关键字:置信区间
1.置信区间
1.1.作用:描述一个区间有多大的概率包含未知参数
1.2.定义
设母体的概率函数为f(x;seta),seta为未知参数,有一个取自母体的子样,字样有n个数据。如果对事先给定的a,0<a<1,存在两个统计量seta1和seta2,使得P(seta1<seta<seta2)=1-a,即seta落在seta1和seta2之间的概率为1-a,就称区间(seta1,seta2)为置信度为1-a的置信区间,seta1,seta2分别是置信下界和上界。
1.3.寻找置信区间的步骤
3.1 寻找一个函数,它与子样有关,只包含seta这个未知参数而没有其他参数。这个函数服从某个常见的,方便求出的分布,比如正态分布,卡方分布等等。
3.2 对于给定的1-a,确定分位点
3.3 利用不等式变形,求出seta的范围,即为置信下界和上界。(概率论与数理统计P335开始)
例子:
子样均值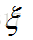
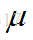
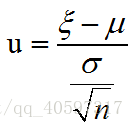
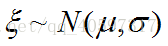
1.4 作用
是有样本统计量所构造的总体参数的估计区间,展示参数的真实值有一定的概率落在测试结果周围的概率
2.统计量:
2.1 定义
包含了样本总体信息的变量,只与样本有关,比如均值,方差,样本矩(比如k阶原点矩,k阶中心矩,也叫枢轴量)
2.2 统计量的一种:次序统计量
把x1,x2,..,xn按从小到大排列为x11,x22,..,xnn,那么最小顺序统计量为x11,最大顺序统计量为xnn,差距(Range)为xnn-x11,四分位为iql=X(0.75n)-X(0.25),就是第0.75n的次序统计量减去0.25n的次序统计量
x1,...,xn是独立同分布的,但是x11,...,xnn不独立分布也不相同,因为实际上是比较它们的大小,只要一个变化了,对其他的数据都会产生影响,影响他们的位置,所以不是独立同分布的。