这篇学习笔记强调几何直觉,同时也注重感知机算法内部的动机。限于篇幅,这里仅仅讨论了感知机的一般情形、损失函数的引入、工作原理。关于感知机的对偶形式和核感知机,会专门写另外一篇文章。关于感知机的实现代码,亦不会在这里出现,会有一篇专门的文章介绍如何编写代码实现感知机,那里会有几个使用感知机做分类的小案例。
感知机算法是经典的神经网络模型,虽然只有一层神经网络,但前向传播的思想已经具备。究其本质,感知机指这样一个映射函数:\(sign(w_ix_i + b)\),将数据带进去计算可以得到输出值,通过比较输出值和数据原本对应的标签值是否正负号相同从而推断出模型训练的结果。
1. 何为感知机?
接上面的叙述,感知机的数学模型为\(sign(w_ix_i + b)\),其中\(w = (w_1,w_2,...,w_n)\)是权重向量,\(x_i = (x_i^{1},x_i^{2},...,x_i^{n})\)是一个样本点,从符号很容易理解,它们都是定义在\(R^n\)空间的(如果难以理解,可以简单的理解为样本点有\(n\)个维度,相应的权重向量也须有\(n\)个维度和它相匹配).
下面是一副经典的感知机模型图:
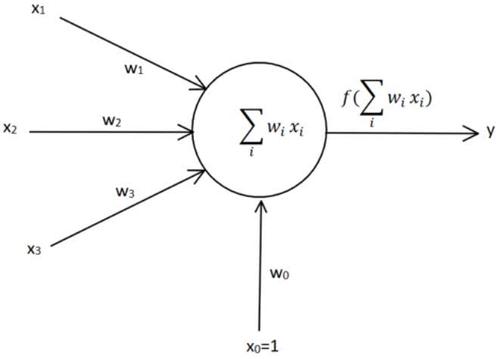
最左边的表示输入一个样本点的特征向量,通过各自的权重前向传播到神经元,在神经元有一个加法器,最后通过一个激活函数来决定是否激活。最下面的\(x_0\)是bias项,一般文献中记为\(b\)。
2. 感知机可以解决什么问题?
这里我们可以看一个经典的例子,利用感知机模型来解决经典的\(OR问题\)。
【例1】设有4个样本点,\((0,0),(0,1),(1,0),(1,1)\),根据\(OR\)的逻辑,必须至少有一个不为\(0\)才能判定为真,翻译成机器学习的表达即标签为\((-1,1,1,1)\),这里负数表示负样本,正数表示正样本。

我们希望的是能找到一条直线(分类器),将正负样本点准确分开。根据\(\S1\)中的叙述,样本点是定义在\(R^2\)空间的,显然权重向量为\(w = (w_1,w_2)\),考虑偏置项\(b\),一般添补一个\(x_i^{0}\)为\(-1\)以便把式子\(\sum\limits_{1}^{n} w_ix_i + b\)直接写成\(\sum\limits_{0}^{n}w_ix_i\)。先给出权重更新公式$ w_{ij} ← w_{ij} − η(y_{j} − t_{j} ) · x_i $, 稍后会给出解释。
设置权重初值为\(w = (0,0)\)。并且约定当且仅当\(sign(x=0)=0\),算作误分类。依次代入样本点:

代入\((0,0)\)点,\(sign(wx + b) = sign(0 * 0 + 0 * 0 + 0*(-1)) = 0\),无法判定是否为负类,错误。
更新权重
\(b = 0 - 1 * (1-0) * (-1)=1\)
\(w_1 = 0 - 1 * (1-0) * 0=0\)
\(w_2 = 0 - 1 * (1-0) * 0=0\)
代入\((0,1)\)点,\(sign(wx + b) = sign(0 * 0 + 0 * 1 +1 *(-1)) = -1\),判定为负类,错误。
更新权重
\(b = 1 - 1 * (1 - (-1)) * (-1) = -1\)
\(w_1 = 0 - 1 * (1 - (-1))*0 = 0\)
\(w_2 = 0 - 1*(1-(-1))*1 = 2\)
