多元考试练习:
文章目录
一. 多元线性回归模型:
q1 = read.table(“clipboard”,head = T)
1. 建立回归模型
fm = lm (y~x1+x2+x3,data = q1)
fm
summary(fm)


2. 逐步筛选
逐步回归:
fm_step = step(fm,direcation = “both”)#both为逐步筛选法,forward为向前引入法,backward为向后引入法
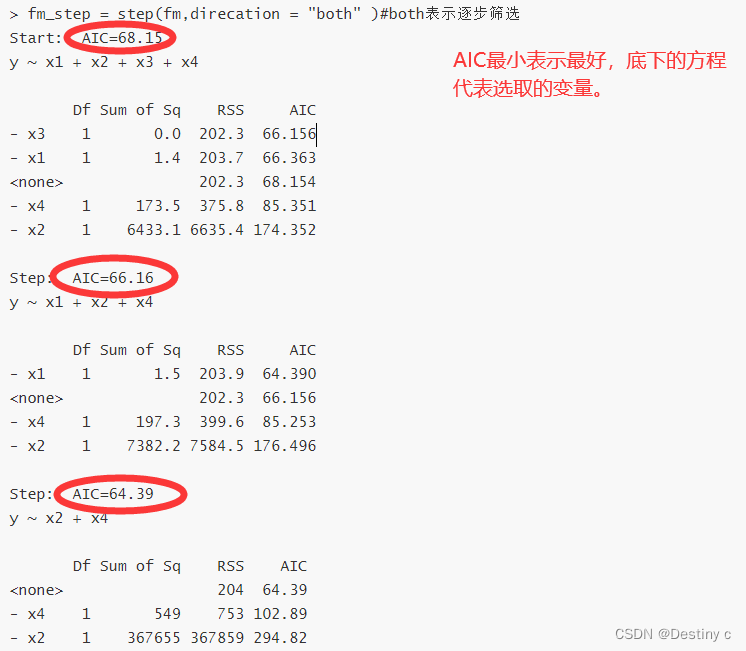
全局择优法:
对每组子集, RSS越小、R2越大、调整R2越大、AIC BIC越小,模型越好。
>library(leaps) ##安装包leaps
>varsel=regsubsets(y~ x1+ x2+ x3+ x4,data=yX)
#多元数据线性回归变量选择模型
>result=summary(varsel) #变量选择方法结果
>data.frame(result$outmat,RSS=result$rss,R2=result$rsq,adjR2=result$adjr2,Cp=result$cp,BIC=result$bic)
#RSS、R2、调整R2、cp、BIC结果展示
3. 最优标准方程,影响最大
#选择x24,下面则写对应的变量
> fm_2=lm(formula = y ~ x2 + x4, data = q1)
> fm_2#这是选择后未标准化的方程
summary(fm_2)#确认p值都小于要求
> #q:根据变量筛选结果,写出标准化后的回归方程,指出哪个自变量影响最大。
> library(mvstats)
> coef.sd(fm_2)
$coef.sd
x2 x4
1.02788885 -0.03972031
> #ans:标准化后的方程为y = 1.027x2 - 0.039x4,值越大影响越大,这里x2的影响最大
4. 全局择优法(使用4.2.1版本的R):
> library(leaps) ##安装包leaps
> varsel=regsubsets(y~ x1+ x2+ x3+ x4,data=yX)
> result=summary(varsel)
>data.frame(result$outmat,RSS=result$rss,R2=result$rsq,adjR2=result$adjr2,Cp=result$cp,BIC=result$bic)
5.分析
偏回归系数b2,b4的p值都小于0.01,可认为解释变量税收x2和经济活动人口x4显著;b1,b3的p值大于0.50,不能否定b1=0,b3=0的假设。可认为国内生产总值x1和进出口贸易总额x3对财政收入y没有显著的影响。我们可以看到,国内生产总值、经济活动人口所对应的偏回归系数都为负,这与经济现实是不相符的。出现这种结果的可能原因是这些解释变量之间存在高度的共线性。

6.由标准化偏回归系数可见,方差分析结果
> coef.sd(fm)
> anova(fm)
二. 判别分析
q2 = read.table(“clipboard”,head = T);q2
library(MASS)
attach(X)#打开数据,才可以用每列分量
