本文的应用场景是对于卫星图片数据的分类,图片总共1400张,分为airplane和lake两类,也就是一个二分类的问题,所有的图片已经分别放置在2_class文件夹下的两个子文件夹中。下面将从这个实例的详细拆解中,理解tensorflow2.0对于数据的处理过程。文章的案例数据和代码附在最后,通过点解链接可以直接在gothub上获取。
1 导入库
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
import pathlib
print(tf.__version__,tf.test.is_gpu_available())#tensorflow版本,gpu加速
('2.0.0-alpha0', True)2 数据处理
2.1 加载数据文件目录
data_dir = "D:/Program Files (x86)/tensorflow-data/dataset/2_class"2.2 设置数据路径对象
data_root = pathlib.Path(data_dir)
print(data_root)#生成一个路径对象
WindowsPath('D:/Program Files (x86)/tensorflow-data/dataset/2_class')2.3 路径对象迭代输出
for item in data_root.iterdir():#对里面所有的文件进行迭代
print(item)
D:\Program Files (x86)\tensorflow-data\dataset\2_class\airplane
D:\Program Files (x86)\tensorflow-data\dataset\2_class\lake2.4 加载所有图片数据路径,转变路径格式
all_image_paths = list(data_root.glob('*/*'))
image_count = len(all_image_paths)
print(image_count)
1400
print(all_image_paths[:3])
[WindowsPath('D:/Program Files (x86)/tensorflow-data/dataset/2_class/airplane/airplane_001.jpg'),
WindowsPath('D:/Program Files (x86)/tensorflow-data/dataset/2_class/airplane/airplane_002.jpg'),
WindowsPath('D:/Program Files (x86)/tensorflow-data/dataset/2_class/airplane/airplane_003.jpg')]
all_image_paths = [str(path) for path in all_image_paths]
print(all_image_paths[:3])
['D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\airplane\\airplane_001.jpg',
'D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\airplane\\airplane_002.jpg',
'D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\airplane\\airplane_003.jpg']2.5 查看图片数据路径并进行乱序排列
import random
random.shuffle(all_image_paths)
print(all_image_path[:3])
['D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\airplane\\airplane_437.jpg',
'D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\lake\\lake_553.jpg',
'D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\airplane\\airplane_293.jpg']2.6 标签预处理
label_names = sorted(item.name for item in data_root.glob('*/') if item.is_dir())
print(label_names)
['airplane', 'lake']2.7 确定标签
label_to_index = dict((name, index) for index,name in enumerate(label_names))
print(label_to_index)
{'airplane': 0, 'lake': 1}#为了模型输出,便于分类2.8 贴标签
#根据图片所在路径的文件夹进行贴标签
all_image_labels = [label_to_index[pathlib.Path(path).parent.name] for path in all_image_paths]
print(all_image_labels[:5])
[1, 0, 1, 0, 0]
print(all_image_paths[:5]) #进行对比
['D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\lake\\lake_622.jpg',
'D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\airplane\\airplane_602.jpg',
'D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\lake\\lake_459.jpg',
'D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\airplane\\airplane_243.jpg',
'D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\airplane\\airplane_640.jpg']2.9 检查标签是否贴正确
#使用IPython
import IPython.display as display
def caption_image(label):
return {0: 'airplane', 1: 'lake'}.get(label)
#这里需要将字典里面的元素进行对调,为了可视化
#和上面的进行对比 这里输出的是原来字典的键,上面输出的是值
for i in range(3):
image_index = random.choice(range(len(all_image_paths)))
display.display(display.Image(all_image_paths[image_index]))
print(caption_image(all_image_labels[image_index]))



plane lake lake
2.10 单张图片处理
#步骤:取一张图片,然后使用tf.io.read_file方法读取,解码图片,转换图片数据格式,最后是标准化
img_path = all_image_paths[0] #取一张图片
print(img_path )
'D:\\Program Files (x86)\\tensorflow-data\\dataset\\2_class\\lake\\lake_622.jpg'
img_raw = tf.io.read_file(img_path) #读取文件
print(repr(img_raw)[:100]+"...")
<tf.Tensor: id=13525, shape=(), dtype=string, numpy=b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x...'