代入\((1,0)\)点,\(sign(wx+b)=sign(0 * 1 + 2 * 0 + (-1) * (-1))= 1\),判定为正类,正确。
代入\((1,1)\)点,\(sign(wx + b)=sign(0 * 1 + 2 * 1 + (-1)* -1)=3\),判定为正类,正确。
第二轮遍历,代入\((0,0)\),\(sign(0*0 + 2*0 + (-1)*-1)=1\),无法判定是否为负类,错误。
更新权重
\(b = -1 - 1*(1-(-1))*(-1)=1\)
\(w_1 = 0 - 1*(1-(-1))*0=0\)
\(w_2 = 2 - 1*(1-(-1))*0 = 2\)
代入\((0,1)\),\(sign(0 * 0 + 2 * 1 + 1 * (-1))=1\),判定为正类,正确。
后面的步骤就省略不写了,读者可以自行验算。根据代码计算的结果,如果初始权重设为[0,0,0]这样比较极端的值,学习速率为1时,且按照顺序选择样本点时,需要完整的走完两轮迭代才能得到稳定的权重。最后解得分类函数为: \(sign(2x^{(1)} + 2x^{(2)} - 1)\),读者可以带数据进去验算。
3. 感知机不能解决什么问题?
这里有一段经典的公案,《感知机》是这本书的出现,直接让神经网络这一流派的研究停止了二十年。因为书中在详尽介绍感知机原理的同时,还指出了感知机的致命缺陷:无法解决\(XOR\)问题。
\(XOR\)又称为异或,它的逻辑如下:
| 变量1 | 变量2 | 逻辑运算结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
这是个比较奇怪的逻辑,变量之间当且仅当不相等时为真。
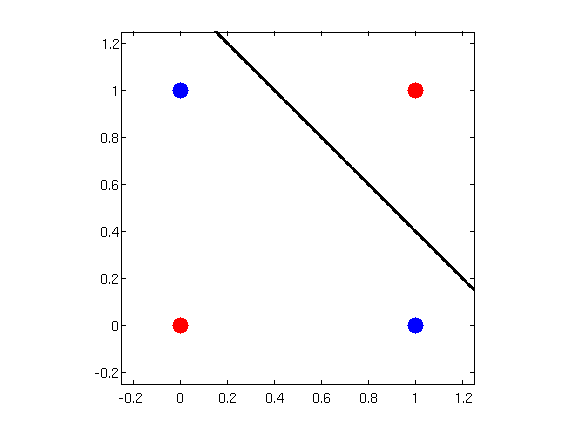
凭着几何直觉,我们很快就能发现,不可能有这样的超平面,能准确的分开红色和蓝色两类样本。
这里小结一下:
感知机可以解决完全线性可分的问题。
这似乎是一句废话,但是感知机背后强大的思想确衍生出了支持向量机这个传统机器学习的巅峰。而对于线性不可分的样本,可以使用多层神经网络(\(Multi \space Layer \space Network\))或者使用核感知机,事实上两层的感知机就可以解决\(XOR\)问题
4. 感知机是如何工作的?
在上面这个略显啰嗦的例子,我们看到了感知机的工作方法。它的算法流程可以概括如下:
- 选取初始值\(w_0, b_0\)
- 在训练集中选取一个数据点\((x_i,y_i)\)
- 检查在这个样本点上,模型是否会错误分类,如果错误分类,则更新\(w_i,b_i\)
- 回到第2步,直到整个训练集中没有误分类点
从上面的算法,我们至少能读出这么几层意思:
- 初始值是随机给的,赋值为0是一个简便的做法,但通常设置为一个很小的随机值,后面会详细讨论
- 每次训练其实只用到一个样本点,即使训练集中有很多数据点亦是如此。这和 \(w_ix_i\)这个表达式的计算方式有关,详见上面的数值例子。
- 算法的重点在误分类这里,那么如何定义误分类就非常要紧了。
- 算法是一个迭代的过程,且要满足所有样本点都分类正确才停机。反过来理解,就是感知机算法只能运用于完全线性可分的数据集。如果数据集是不能完全线性可分的,感知机永远不会停机,除非训练之前先设置好停机条件,常见的比如设置训练次数或者误差上界(一旦误差小于$ \varepsilon $ 即可停机)。
显然,如何定义错误是感知机算法里的头等大事。
5. 该如何定义错误?