1. 线性判别,贝叶斯判别正确率
线性:
> ld = lda(G~x1+x2+x3+x4+x5+x6+x7,prior = c(1,1,1)/3)
> z = predict(ld)
> newG = z$class
> cbind(q2$G,z$x,newG)#q2要记得修改,G也有可能改
> tab=table(q2$G,newG)
> tab
> sum(diag(prop.table(tab)))
#tab 后面的就是正确率
贝叶斯:
> ld2 = lda(G~x1+x2+x3+x4+x5+x6+x7,prior = c(24,10,14)/48)
或者直接ld2 = lda(G~x1+x2+x3+x4+x5+x6+x7,data = q2);ld2
> ld2
> z2=predict(ld2)
> cbind(G,z2$x,z2$class)
> tab2 = table(G,z2$class)
> sum(diag(prop.table(tab2)))
二次判别:
#二次判别(异方差)
> qd=qda(G~Q+C+P,data=X, prior = c(1, 1, 1)/3)
2. 预测情况
predict(ld,data.frame(x1=,x2=))#ld写入用来预测的模型,x12=写入传入的值。
> predict(ld,data.frame(x1=45,x2=1,x3=0,x4=1,x5=2,x6=33,x7=5.675))#写入值

圈圈里面表示处于的情况(G值)
3. 线性函数的迹为
> (ld=lda(G~Q+C+P,prior=c(1,1,1)/3))
Call:
lda(G ~ Q + C + P, prior = c(1, 1, 1)/3)
Prior probabilities of groups: #先验概率值,表示每类在原样本所占的比例
1 2 3
0.3333333 0.3333333 0.3333333
Group means: #每类的均值
Q C P
1 8.400000 5.900000 48.200
2 7.712500 7.250000 69.875
3 5.957143 3.714286 34.000
Coefficients of linear discriminants: #写出线性判别函数
LD1 LD2
Q -0.92307369 0.76708185
C -0.65222524 0.11482179 G=-0.923Q-0.652C+0.027P
P 0.02743244 -0.08484154 G=0.767Q+0.115C-0.085
Proportion of trace: #两个判别函数的迹(判别函数的判别能力)
LD1 LD2
0.7259 0.2741
4. 其他后验概率
(1)线性判别
> library(MASS) ##载入MASS函数包
> ld=lda(G~.,data=Case5,prior = c(1, 1)/2);ld #线性判别(省略是对所有的自变量进行..)
> Zld=predict(ld) ##判别
> data.frame(Case5$G,Zld$class,round(Zld$x,3))
