目录
1、算法分析
一个程序的运行时间主要与两点有关:
- 执行每条语句的耗时(和硬件相关)
- 执行每条语句的频率
下面是我们对一个算法的运行时间分析所要进行的步骤,当我们在判断这个算法的运行时间长短时候,首先需要的就是获取这个算法每次运行完成所需要的时间,然后将这些时间数据绘图,x轴是数据量,y轴是运行时间,然后根据绘图推导出该算法的近似数学公式,然后验证,省略较小的项,最后得到就是我们所需要的一个算法的时间复杂度 O(n)。

下面的代码是求一个数组中三个数的和是0的整数元组的数量,这里就是利用语句的执行频率来推导程序的运行时间。

2、算法分析中常见函数

3、时间复杂度的常见级别

4、下界
程序在最坏的情况下的运行时间,我们称之为下界。(也就是最长运行时间)
5、内存分析
分析内存的使用要比分析程序的运行时间简单的多,主要的原因是它所涉及的语句较少(只有声明语句),且在分析中我们可以将复杂的对象简化为原始数据类型,而原始数据类型内存的使用是预先定义好的-----只需将变量的数量和它们的类型所对应的字节数分别相乘并汇总即可。

那么1G内存可以存多少个int类型值呢?
1千兆字节(gb)=1073741824字节(b)
1073741824字节/4字节~2.6亿个int类型的值
~ 约等于。
6、一个对象的内存
一个对象的内存=所有实例变量使用的内存+对象本身的开销(一般是16字节)
对象本身的开销=一个指向对象类的引用+垃圾回收信息+同步信息
另外一般内存的使用都会被填充为8字节(64位计算机中的机器字)的倍数。不够8的倍数,填充为8的倍数。
 Integer对象内存(24字节)= 对象开销(16字节)+int(4字节)+填充字节(4字节)
Integer对象内存(24字节)= 对象开销(16字节)+int(4字节)+填充字节(4字节)
 Date对象内存(32字节)=对象开销(16字节)+3*int(12字节)+填充字节(4字节)
Date对象内存(32字节)=对象开销(16字节)+3*int(12字节)+填充字节(4字节)
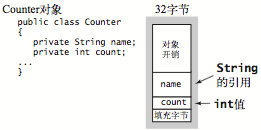 Counter对象内存(32字节)=对象开销(16)+String(8)+int(4)+填充字节(4)、
Counter对象内存(32字节)=对象开销(16)+String(8)+int(4)+填充字节(4)、
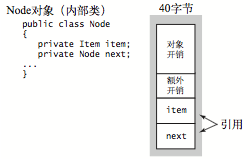 Node内存(40)=对象开销(16)+额外开销(8)+Item的引用(8)+Node的引用(8)
Node内存(40)=对象开销(16)+额外开销(8)+Item的引用(8)+Node的引用(8)
因为Node是一个非静态的内部类,所以它持有对外部类的引用,额外开销就是来之于对外部类的引用。
对对象的引用,其实就是一个机器地址,一个机器地址所需内存一般是8字节(64位架构的计算机,32为架构的是4字节)
7、链表栈的内存
一个Node对象占用内存是40字节,如果存储的是Integer类型的话,还需要加上Integer对象24字节,因为Item只算了引用所占的字节,那么链表中一个结点是64字节,LinkedStack<Integer> stack=new LinkedStack1<>(), 创建一个链表栈,还需要消耗16字节的链表栈对象开销,内部还有一个4字节的N,还需要填充4字节到达8的倍数。所以一个还有n条数据的链表栈所占内存。
n个Integer数据链表栈内存=16+4+4+(40+24)*n =32+64n 字节
public class LinkedStack<T> {
private Node first;
private int N = 0;// 集合的数量
// 结点
class Node {
T item;
Node next;
}
}
val stack: LinkedStack1<Int> = LinkedStack1()8、数组的内存
Java中数组被实现为对象,它们一般都会因为记录长度需要额外的内存。一个原始数据类型的数组一般需要24字节的头信息(16字节的对象开销+4字节用于保存长度+4字节填充)再加上保存值所需的内存。
 含有N个int类型的数组内存=24+4N(不够8的倍数会被填充)
含有N个int类型的数组内存=24+4N(不够8的倍数会被填充)
 含有N个double类型的数组内存=24+8N
含有N个double类型的数组内存=24+8N
 含有N个Date对象的数组内存=24+(8+32)*N
含有N个Date对象的数组内存=24+(8+32)*N
(其中32是一个Date对象所开销的内存,8是存在数组中对该Date对象的引用内存)