img_tensor = tf.image.decode_image(img_raw) #解码图片
print(img_tensor.shape)
print(img_tensor.dtype)
(256, 256, 3)
<dtype: 'uint8'>
img_tensor = tf.cast(img_tensor, tf.float32) #转换图片数据格式
img_final = img_tensor/255.0 #数据标准化
print(img_final.shape)
print(img_final.numpy().min())
print(img_final.numpy().max())#查看数据
(256, 256, 3)
0.0
1.02.11 函数封装
#将单个图片处理的过程封装成函数,方便调用
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [256, 256])
image = tf.cast(image, tf.float32)
image = image/255.0 # normalize to [0,1] range
return image2.12 检验函数能否正常运行
image_path = all_image_paths[0]
label = all_image_labels[0]
plt.imshow(load_and_preprocess_image(img_path))
plt.grid(False)
plt.xlabel(caption_image(label))
plt.show()
3 卷积神经网络构建
3.1 创建图像路径的dataset,调用定义函数
path_ds = tf.data.Dataset.from_tensor_slices(all_image_paths)
AUTOTUNE = tf.data.experimental.AUTOTUNE
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
label_ds = tf.data.Dataset.from_tensor_slices(tf.cast(all_image_labels, tf.int64))
for label in label_ds.take(10): #查看数据处理结果
print(label_names[label.numpy()],end=" ")
lake airplane lake airplane airplane lake lake lake airplane airplane3.2 合并图像和标签,显示合并后数据的格式
image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))
print(image_label_ds)
<ZipDataset shapes: ((256, 256, 3), ()), types: (tf.float32, tf.int64)>3.3 划分测试集和训练集
#数据容量的确定和挑选
test_count = int(image_count*0.2)
train_count = image_count - test_count
print(test_count,train_count) #数据容量的确定
(280, 1120)
train_data = image_label_ds.skip(test_count) #数据挑选
test_data = image_label_ds.take(test_count)3.4 训练数据和测试数据的预处理
BATCH_SIZE = 32 #每次batch的次数
train_data = train_data.apply(
tf.data.experimental.shuffle_and_repeat(buffer_size=train_count))
train_data = train_data.batch(BATCH_SIZE)
train_data = train_data.prefetch(buffer_size=AUTOTUNE)
test_data = test_data.batch(BATCH_SIZE)
print(train_data) #得到最终可以输入到模型的数据
<PrefetchDataset shapes: ((None, 256, 256, 3), (None,)), types: (tf.float32, tf.int64)>3.5 搭建网络
model = tf.keras.Sequential() #顺序模型
model.add(tf.keras.layers.Conv2D(64, (3, 3), input_shape=(256, 256, 3), activation='relu'))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(128, (3, 3), activation='relu'))
model.add(tf.keras.layers.Conv2D(128, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(256, (3, 3), activation='relu'))
model.add(tf.keras.layers.Conv2D(256, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(512, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(512, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(1024, (3, 3), activation='relu'))
model.add(tf.keras.layers.GlobalAveragePooling2D())
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))3.6 网络节点详细查看
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 254, 254, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 252, 252, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 126, 126, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 124, 124, 128) 73856
_________________________________________________________________
conv2d_3 (Conv2D) (None, 122, 122, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 61, 61, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 59, 59, 256) 295168
_________________________________________________________________
conv2d_5 (Conv2D) (None, 57, 57, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 28, 28, 256) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 26, 26, 512) 1180160
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 13, 13, 512) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 5, 5, 512) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 3, 3, 1024) 4719616
_________________________________________________________________
global_average_pooling2d (Gl (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 1024) 1049600
_________________________________________________________________
dense_1 (Dense) (None, 256) 262400
_________________________________________________________________
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 10,719,562
Trainable params: 10,719,562
Non-trainable params: 03.7 模型编译
model.compile(optimizer='adam',
loss='binary_crossentropy', #最后是二分类,特殊的softmax类型
metrics=['acc']
)3.8 模型拟合及数据记录
import time
start = time.perf_counter()
steps_per_epoch = train_count//BATCH_SIZE
validation_steps = test_count//BATCH_SIZE
history = model.fit(train_data, epochs=30, steps_per_epoch=steps_per_epoch,
validation_data=test_data, validation_steps=validation_steps)
end = time.perf_counter()
print("拟合总共用时{:.2f}s".format(end-start))Epoch 1/30
35/35 [==============================] - 31s 875ms/step - loss: 0.7211 - acc: 0.5027 - val_loss: 0.6951 - val_acc: 0.1172
