同的预处理方法,其中最简单的一个就是类似下图的一个简单映射:
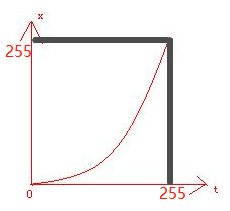
它达到的效果类似下面这样:
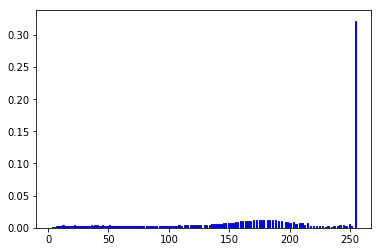
三种预处理的效果示例:
原图:
预处理1:
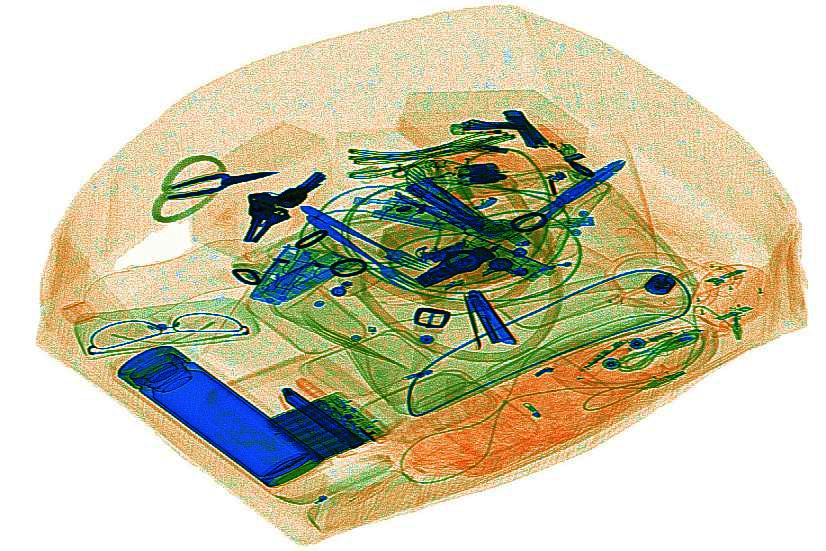
预处理2:
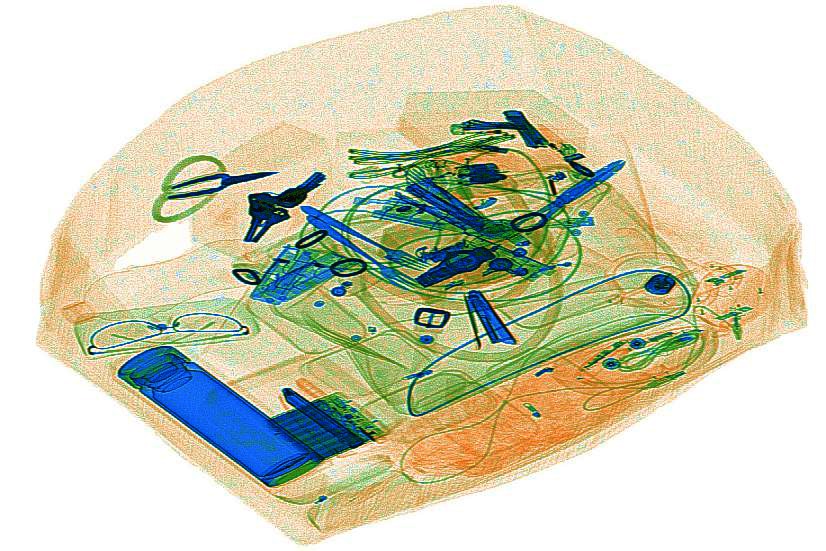
预处理3:

其中,通过不断地尝试和提交测试分数,我们发现预处理1对于二分类的accuracy提升有明显帮助,预处理3对mask rcnn的性能有微弱提升(也可能是随机因素导致,还不敢确定)
至此,我已经将我们认为所有可能值得分享的信息介绍了,还望排名靠前的大佬不吝赐教~~~
对于大多数伙伴,读到这里就可以了~
如果你对我们代码的详细信息甚至复现感兴趣,请继续往下看,我简单的介绍一下。
四、安装
我们代码的运行环境及主要依赖为:
Ubuntu/Centos + CUDA9 + CUDNN7 + NCCL + Anaconda2 + Keras2.2.4 + PyTorch
初赛我们使用的显卡是可怜的NVIDIA GTX1070,复赛有了阿里云代金卷使用的是P100
运行如下命令,自动安装依赖环境及深度学习框架
$ cd /path/to/project/code/install
$ ./install_requirements.sh
详见project/code/README.md,若由于各种没有考虑到的情况安装不能顺利进行,还请大家简单分析安装脚本自行安装环境。
五、复现
初赛时还处于摸索阶段,成绩也只有89名,初赛的复现就不做介绍了。大家有兴趣可以看下初赛提交时我们编写的 ROUND1_README,我们对如何复现我们的结果进行了说明。
复赛阶段的代码位于project/code/second_round_pyfile中,相应的运行脚本位于project/code/second_round_shell中,我们对这些脚本进行了编号,简单的阅读确定参数并依次执行即可~
六、联系方式
参加比赛也是一个交流的过程,本人现在作业帮的反作弊团队担任算法工程师,期待和各位算法从业者进行技术上的交流~
加好友、技术交流、内推请联系我,本人邮箱[email protected]。
此外,我们团队一位靠谱的小伙伴正在打算找博导,希望大家帮忙推荐呀,他的联系方式[email protected]