通俗定义:映射函数\(sign(wx + b)\)求解得到的值和原始标签值异号,即表示分类错误。
根据这个表述,我们可以很容易地将数据集分类:正确分类和错误分类。显然我们要做的事就是想办法让模型把分错的样本点分对,同时对于原本已经分对的点不能又分错了。
如果采用几何作图的方法,可以不断调整超平面(即上面提到的直线,术语上通称为超平面)来达到目标,只要给定的数据集是完全线性可分的。但是,如果是高维空间的数据集,几何直觉就不灵了,这时需要引入代数工具。而引入损失函数就是这样的工具,它和我们依靠几何直觉做的事情是相同的:把所有点分对 \(\iff\) 将损失函数降到最小。
损失函数的定义可以凭直觉而为:计算误分类样本的个数。例如样本空间共有\(M\)个样本,其中错误分类的样本属于区域\(E\),显然损失函数就是 \(\sum\limits_{i\in E}x_i\) 。但问题随之而来,我们没有工具来优化这个函数,使之向最小值运动。于是自然地想到,计算所有误分类点到超平面的距离,对距离之和做优化。具体的思路是这样的:
- 找到描述样本点到超平面距离的计算式
- 正确分类的样本点的距离和丢弃不看
- 定义误分类的距离和,对它求最小值
在\(R^n\)空间中,任何一个样本点\(x_0\)到超平面的距离公式 \(\frac{1}{||w||}|w\cdot x + b|\)。对于误分类来说,\(y_i(w \cdot x + b) < 0\),于是如果有一个误分类点\(x_0\),那么它到超平面的距离可以写作 \(-y_i\frac{1}{||w||}|w\cdot x + b|\)。对于所有的误分类来说,自然可以写出下面的损失函数:\[L(w,b) = -\sum\limits_{i\in E} y_i \frac{1}{||w||}|w\cdot x + b|\]。这里添加负号的目的是使得损失函数的值恒为正数,这样对它求最小值可以使用凸优化工具。显然地,误分类样本点越少,\(L(w,b)\)越小;误分类点离超平面的距离越小,\(L(w,b)\)越小。
这里舍弃掉\(\frac{1}{||W||}\)是因为它是一个正的系数,并且对于\(L(w,b)\)具有伸缩性,因此不影响最小化\(L(w,b)\)。
6. 知错后如何改错?
回顾微分学知识,我们知道一个全局的凸函数取得最小值是在导数为0处。但是,放在多元函数的观点来看,一元函数的导数本质上也是梯度。当一个函数沿着负梯度的方向运动是,函数值的减少是最快的;沿着正梯度方向运动时,函数值增加啊是最快的。下面我们就来求其梯度。
\[\frac{\partial L}{\partial w} = - \sum\limits_{x_i \in E} y_i x_i\]
\[\frac{\partial L}{\partial b} = - \sum\limits_{x_i \in E} y_i\]
我们来看关于\(w\)的梯度表达式,本质上就是找到所有的误分类点,然后把标签值\(y_i\)作为一个权重(\(+1/-1\))。如果\(x_1\)是一个被错误分类的点,假设这个点对应的原始标签是正类,现在被分成负类,所以在前面加一个符号,表示往反方向弥补。所以\(\sum\limits_{x_i \in E}y_ix_i\)
可以理解为通过所有错误分类的样本点拟合出一个运动方向,往那个方向运动可以弥补模型中\(w\)参数的错误。
而例1中,我们每次只选取一个样本点,假设这个样本点是\((x_i,y_i)\),那么更新公式就是 \(w = w + \eta y_i x_i\),其中的\(\eta\)是每次更新的步长,术语为学习率。同理,偏置项的更新公式为 \(b = b + \eta y_i\)。
7. \(Novikoff\) 定理
先叙述一下这个定理。定理来自李航老师的《统计学习方法》第二版Page42。
设训练数据集\(T = {(x_1,y_1),(X_2,y_2),...,(x_N,y_N)}\)是线性可分的,其中\(x_i \in X = R^n, y_i \in Y = \{-1,+1\}, i = 1,2,...,N\),则
