【R描述统计分析】多元数据的数据特征与相关分析
在R中,计算多元数据的均值与方差采用数据框的结构输入数据,计算比较方便。
二元数据的数据特征及相关系数
例如对矿石中的两种成分进行统计分析:

ore<-data.frame(
x=c(67, 54, 72, 64, 39, 22, 58, 43, 46, 34),
y=c(24, 15, 23, 19, 16, 11, 20, 16.1, 17, 13)
)
ore.m<-mean(ore); ore.m
ore.s<-cov(ore); ore.s
ore.r<-cor(ore); ore.r
attach(ore)
cor.test(x,y)
cor.test(x,y, method="spearman")
cor.test(x,y, method="kendall")
mean( ) 函数 计算均值
cov( ) 函数 计算协方差
cor( ) 函数 计算相关矩阵(相关系数)
cov.wt 计算加权协方差
cor.test 计算相关性检验
cov(ore) = var(ore)
二元数据的相关性检验
对于二元数据:
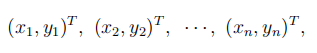
可以计算出样本的相关系数r
且总体的相关系数为:
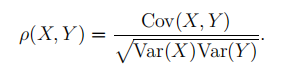
当样本的个数n充分大时,样本的相关系数r可以作为总体相关系数的估计,即样本个数较大时,样本相关,总体也相关。
问题是:当样本个数n取到多少时,样本相关才能得到总体相关?
Ruben置信区间的近似逼近公式
Ruben(鲁宾)给出了总体相关系数的区间估计的近似逼近公式
设n是样本个数,r是样本相关系数,u是标准正态分布的上α/2分位点,则计算

按照上述计算公式,编写R程序:
ruben.test<-function(n, r, alpha=0.05){
u<-qnorm(1-alpha/2)
r_star<-r/sqrt(1-r^2)
a<-2*n-3-u^2; b<-r_star*sqrt((2*n-3)*(2*n-5))
c<-(2*n-5-u^2)*r_star^2-2*u^2
y1<-(b-sqrt(b^2-a*c))/a
y2<-(b+sqrt(b^2-a*c))/a
data.frame(n=n, r=r, conf=1-alpha,
L=y1/sqrt(1+y1^2), U=y2/sqrt(1+y2^2))
}
将n,r调入已编好的ruben.test() 函数中
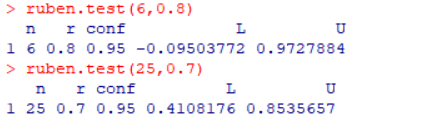
①n=6,r=0.8
置信区间为(﹣0.095,0.97),其置信下界是负数,即使r=0.8,也不能说明总体是相关的
②n=25,r=0.7
置信区间为(0.41,0.85),此时基本能说总体是相关的
关于置信区间的近似逼近方法还有David提出的图表方法,Kendall和Stuart提出的Fisher逼近方法等。
Pearson相关性检验
确认总体是否相关最有效的方法是作总体(X,Y)^T 的相关性检验,可以证明
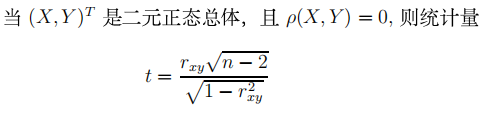
服从自由度为n-2的t分布
利用此分布的性质,可以对数据X和Y的相关性进行检验,该方法称为Pearson相关性检验。
此外,还有Spearman秩检验和Kendall秩检验,R软件中的cor.test()提供了这三种检验方法。
cor.test()使用方法
cor.test(x,y,
alternative = c("two.sided","less","spearman"),
method = c("pearson","kendall","spearman"),
exact = NULL, conf.level = 0.95,...)

另一种使用格式:
cor.test(formula, data, subset, na.action, ...)
多元数据的数字特征及相关矩阵
关于相关性检验,R软件没有为多元数据提供更多的函数,仍是cor.test()作两两分量的相关性检验
例:



从计算结果可以看出,X1,X2,X3两两均是不相关的
多元数据的图表示方法
轮廓图
outline<-function(x, txt=TRUE){
# x is a matrix or data frame of data
if (is.data.frame(x)==TRUE)
x<-as.matrix(x)
m<-nrow(x); n<-ncol(x)
plot(c(1,n), c(min(x),max(x)), type="n",
main="The outline graph of Data",
xlab="Number", ylab="Value")
for(i in 1:m){
lines(x[i,], col=i)
if (txt==TRUE){
k<-dimnames(x)[[1]][i]
text(1+(i-1)%%n, x[i,1+(i-1)%%n], k)
}
}
}

星图

R软件中给出了作星图的函数stars()
stars(x)

调整stars中的参数:
stars(x, full=FALSE, draw.segments = TRUE,
key.loc = c(5,0.5), mar = c(2,0,0,0) )

调和曲线图
调和曲线图是Andrews提出来的三角表示法,其思想是将多维空间中的一个点对应于二维平面的一条直线,对于p维数据,假设X_r是第r观测值,即
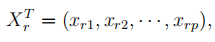
则对应的调和曲线是
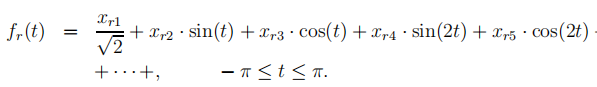
n次观测数据对应n条曲线,在同一张纸上就是一张调和曲线图,当各变量数据的数值相差太大时,先标准化再画图。
按照上述计算式,编写调和曲线函数:
unison<-function(x){
# x is a matrix or data frame of data
if (is.data.frame(x)==TRUE)
x<-as.matrix(x)
t<-seq(-pi, pi, pi/30)
m<-nrow(x); n<-ncol(x)
f<-array(0, c(m,length(t)))
for(i in 1:m){
f[i,]<-x[i,1]/sqrt(2)
for( j in 2:n){
if (j%%2==0)
f[i,]<-f[i,]+x[i,j]*sin(j/2*t)
else
f[i,]<-f[i,]+x[i,j]*cos(j%/%2*t)
}
}
plot(c(-pi,pi), c(min(f),max(f)), type="n",
main="The Unison graph of Data",
xlab="t", ylab="f(t)")
for(i in 1:m) lines(t, f[i,] , col=i)
}
unison(x)得到图像如下

