一、神经网络
1、全连接层(前向传播)
(1)张量方式实现:tf.matmul

(2)层方式实现:
① layers.Dense(输出节点数,激活函数),输入节点数函数自动获取
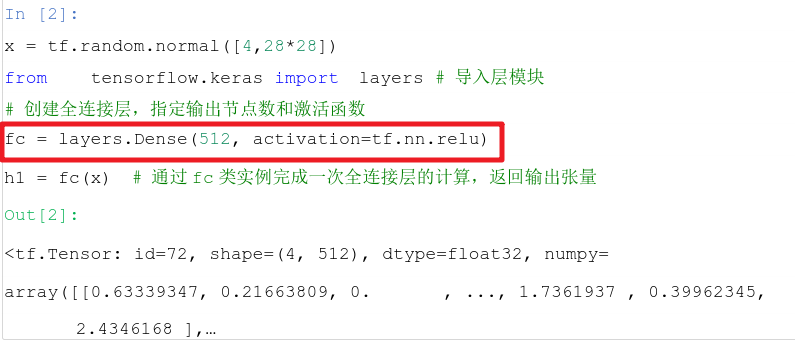
fc.kernel:获取权值矩阵 W
fc.bias:获取偏置向量 b

扫描二维码关注公众号,回复:
10159769 查看本文章

fc.trainable_variables:返回待优化参数列表

fc.non_trainable_variables:不需要优化的参数列表,如Batch Normalization 层。
fc.variables :返回所有内部张量列表

② Sequence容器:可通过Sequence容器封装成一个网络大类对象。
# 导入 Sequential容器 from tensorflow.keras import layers,Sequential # 通过 Sequential容器封装为一个网络类 model = Sequential([ layers.Dense(256, activation=tf.nn.relu) , # 创建隐藏层 1 layers.Dense(128, activation=tf.nn.relu) , # 创建隐藏层 2 layers.Dense(64, activation=tf.nn.relu) , # 创建隐藏层 3 layers.Dense(10, activation=None) , # 创建输出层 ])
out = model(x) # 前向计算得到输出
2、激活函数
- tf.nn.sigmoid(x):
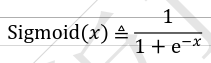
- tf.nn.softmax(x):
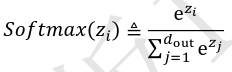
- tf.nn.relu(x) :
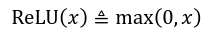
- tf.nn.leaky_relu(x,alpha):
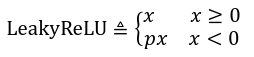 ,alpha为p
,alpha为p - tf.nn.tanh(x):

3、误差计算
- 均方误差MSE:keras.losses.MSE(y_实际, y_预测) 或者 keras.losses.MeanSquaredError:
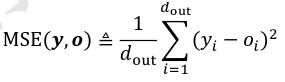
o = tf.random.normal([2,10]) # 构造网络输出 y_onehot = tf.constant([1,3]) # 构造真实值 y_onehot = tf.one_hot(y_onehot, depth=10) #直接计算 loss = keras.losses.MSE(y_onehot, o) # 计算均方差 loss = tf.reduce_mean(loss) # 计算 batch均方差 #层方式 criteon = keras.losses.MeanSquaredError() loss = criteon(y_onehot,o) # 计算 batch均方差
- 交叉熵误差:keras.losses.categorical_crossentropy(实际,预测)或者keras.losses.CategoricalCrossentropy(from_logits=True)
z = tf.random.normal([2,10]) # 构造输出层的输出 y_onehot = tf.constant([1,3]) # 构造真实值 y_onehot = tf.one_hot(y_onehot, depth=10) # one-hot编码 # 输出层未使用 Softmax函数,故 from_logits设置为 True ####方式一 # 这样 categorical_crossentropy函数在计算损失函数前,会先内部调用 Softmax函数 loss = keras.losses.categorical_crossentropy(y_onehot,z,from_logits=True) loss = tf.reduce_mean(loss) # 计算平均交叉熵损失 ####方式二 # 创建 Softmax与交叉熵计算类,输出层的输出 z未使用 softmax criteon = keras.losses.CategoricalCrossentropy(from_logits=True) loss = criteon(y_onehot,z) # 计算损失
4、反向传播
(1)构建梯度记录器(梯度跟踪): with tf.GradientTape() as tape
(2)记录梯度信息(非 tf.Variable类型的张量需要人为设置记录梯度信息 ):tape.watch([w1, b1, w2, b2])
(3)求解偏导(反向传播):grads = tape.gradient(y, [w])[0]
x = tf.constant([4., 0.]) # 初始化参数 for step in range(200):# 循环优化 200次 with tf.GradientTape() as tape: #梯度跟踪 tape.watch([x]) # 加入梯度跟踪列表 y = himmelblau(x) # 前向传播 # 反向传播 grads = tape.gradient(y, [x])[0] # 更新参数,0.01为学习率 x -= 0.01*grads # 打印优化的极小值 if step % 20 == 19: print ('step {}: x = {}, f(x) = {}' .format(step, x.numpy(), y.numpy()))