(1) 存在满足条件\(||\hat{w}_{opt}|| = 1\)的超平面\(\hat{w}_{opt} \cdot \hat{x} = w_{opt} \cdot x + b_{opt}\)将训练数据集完全正确分开;且存在\(\gamma > 0\),对所有的\(i = 1,2,...,N\)有\[y_i (\hat{w}_{opt} \cdot \hat{x}_i) = y_i (w_{opt} \cdot x_i + b_{opt}) \ge \gamma\]
(2)令\(R = \max\limits_{1 \le i \le N} ||\hat{x}_i||\),则感知机算法在训练数据集上的误分类次数\(k\)满足不等式 \[k \le (\frac{R}{\gamma})^2\]
先从直觉上理解下这个定理表述的意思。大意是对于可以找出线性超平面做分类的数据集,存在一个下界$ \gamma $,所有样本点到超平面的距离都至少大于这个 $ \gamma $,同时错误分类的次数有一个上界,第 \(k+1\) 次之后,分类都是正确的,算法最终是收敛的。
证明
(1) 由于数据是线性可分的,因此一定存在一个分割超平面\(S\),不妨就取\(S\)的参数为\(\hat{w}_{opt}\),显然对于超平面上的所有点\(x\),都有\(\hat{w}_{opt} \cdot x = w_{opt} \cdot x + b_{opt} = 0\),并满足\(||\hat{w}_{opt}||=1\)。而对于训练数据集中的样本点,由于现在都被正确分类了,所以有\(\hat{w}_{opt} \cdot x_i > 0\),于是取 \(\gamma = \min\limits_{i} \{y_i(w_{opt} \cdot x_i + b_{opt} \}\),这就得到了下界。
(2) 由 \(k \le (\frac{R}{\gamma})^2\)推出\(k \gamma \le \sqrt{k} R\) 。
假设\((x_i,y_i)\)是一个在第\(k\)次被误分类的点,那么这件事的触发条件是 \(y_i (\hat{w}_{k-1} \cdot x_i) \le 0\).
由更新公式,\(\hat{w}_k = \hat{w}_{k-1} + \eta y_i \hat{x}_{i}\) .
\(\hat{w}_{k} \cdot \hat{w}_{opt} = \hat{w}_{k-1} \cdot \hat{w}_{opt} + \eta y_i \hat{w}_{opt} \cdot \hat{x}_i \ge \hat{w}_{k-1} \cdot \hat{w}_{opt} + \eta \gamma\) .
迭代\(k-1\)次立即得到 \(\hat{w}_{k} \cdot \hat{w}_{opt} \ge k\eta\gamma\).
对\(\hat{w}_k\)两边平方,
\(||\hat{w}_k||^2 = ||\hat{w}_{k-1}||^2 + 2\eta y_i \hat{w}_{k-1} \cdot \hat{x}_{i} + \eta^2 ||\hat{x}_{i}||^2\). 注意到中间这项是负数(因为这是误分类点)
立即得到 \(||\hat{w}_k||^2 \le ||\hat{w}_{k-1}||^2 + \eta^2 ||\hat{x}_{i}||^2 \le ||\hat{w}_{k-1}||^2 + \eta^2 R^2\).
迭代\(k-1\)次后立即得到 \(||\hat{w}_k||^2 \le k \eta^2 R^2\) .
即可建立不等式
\(k\eta\gamma \le \hat{w}_{k} \cdot \hat{w}_{opt} \le ||\hat{w}_{k}|| \cdot ||\hat{w}_{opt}|| \le \sqrt{k}\eta R\). 再稍加变形就得到欲证的式子。
这里\(R\)其实只是一个记号而已,它代表的意思是从所有误分类中找到模长最大的,而这个记号其实是从证明过程中产生的。
作为介绍感知机原理的文章,已经写得非常长啦,可以就此打住~
如果有任何纰漏差错,欢迎评论互动。