> addmargins(table(Case5$G,Zld$class))#在列联表上添加边缘列
1 2 Sum
1 24 1 25
2 3 18 21
Sum 27 19 46
准确率为(24+18)/46=91.3%
(2)二次判别
> qd=qda(G~.,data=Case5,prior=c(1,1)/2);qd #二次判别
> Zqd=predict(qd)
> data.frame(Case5$G,Zqd$class,round(Zqd$post,3)*100)
> addmargins(table(Case5$G,Zqd$class))
1 2 Sum
1 24 1 25
2 2 19 21
Sum 26 20 46
准确率为(24+19)/46=93.5%
(3)贝叶斯判别
> ld2=lda(G~.,data=Case5);ld2 ##不设定先验概率,即默认为样本中的比例。
> Zld2=predict(ld2)
> data.frame(Case5$G,Zld2$class,round(Zld2$x,3))
> addmargins(table(Case5$G,Zld2$class))
1 2 Sum
1 24 1 25
2 3 18 21
Sum 27 19 46
> Zld2$post##后验概率
此外还可以使用predict(model)$posterior提取后验概率。
>predict(ld2)$posterior
在使用lda和qda函数时注意:其假设是总体服从多元正态分布,若不满足的话则谨慎使用。
三. logistic模型
注意G值只能是0或者1
1.逐步筛选法后最优表达式,并预测
> q3 = read.table("clipboard",head=T)
> q3
#建议直接使用逐步。
> logit.glm = glm(G~x1+x2,family=binomial,data=q3)
##> summary(logit.glm)#此时需要查看p值是否满足。
> glm.new = step(logit.glm)
> summary(glm.new)
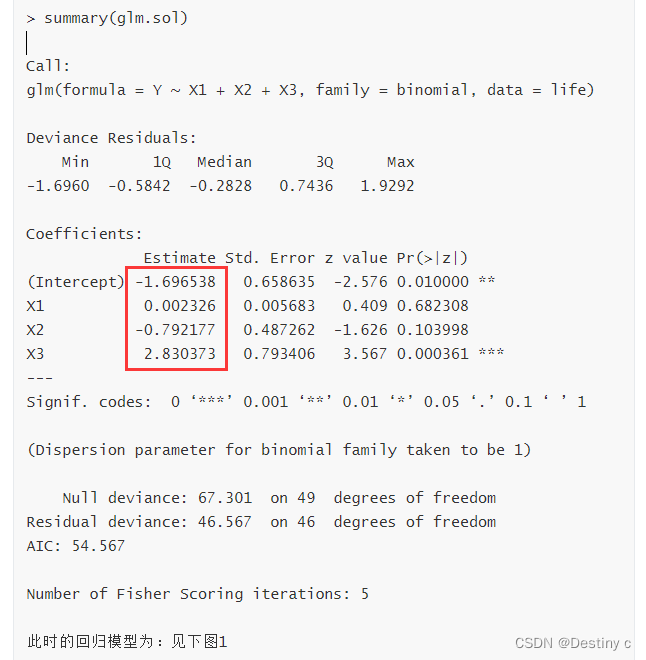
从计算结果来看,所有系数均通过了检验(α=0.1),没有则需要进行glm.new = step(logit.glm)此时回归模型为
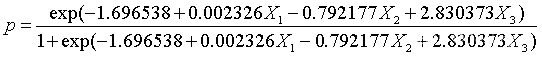

2. 预测y=1时的概率
#计算的是y=1的概率,pre表示预测值
> p=predict(glm.new, data.frame(x=3.5), type="response")
> p
#############
> pre<-predict(glm.new, data.frame(x2=2,x3=0))
> p<-exp(pre)/(1+exp(pre));p
3. 反向预测
可以作控制,如有50%的牛有响应,其电流强度为多少?
> X<- - glm.sol$coefficients[1]/glm.sol$coefficients[2];X
(Intercept)
2.649439
即2.65mA的电流强度,可以使50%的牛有响应。
当p=0.5,即
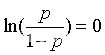
