
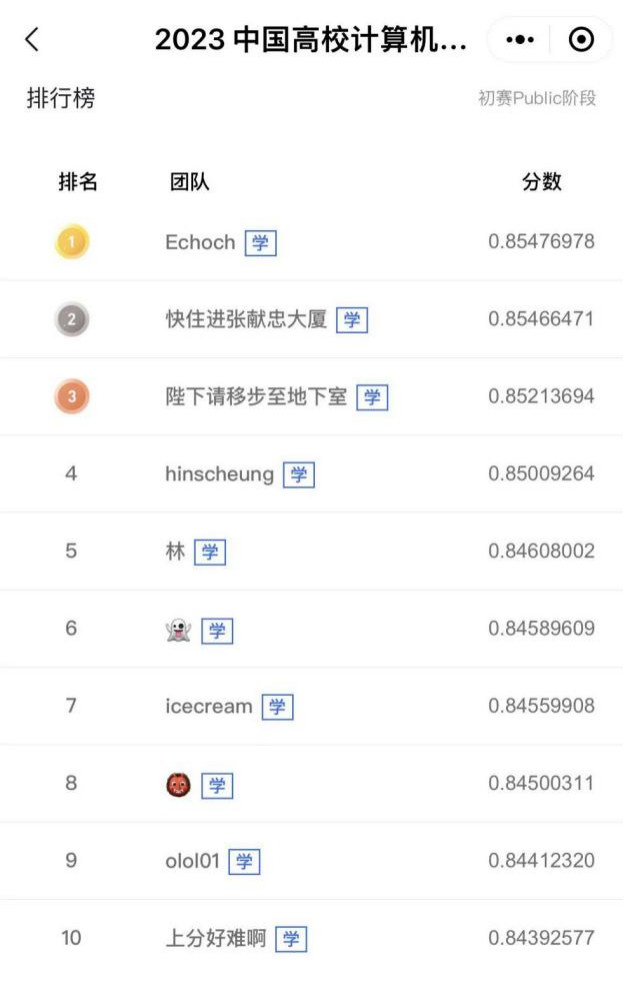
7月10日,中国高校计算机大赛-大数据挑战赛进入到了初赛阶段周周星的奖项评选环节,通过对参赛选手在线提交结果的实时测评(以10日12点的Public榜成绩为准),第二周周周星成绩最优的名单均为在校生队伍(见下图),恭喜获奖的两支学生队伍!
获奖的两支队伍对大赛有哪些实战的经验呢,让我们一起听听他们的分享吧!
01
Echoch 队获奖经验分享
赛题理解
说实话这题感觉还有很多不太理解和困难的地方。但是凭借一些运气拿到了周周星,方案只用了trace和log的特征,metric一点也没用到,我甚至都把有没有metric这个特征去了。下面主要是对log和trace的分析。
Trace
timestamp:对于timestamp.min中小于100和等于1199999的计数
end_time-start_time:进行细化 只对mysql类的样本进行统计

status_code:进行细化 只对网页类的样本进行统计
其他类别特征:count/n_unique
Log
timestamp:上周周星星做diff再分组,我这里用处不大,所以我这里的log,时间戳特征压根没用到
service:统计service的count和n_unique
message:统计长度的均值和方差
可以适当做一些交叉
部分特征工程如下
'''
feats['log_length'] = len(log)
feats['log_service_nunique'] = log['service'].nunique()
feats['message_length_std'] = log['message'].fillna("").map(len).std()
feats['message_length_ptp'] = log['message'].fillna("").map(len).agg('ptp')
feats['log_info_length'] = log['message'].map(lambda x:x.split("INFO")).map(len).agg('ptp')
#developed feature
# text_list = ['异常','错误','error','user','mysql','true','失败']
text_list = ['user','mysql']
for text in text_list:
# feats[f'message_{text}_sum'] = log['message'].str.contains(text, case=False).sum()
feats[f'message_{text}_mean'] = log['message'].str.contains(text, case=False).mean()
feats[f'message_mysql_mean'] = 1 if feats[f'message_mysql_mean'] > 0 else 0
'''
Metric
挖了半天完全没用到,加上去线下就掉分,难点在数据范围广,同一个tags,有很多种范围,不同样本的范围也不一样。
我觉得这部分如果完全挖不出来,就只剩下看大家对A榜过拟合的程度了。
模型选择
1.我使用的xgb,没有9个二分类和OVR,初赛不想对模型调半天就这样,复赛增大数据量再弄吧。
2.我的nn最多只有82,感觉功底不太够 线下也上不去
迭代
找到明显决策边界后,就算线下掉也不用着急,线上会上去的。也可以看
- submit.groupby('source').max()
当No Fault的最大auc提高时 可以试试。
还有就是线下上一两个点时 可以把做的特征按label groupby可视化一下 因为有些训练上分了 但是测试集根本没这个东西。
上82、83需要做加法,上85需要做减法。
02
快住进张献忠大厦获奖经验分享
1. 数据理解
官方提供了3个数据源,metric是监控测量数据,不同service下的测量值可以直接从表中了解到,但是具体的测量内容并未在表中体现;log是系统日志,包含了各种不同系统的运行输出日志,同一个service也包含了不同的系统;trace是追踪数据,内容比较完整,id大部分都是单独出现的。
2. 特征工程
trace数据比较明显的特征是end_time - start_time,这个特征表示一条trace从开始到结束所用的时间,这个时间的长短可以分辨出是否有故障,可以围绕这个特征做一些衍生,比如mean,std,max,min等,也可以考虑把它和其他变量做交叉。status_code也直接表明了是否有故障,也可以考虑用它和其他变量做交叉。
log数据主要就是考虑如何处理message的信息。可以挑选一些关键词如error,warning等做词频统计,一些nlp的技术也可以用上,tfidf、预训练模型gpt2、bert等计算文本表示。
metric数据的特点暂时还没弄明白,没有用上。
3. 模型
做完特征后的数据存在大量缺失值,基于树的模型可以直接处理,xgboost、lightgbm、catboost、随机森林等都是可以选的。不建议对缺失值填补,这可能会导致训练集和测试集的分布产生严重偏移。
如果直接使用原始数据也可以考虑各种可以处理序列的神经网络结构,cnn、lstm、transformer等,效果也是不错的。
4. 尚未解决的问题
metric数据中看起来像是时序数据,但是不同service间好像并不是可比的。进行特征工程的效果看起来并不好,用神经网络也学不到有用的信息,感觉这个数据是放在里面捣乱的。
log中的时间戳顺序和message中的时间并不一致,哪种顺序才是正确的需要解决。
大赛组委会为每周的周周星获奖者提供了精美实用的礼品,包括清华活力校园时尚印花T恤、机械革命 耀·C510三模无线游戏手柄、罗技(Logitech)无线蓝牙超薄静音轻音键盘、罗技(Logitech)无线蓝牙鼠标。别再犹豫啦,快叫上你的小伙伴一起角逐吧!

本周学生队伍发挥出色,在职队伍要加油啦!悄悄告诉你,qq交流群中都在讨论上分策略,遇强则强,快来加入这场高水平的对决吧!参赛选手可以继续从指定网站下载比赛的训练数据和测试数据,并在线提交结果,报名截止至7月24日12:00。

欢迎了解更多(数据派THU菜单栏-大赛入口)
• 大赛官网:http://nercbds.tsinghua.edu.cn/bdc/
• 大赛小程序:可赛
• 大赛邮箱:[email protected]
• 大赛 QQ 群:762146461 / 901317172
往期周周星经验分享回顾:

