简介
我看到了有无数个感知机算法的blog,但是很多都是直接把代码丢上去,即使有讲解也都很浅。于是我挑选了一个我认为最简洁的python代码实现,但是同样博主也没有很深入的讲解。我结合他的代码来深入的介绍一下这个算法,如果您能认真的看完,那么这个算法应该不会有大的问题了。
算法简介
首先我们要知道,感知机算法是神经网络和支持向量机的基础,其中的数学思想更是基础中的基础。他是二分类的线性分类模型,感知机学习最终目的是将样本划分为正负两类分离超平面,算法的总体思想是引入基于误分类的损失函数,利用随机梯度下降的方法来解决求解这个随时函数最优化的问题。
优点就是非常的简单和易于实现。
数学原理
算法的目标是找到一个可以将训练集的正负点完全分开的分离超平面,
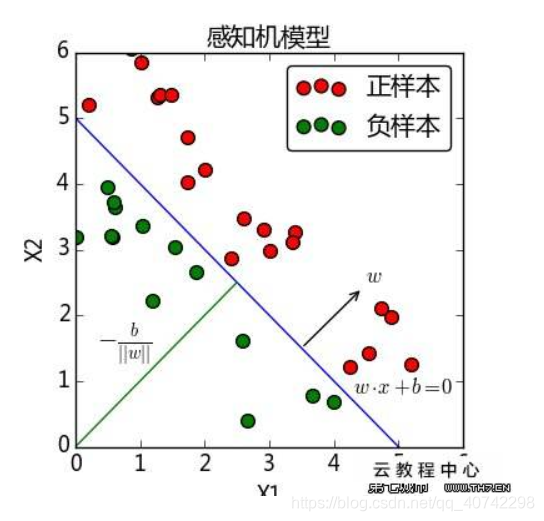
在二维的情况下就是一条直线。那就是需要确定y=wx+b中的w和b。那么我们需要建立一个学习模型:
- 首先
对于每一个正确分类的样本点,满足{wx + b > 0,y = 1}或者{wx + b < 0 ,y = -1},所以对于所有的误分点一定有y(wx+b) <= 0。
- 其次
我们定义损失函数,这个损失函数计算的是每个误分点到目前的y = wx + b这条直线的距离之和。公式表达为:
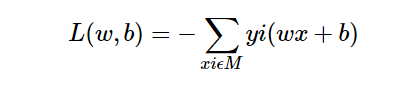
其中M表示的是误分点的集合。
那么这时我们的问题就转化为了minL(w,b)的问题。
- 接下来
为了解决minL(w,b)的问题,使用随机梯度下降的方法,,也就是说极小化的过程并不是对M中的所有点的梯度下降,而是一次随机选取一个误分类点进行梯度下降。
由于在实际的应用中M使固定的,所以随时函数的梯度就是:
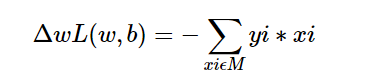
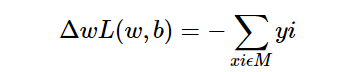
所以我们随机选取一个误分点,然后
w->w+nyixi
b->b+nyi
其中n是步长,那么在下面的代码中我们叫做学习率。通过迭代使得L不断减小。
原始形式
代码分析:
总的来说就是分为4步
- 随机选取w0,b0
- 在数据集中选取数据(xi,yi)
- 判断if y(wx+b) <= 0 then {
w->w+nyixi
b->b+nyi
} - 回到2,当没有误分点时结束。
代码:
def vectorInnerProduct(vector1,vector2): # 实现两个向量的內积
result = 0
length = len(vector1)
for i in range(length):
result += vector1[i] * vector2[i]
return result
def elementAddition(vector1,vector2): # 实现两个向量的对应元素相加
for i in range(len(vector1)):
vector1[i] += vector2[i]
return vector1
def numberMultiply(num,vector): # 实现向量的数乘
tempVector = []
for i in range(len(vector)):
tempVector.append(vector[i] * num)
return tempVector
# 不能直接修改原来的vector,要不然带入到感知机的主函数会一边修改权重和偏置,
# 一边修改原来的数据集
"""
上面三个函数,是为了方便对数据(向量)进行相关的运算,写的辅助函数。很简单
"""
def perceptron(bias,dataSet,learnRate):
# 感知机原始算法,需要输入三个变量,偏置,数据集以及学习率。
weightVector = [0 for i in range(len(dataSet[0][0]))] # 权重向量初始化为0
while True:
# 因为要不断遍历训练集,直到没有误分类点,因此利用一个while循环,和记录误分类点数量的变量errornum
errorNum = 0
for data in dataSet: # 一遍一遍的遍历数据集,进行迭代
if data[1] * (vectorInnerProduct(weightVector,data[0])+bias) <= 0:
errorNum += 1