所以
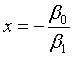
4. 对数线性模型,完全随机设计模型,随机单位设计模型,析因设计模型,正交实验设计模型
log.glm <-glm(y~x1+x2,family=poisson(link=log),data=x)
四. 主成分分析(相关系数矩阵)
q4 = read.table(“clipboard”,head = T)
q4
1. 主成分相关
方差贡献率达到%情况下,最少的主成分个数为,其累计方差贡献率为,第一主成分方差,第一主成分表达式
> PCA=princomp(q4,cor = T)#T表示使用相关系数矩阵
> PCA
> summary(PCA,loading = T)
screeplot(PCA,type="lines")###碎石图
我们从第一主成分对应系数的符号可以看出,x1到x8消费越高,Z1的值越小,Z1的绝对值越大。从第二主成分来看,正号大小多过负号大小,可认为x1到x8消费越高,Z2*的值越大。



2.综合得分公式以及排名
计算主成分得分
>predict(PCA)
综合得分
> princomp.rank(PCA,m=2,plot=T)##排名

3.其他

主成分方差 = 标准差的平方
五.聚类分析
q5 = read.table(“clipboard”,head = T);q5
qb5 = scale(q5)#标准化处理
1. 采用不同法进行聚类
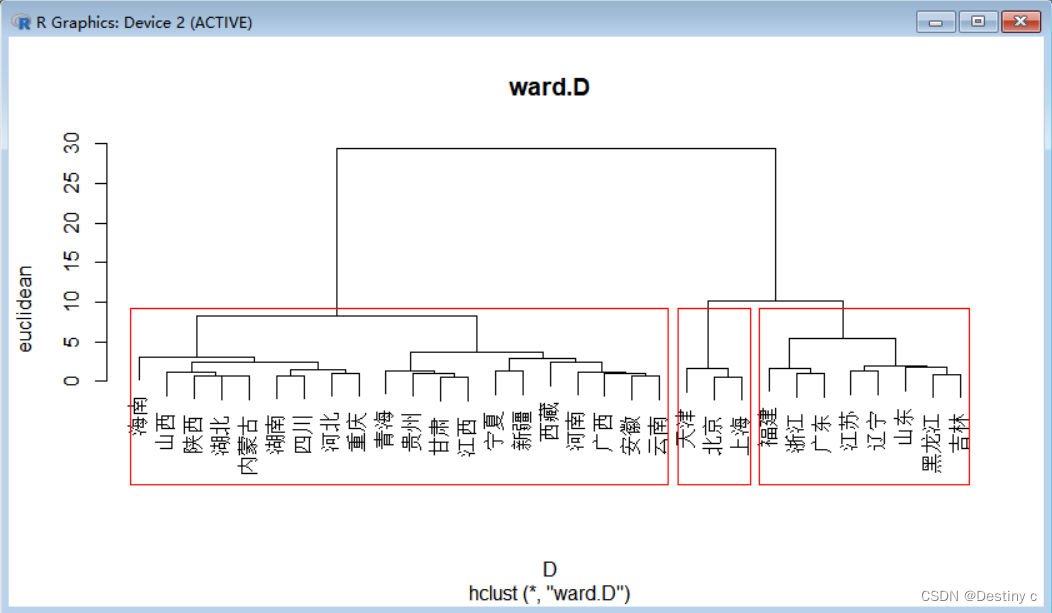
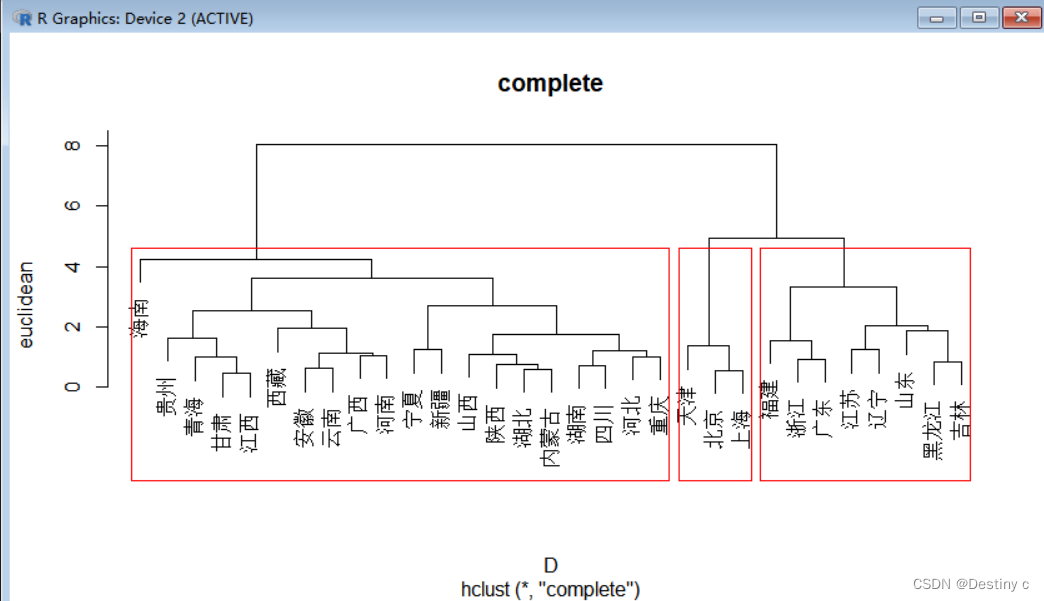
分为三类,ward法中最少一类中包含____个样本,最长距离最多____样本,两个方法比较合理的是_____
d为距离计算方法:euclidean(欧氏距离),maximum(切比雪夫距离),manhattan(绝对值距离),canberra(兰氏距离),minkoeski(明氏距离)。
m为系统聚类方法 single(最短距离法),complete(最长距离法),average(类平均法),median(中间距离法),centroid(重心法),ward.D(ward法)。proc为是否输出聚类过程。plot为是否输出聚类图。
#欧式+ward法
> qb5_eu_wd = H.clust(qb5,"euclidean","ward.D",plot=T);rect.hclust(qb5_eu_wd,k=3)
#欧式+最长
> qb5_eu_cop = H.clust(qb5,"euclidean","complete",plot=T);rect.hclust(qb5_eu_cop,k=3)
2. kmeans
> (km<-kmeans(Z,5)) #对数据Z做K均值聚类,分5类
> plot(km$cluster) #对分类作图展示
> identify(km$cluster,labels=names(km$cluster),n=length(km$cluster),tolerance =0.25) #点击显示点的标签
六. 因子分析
采用主成分法对样本进行因子分析,公因子个数是4.