Epoch 2/30
35/35 [==============================] - 29s 815ms/step - loss: 0.5313 - acc: 0.7098 - val_loss: 0.3036 - val_acc: 0.8867
Epoch 3/30
35/35 [==============================] - 29s 829ms/step - loss: 0.2698 - acc: 0.9134 - val_loss: 0.1746 - val_acc: 0.9297
Epoch 4/30
35/35 [==============================] - 29s 824ms/step - loss: 0.2053 - acc: 0.9411 - val_loss: 0.1350 - val_acc: 0.9570
Epoch 5/30
35/35 [==============================] - 29s 825ms/step - loss: 0.2569 - acc: 0.9375 - val_loss: 0.5585 - val_acc: 0.7305
Epoch 6/30
35/35 [==============================] - 29s 830ms/step - loss: 0.2657 - acc: 0.9107 - val_loss: 0.1286 - val_acc: 0.9453
Epoch 7/30
35/35 [==============================] - 29s 825ms/step - loss: 0.1469 - acc: 0.9554 - val_loss: 0.1590 - val_acc: 0.9375
Epoch 8/30
35/35 [==============================] - 29s 832ms/step - loss: 0.1159 - acc: 0.9607 - val_loss: 0.0892 - val_acc: 0.9727
Epoch 9/30
35/35 [==============================] - 29s 817ms/step - loss: 0.0968 - acc: 0.9705 - val_loss: 0.1128 - val_acc: 0.9609
Epoch 10/30
35/35 [==============================] - 29s 820ms/step - loss: 0.1127 - acc: 0.9723 - val_loss: 0.1272 - val_acc: 0.9727
Epoch 11/30
35/35 [==============================] - 29s 818ms/step - loss: 0.0943 - acc: 0.9714 - val_loss: 0.1270 - val_acc: 0.9609
Epoch 12/30
35/35 [==============================] - 29s 827ms/step - loss: 0.1240 - acc: 0.9670 - val_loss: 0.1464 - val_acc: 0.9570
Epoch 13/30
35/35 [==============================] - 29s 826ms/step - loss: 0.1280 - acc: 0.9643 - val_loss: 0.1634 - val_acc: 0.9531
Epoch 14/30
35/35 [==============================] - 29s 831ms/step - loss: 0.1101 - acc: 0.9696 - val_loss: 0.0849 - val_acc: 0.9766
Epoch 15/30
35/35 [==============================] - 29s 826ms/step - loss: 0.0896 - acc: 0.9732 - val_loss: 0.1183 - val_acc: 0.9688
Epoch 16/30
35/35 [==============================] - 29s 835ms/step - loss: 0.0862 - acc: 0.9732 - val_loss: 0.1107 - val_acc: 0.9727
Epoch 17/30
35/35 [==============================] - 29s 818ms/step - loss: 0.1507 - acc: 0.9670 - val_loss: 0.0825 - val_acc: 0.9727
Epoch 18/30
35/35 [==============================] - 29s 821ms/step - loss: 0.3248 - acc: 0.9009 - val_loss: 0.4892 - val_acc: 0.6602
Epoch 19/30
35/35 [==============================] - 29s 823ms/step - loss: 0.4364 - acc: 0.8214 - val_loss: 0.3518 - val_acc: 0.8047
Epoch 20/30
35/35 [==============================] - 29s 830ms/step - loss: 0.2347 - acc: 0.9393 - val_loss: 0.0921 - val_acc: 0.9727
Epoch 21/30
35/35 [==============================] - 29s 823ms/step - loss: 0.1249 - acc: 0.9688 - val_loss: 0.1061 - val_acc: 0.9688
Epoch 22/30
35/35 [==============================] - 29s 832ms/step - loss: 0.1276 - acc: 0.9598 - val_loss: 0.1071 - val_acc: 0.9766
Epoch 23/30
35/35 [==============================] - 29s 841ms/step - loss: 0.1179 - acc: 0.9643 - val_loss: 0.1016 - val_acc: 0.9688
Epoch 24/30
35/35 [==============================] - 29s 821ms/step - loss: 0.1047 - acc: 0.9696 - val_loss: 0.0965 - val_acc: 0.9688
Epoch 25/30
35/35 [==============================] - 29s 824ms/step - loss: 0.1092 - acc: 0.9688 - val_loss: 0.0430 - val_acc: 0.9883
Epoch 26/30
35/35 [==============================] - 29s 829ms/step - loss: 0.1042 - acc: 0.9670 - val_loss: 0.1029 - val_acc: 0.9688
Epoch 27/30
35/35 [==============================] - 29s 830ms/step - loss: 0.1079 - acc: 0.9661 - val_loss: 0.0668 - val_acc: 0.9844
Epoch 28/30
35/35 [==============================] - 29s 835ms/step - loss: 0.0795 - acc: 0.9750 - val_loss: 0.0550 - val_acc: 0.9766
Epoch 29/30
35/35 [==============================] - 29s 843ms/step - loss: 0.0795 - acc: 0.9759 - val_loss: 0.0554 - val_acc: 0.9766
Epoch 30/30
35/35 [==============================] - 29s 835ms/step - loss: 0.0706 - acc: 0.9759 - val_loss: 0.0595 - val_acc: 0.9844
拟合总共用时870.26s这里使用了gpu加速,如果不使用的话,每个epoch只用cpu跑的话大概是700s。
3.9 绘制loss和val_loos曲线
print(history.history.keys())
dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])
plt.plot(history.epoch, history.history.get('acc'), label='acc')
plt.plot(history.epoch, history.history.get('val_acc'), label='val_acc')
plt.legend()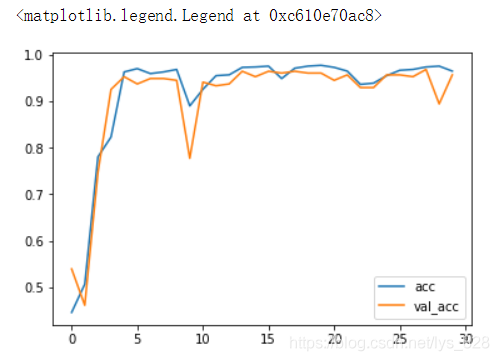
3.10 绘制acc和val_acc曲线
plt.plot(history.epoch, history.history.get('loss'), label='loss')
plt.plot(history.epoch, history.history.get('val_loss'), label='val_loss')
plt.legend()
本案例的数据和代码已经上传到github,实例的解析仅是用于加深对tensorflow利用卷积神经网络处理数据的理解过程,以及思维的梳理。https://github.com/Muzi828/CNN_airplane-lake_classify
