文章目录
引入包
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from urllib.parse import quote
import time
from bs4 import BeautifulSoup
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
按url获取页面信息
# 直接获取输入为关键词和页数,返回页内容
def get_info(keyword, page_num):
# 经过观察,url页数为实际页数的二倍减一
# 一定要加enc=utf-8这一句不然会乱码
url = 'https://search.jd.com/Search?keyword='+quote(keyword)+'&enc=utf-8&page='+str(2*page_num-1)
browser = webdriver.Chrome()
info = ''
try:
browser.get(url)
info = browser.page_source
finally:
browser.close()
return info
模拟点击获取页面信息
# 直接获取输入为关键词和页数,返回总页数和页内容
def get_info2(keyword, page_num, browser):
# 一定要加enc=utf-8这一句不然会乱码
url = 'https://search.jd.com/Search?keyword='+quote(keyword)+'&enc=utf-8'
wait = WebDriverWait(browser, 10)
info = ''
total_page = 0
browser.get(url)
total_page_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > em:nth-child(1) > b')))
total_page = total_page_element.text
# 拖动两次到最底部以加载完整页面
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
if page_num > 1:
# 定位用户输入页数的组件
minput = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > input')))
# 定位页数提交键所在组件
msubmit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > a')))
minput.clear()
minput.send_keys(page_num)
msubmit.click()
# 拖动两次到最底部以加载完整页面
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
# 确认当前页数等于目标页数
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.curr'),str(page_num)))
info = browser.page_source
return total_page, info
# 测试用
browser = webdriver.Chrome()
try:
get_info2('华为',1, browser)
finally:
browser.close()
分析页面信息
def parse_page(input_page):
soup = BeautifulSoup(input_page)
products = soup.select("li.gl-item")
names = []
shops = []
prices = []
for product in products:
# print(product.select_one("div.p-name a")["title"])
names.append(product.select_one("div.p-name em").text)
if product.select_one("div.p-shop a") == None:
shops.append("京东自营")
else:
shops.append(product.select_one("div.p-shop a").string)
prices.append(product.select_one("div.p-price i").string)
return pd.DataFrame(data={"名称":names, "店铺":shops, "价格":prices})
查询函数
def query_product(keyword, page_num):
browser = webdriver.Chrome()
writer = pd.ExcelWriter("./"+keyword+"汇总.xlsx")
try:
maxpage, page = get_info2(keyword,1, browser)
# 防止页数过大
if int(maxpage) < page_num:
page_num = maxpage
parse_page(page).to_excel(writer,sheet_name='第1页',index=False)
for i in range(2, page_num+1):
_,page = get_info2(keyword,i, browser)
parse_page(page).to_excel(writer,sheet_name='第'+str(i)+'页',index=False)
finally:
browser.close()
writer.save()
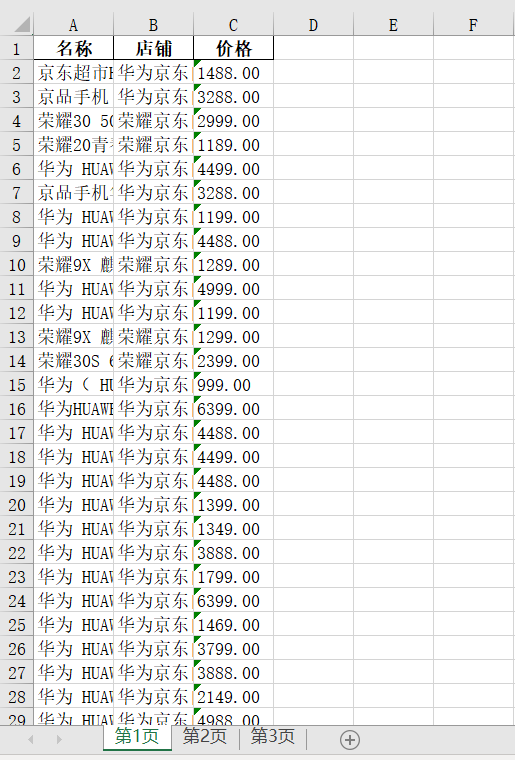
query_product('华为', 3)
抓取华为关键词前三页的效果图如下