极大似然+旋转FA0=factanal(X,3,rotation=“varimax”)
极大似然+不旋FA0=factanal(X,3,rotation=“none”)
主成分+旋转FA1=factpc(X,3,rotation=“varimax”)
主成分不旋FA1=factpc(X,3)
1. 建立因子分析模型
采用方差最大化方法进行因子旋转,写出因子模型,写出前两个因子的方差贡献率,共同度最大的变量是
因子模型
> q6_zcf_xz = factpc(q6,4,rotation="varimax");q6_zcf_xz
Factor Analysis for Princomp in Varimax:
$Vars
Vars Vars.Prop Vars.Cum
Factor1 3.040 33.78 33.78
Factor2 1.932 21.46 55.24
Factor3 1.277 14.19 69.43
Factor4 1.079 11.98 81.42
$loadings#旋转后载荷矩阵
Factor1 Factor2 Factor3 Factor4
x1 0.049430 0.92535 0.076684 -0.103147
x2 0.249707 0.85154 -0.253035 -0.184190
x3 0.715246 0.41793 -0.057583 -0.144488
x4 -0.002995 -0.23212 0.005695 0.935301
x5 0.796492 0.09432 0.461953 0.105807
x6 0.063679 -0.11709 0.927519 -0.008258
x7 0.865334 0.10109 -0.098568 0.173427
x8 0.702326 0.28098 0.346513 0.051310
x9 0.763471 -0.09983 -0.027029 -0.307292
$scores#旋转后因子得分
Factor1 Factor2 Factor3 Factor4
张三 -0.913224 -0.09734 -0.006191 0.796441
刘明 0.577338 0.61277 0.186427 -0.214724
安宁 -0.321587 0.36309 0.422861 -1.224428
王浩 1.545656 0.14090 0.570897 -0.007294
田一杰 -0.371850 -0.26984 0.784478 -0.277053
杨桐 0.395438 1.07307 0.858988 0.527898
邹文杰 0.008653 0.19757 -1.583081 2.035428
王哲 0.751191 1.37037 0.980507 0.557261
罗丽 0.381450 -0.09022 1.224255 2.128442
郑涛 1.272876 0.85438 0.743912 -1.510462
张磊 -0.456377 0.95169 -0.053060 -1.325094
王晓 1.193712 -0.82341 0.030743 -0.216747
兰陵 -1.430795 0.46809 -0.052472 0.657802
孙鑫 -2.100622 -0.13697 0.611105 -0.960262
陈翔 -0.053436 -0.94006 -0.882093 -0.812503
常广 0.627591 -3.40662 0.831341 -0.140313
石飞跃 -1.112887 -0.03864 -0.968510 -0.725039
