现实生活中,人们往往很难知道总体的均值,比如我知道该网络上网的10000个人平均年龄是20岁,但不能了解该网络人群上网年龄总体均值究竟为多少,可能是30岁可能是25岁,所以往往有个笑话,总体均值是上帝才能知道的。
但是我们可以通过统计学来估计它。
写在前面
假设检验:是当总体均值μ已知时(假设我知道是某个值或者某个区间),我通过统计量的分布来检验该假设是否正确,
置信区间:是当总体均值μ未知时,我通过统计量去估计未知的总体均值在大概的区间里。
假设检验的概念(其实就两步)
第一步:提出假设
第二步:检验假设
假设检验具体的步骤
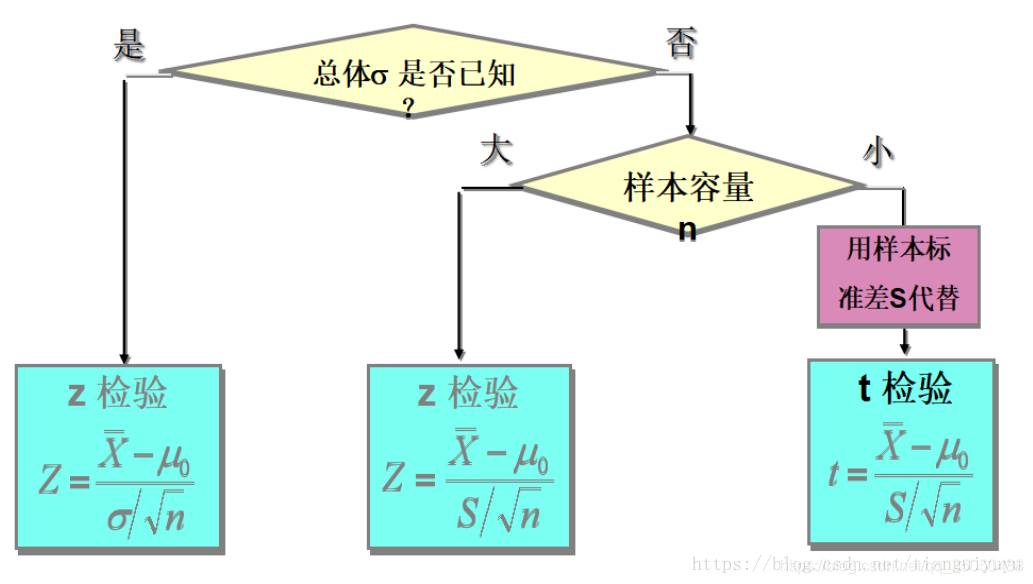
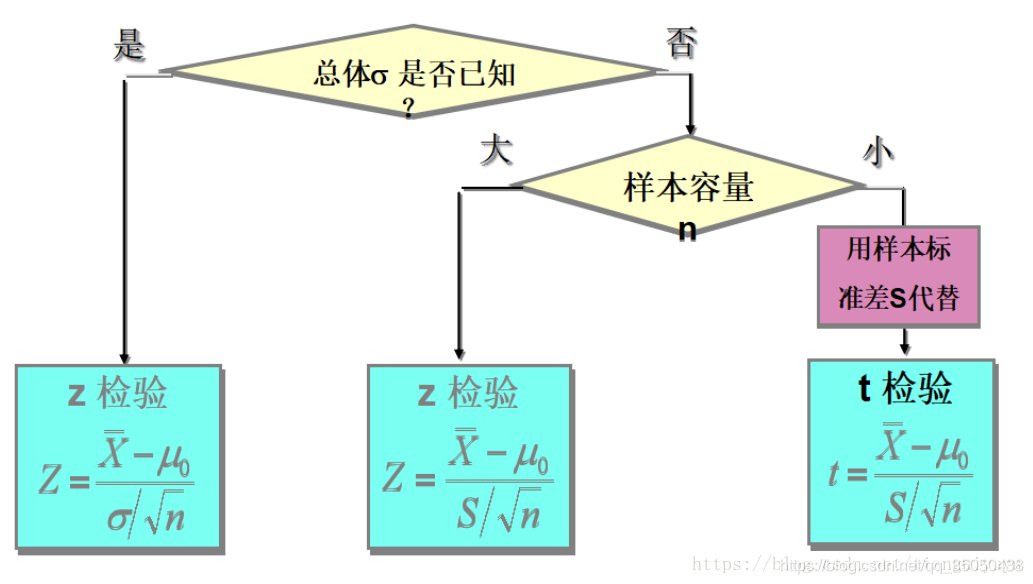
1.考虑找到提出的假设事件适合它的统计量,并写出它的分布(正态,二项,卡方,t,F等),然后去看总体方差和样本方差是否已知。
在我之前写的4大分布的博文里有介绍