weightVector = elementAddition(weightVector,numberMultiply(learnRate * data[1],data[0]))
bias += learnRate * data[1]
if errorNum == 0: # 如果没有误分类点,退出循环
break
return weightVector,bias # 返回模型参数
代码来自https://blog.csdn.net/ggdhs/article/details/92803970
对偶形式
基本思想:
和原始形式稍有不同但是原理是一样的,将w和b表示为xi和yi的线性组合形式,然后通过求解其系数来得到w和b。所以w和b我们可以表示为:
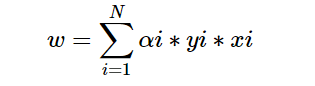
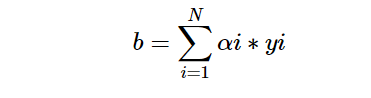
代码
伪代码:
主要有四步
- a = 0 ,b = 0
- 在数据集中选取数据(xi,yi)
- 判断if

then {
ai = ai + n
b = b + nyi
} - 回到2,当没有误分点时结束。
注:在下面的代码实现中为了提高效率,使用了空间换时间的方法,将内积计算并存储起来,也就是gramMatrix函数。
def vectorInnerProduct(vector1,vector2): # 向量內积
result = 0
length = len(vector1)
for i in range(length):
result += vector1[i] * vector2[i]
return result
def gramMatrix(dataSet): # 计算gram矩阵
length = len(dataSet)
gramMatrix = [[0 for i in range(length)] for i in range(length)]
for i in range(length):
for j in range(length):
gramMatrix[i][j] = vectorInnerProduct(dataSet[i][0],dataSet[j][0])
return gramMatrix
def elementAddition(vector1,vector2): # 向量元素相加
for i in range(len(vector1)):
vector1[i] += vector2[i]
return vector1
def numberMultiply(num,vector): # 数乘
tempVector = []
for i in range(len(vector)):
tempVector.append(vector[i] * num)
return tempVector
def perceptron(dataSet,learnRate): # 对偶形式的变量为数据集和学习率,alpha和偏置在函数中设置成了0
n = len(dataSet)
alphaList= [0 for i in range(n)]
bias = 0
gram = gramMatrix(dataSet)
while True: # 具体的思路和原始算法一样,只是一些细节(判定条件和学习表达式)修改了一下
errorNum = 0
for i in range(n):
tempSum = 0
for j in range(n):
tempSum += alphaList[j] * dataSet[j][1] * gram[j][i]
if dataSet[i][1] * (tempSum + bias) <= 0:
errorNum += 1
alphaList[i] += learnRate
bias += learnRate * dataSet[i][1]
if errorNum == 0:
break
# 在学习过程中学习的是alpha,利用学习的alpha计算最终的权值向量
weightVector = numberMultiply(alphaList[0]*dataSet[0][1],dataSet[0][0])
for i in range(1,n):
weightVector = elementAddition(weightVector,numberMultiply(alphaList[i]*dataSet[i][1],dataSet[i][0]))
return weightVector,bias
有不对的请大家指正
共勉~~
保佑武汉