一个M*N的Double类型二维数组内存=24+24M+8M+8MN ~8MN
二维数组就是一个数组的数组,M*N的二维数组,就是第一层是一个M长度的数组,这个M长度数组内部存的每个元素都是一个对一个一维数组的引用,所以除了第一层数组所开销的24字节以外,还有M个第二层数组所开销的24*M字节,对M个数组的引用8*M字节,因为存的是double类型的数组,所以这M个第二层数组里边都存了N个double类型的值=8MN字节。
如果是存储对象的二位数组,比如上面的Date对象 那么所需内存就~(8+32)*MN
9、String的内存
String的标准实现含有四个实例变量,value是指向字符数组的引用(8字节),offset描述的是字符数组中的偏移量(4字节),count是值字符串的长度(4字节),hash是字符串的散列值(4字节),再加上对象的开销(16字节),以及填充字节(4字节)。
如果不计算所存的字符数组内存,一个String对象所需要内存是40字节。

String的char数组常常是在多个字符串之间共享的,这是因为String对象是不可变的,这种设计使String的实现能够在多个对象都含有相同的value[]数组是,节省空间。

一个长度为 N 的 String 对象一般需要使用 40 字节(String 对象本身)加上(24+2N)字节(字符数组),总共(64+2N)字节。
但字符串处理经常会和子字符串打交道,所以 Java 对字符串的表 示希望能够避免复制字符串中的字符。当你调用 substring() 方法时,就创建了一个新的 String 对象(40 字节),但它仍然重用了相同的 value[] 数组,因此该字符串的子字符串只会使用 40 字 节的内存。含有原始字符串的字符数组的别名存在于子字符串中,子字符串对象的偏移量和长度域 标记了子字符串的位置。换句话说,一个子字符串所需的额外内存是一个常数,构造一个子字符串 所需的时间也是常数,即使字符串和子字符串的长度极大也是这样。
codon字符串中的字符数组元素 是从value[0]-value[count-1]
子字符串genome的字符数组元素表示是从value[offset]-value[offset+count-1]
10、函数的内存
涉及函数调用时,内存的 消耗就变成了一个复杂的动态过程,因为 Java 系统 的内存分配机制扮演一个重要的角色,而这套机制 又和 Java 的实现有关。
例如,当你的程序调用一个 方法时,系统会从内存中的一个特定区域为方法分 配所需要的内存(用于保存局部变量),这个区域 叫做栈(Java 系统的下压栈)。当方法返回时,它 所占用的内存也被返回给了系统栈。
因此,在递归 程序中创建数组或是其他大型对象是很危险的,因 为这意味着每一次递归调用都会使用大量的内存。
当通过 new 创建对象时,系统会从堆内存的另一块 特定区域为该对象分配所需的内存。
而且, 你要记住所有对象都会一直存在,直到对它的引用 消失为止。此时系统的垃圾回收进程会将它所占用 的内存收回到堆中。这种动态过程使准确估计一个 程序的内存使用变得极为困难。
本文章的大部门内容来之于由Robert Sedgewick和Kevin Wayne著的《算法》第四版书籍中,本文章的目的主要是为了记录自己的学习笔记和技术分享。