2.然后默认假设成立,对假设事件的分布计算P(p-value)值进行检验
这个概率

即:总体均值与样本均值之差大于某个数的概率
即:事件极端情况(小概率发生)下发生的概率
(由中心极限定理我们可以知道样本数量大时,大部分样本均值是在总体均值附近的,所以差值大于某个数的话,我们判断这测出来的样本均值是极端情况,或者说是小概率事件)
1.首先我们会划分哪些为小概率事件
2.然后将小概率事件发生的概率相加起来
3.当事件样本非常大的时候,经过多年的检验的测算,我们发现一般相加得到的小概率事件发生的概率为0.05或者0.01或者0.1。(根据小概率原理)
4.我们将所有极端事件发生(小概率事件发生)的概率即0.05或者0.1定义为显著性水平
显著性水平为α,意为对于极端事件的极端字眼做一个界限
或者说是调控极端事件的极端程度
当原假设为真时所得到的样本观察结果或更极端结果出现的概率
p值我们一般取的是假设事件较为极端(小概率发生)的一面
如果我假设的事件主观上我认为发生概率很大,我的p值就设假设的反面,算反面的概率,如果我假设的事件主观上我认为发生概率很小,我的p值就设假设的正面,
但是我们一般把我们认为该事件不太可能发生的情况作为假设,为此来判断该事件是否为小概率事件,p越小越拒绝原假设,越大越接受原假设。
原因很简单:因为显著性水平是来评判小概率事件的,而要与显著性水平比较概率,我们也应该把事件的不太可能发生的情况作为假设来算概率与之检验。
3.将P值与显著水平进行比较,一般我们显著水平设为0.05
若我认为假设的事件发生概率很大,我p值设的是假设的反面
当P值比显著水平还小时,说明这个假设的反面事件发生概率巨小,明显假设正确。
当P值比显著水平还大时,说明这个假设的反面事件发生概率符合显著水平,假设假设错误。
若我认为假设的事件发生概率很小,我p值设的是假设的正面
当P值比显著水平还小时,说明这个假设事件发生概率巨小,明显假设错误。
当P值比显著水平还大时,说明这个假设事件发生概率符合显著水平,假设假设正确。
但是我们一般把我们认为该事件不太可能发生的情况作为假设,为此来判断该事件是否为小概率事件,p越小越拒绝原假设,越大越接受原假设。
这句话我要说两遍,因为总有人会把假设事件设为大概率事件。

这个为小概率事件发生的概率,展开写x拔到μ0的距离
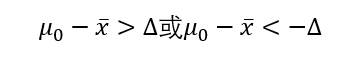
这就是拒绝域,
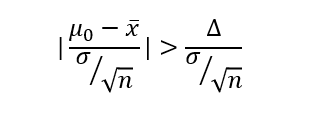
若总体方差知道,我们将其标准正态化,
若总体方差不知道,我们用样本标准差代替将其化为t分布化
所以我们既可以通过p值检验,也可以通过x拔是否在拒绝域里检验,貌似都是一样的。
置信区间的概念
理解前提:中心极限定理和大数定理
大数定理用一句话概括:
1.当你抽的样本越多,越接近总体的数量,那么他的样本均值越会趋近于总体均值。
中心极限定理两句话概括:
1.样本平均值约等于总体平均值。
2.不管总体是什么分布,抽的样本足够大时,样本平均值的分布呈正态分布。
(说人话就是我测1000个学生的学习水平能得到中国所有学生学习水平,因为抽样样本的平均值和总体样本的平均值差不多。而且呈正态分布,也就是你去抽1000份样本平均值,大部分都在总体平均值周围,2条正好更能说明1条是正确的)
格里文科定理用一句话概括:
1.样本容量极大时,样本的分布趋近于总体分布。
总体满足正态分布时,所抽取样本的均值分布始终符合正态分布(样本大小为1时,也满足)
总体不满足正态分布,但是单个样本大小>=30时,样本均值的分布符合正态分布;(中心极限定理)
置信区间是一种区间估计的方法。95%置信区间
因此,在取得样本足够大的时候,因为样本均值分布服从于正态分布,