唐伯虎 -0.470003 -0.42217 -0.852541 0.272069
马一杰 1.390098 0.29068 -2.841374 -0.357864
徐盛 -0.913224 -0.09734 -0.006191 0.796441
$Rank#得分排名
F Ri
张三 -0.2883 13.5
刘明 0.4019 6.0
安宁 -0.1442 12.0
王浩 0.7768 2.0
田一杰 -0.1294 10.0
杨桐 0.6744 3.0
邹文杰 0.0793 9.0
王哲 0.9258 1.0
罗丽 0.6612 4.0
郑涛 0.6606 5.0
张磊 -0.1427 11.0
王晓 0.2516 7.0
兰陵 -0.3825 15.0
孙鑫 -0.9424 20.0
陈翔 -0.5434 18.0
常广 -0.5134 17.0
石飞跃 -0.7474 19.0
唐伯虎 -0.4149 16.0
马一杰 0.1053 8.0
徐盛 -0.2883 13.5
$common#共同度
x1 x2 x3 x4 x5 x6 x7 x8 x9
0.8752 0.8854 0.7104 0.9287 0.8679 0.8781 0.7988 0.6949 0.6880
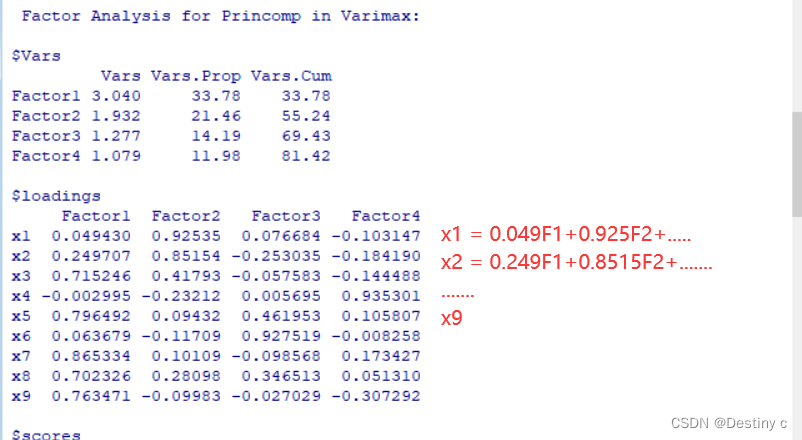
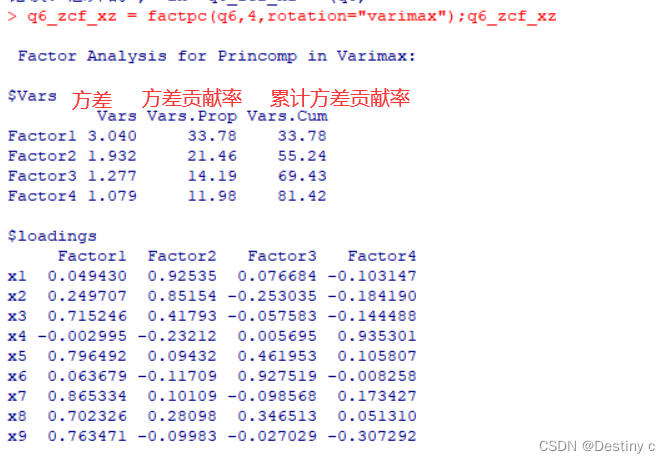

2.因子F可视为哪些变量的公共因子,在哪个变量载荷最大
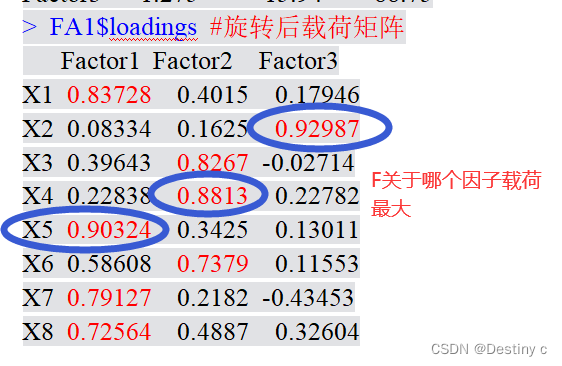
3. 计算综合因子得分进行综合排名
> factanal.rank(q6_zcf_xz,plot=T)
综合得分公式:
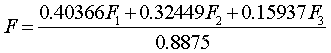
其中,0.40366为F1的方差贡献率,0.32449为F2的方差贡献率,0.15937为F3的方差贡献率,0.8875为前三个因子的方差累积贡献率
4.因子分析
由旋转后的因子载荷矩阵可以看到:
公共因子F1在X1(人均食品支出)、X5(人均交通和通讯支出)、x7(人均居住支出)、x8(人均杂项商品及服务支出)上的载荷值都很大,可视为反映日常必须消费的公共因子。
公共因子F2在X3(人均家庭设备用品及服务支出)、x4(人均医疗保健支出)、x6(人均娱乐教育文化支出)上的载荷值很大,可视为反映相对高档消费的公共因子。
公共因子F3仅在x2(人均衣着支出)上有很大的载荷,可视为衣着因子。
这样就可以对各省、市、自治区的消费情况做评价。
七. 给出两两之间距离,用最短距离做系统聚类,画出谱系图。
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1 | 0 | 4 | 6 | 1 | 6 |
| 2 | 4 | 0 | 9 | 7 | 3 |
| 3 | 6 | 9 | 0 | 10 | 5 |
| 4 | 1 | 7 | 10 | 0 | 8 |
| 5 | 6 | 3 | 5 | 8 | 0 |
(x=matrix(c(0,4,6,1,6,4,0,9,7,3,6,9,0,10,5,1,7,10,0,8,6,3,5,8,0),5)) #生成5维矩阵
Z=scale(x)
D=dist(Z) #计算距离矩阵
hc=hclust(D,"single")
cbind(hc$merge,hc$height)
plot(hc) #画聚类图
rect.hclust(hc,k=2) #对聚类结果画框,k=2表示分2类

八. 根据所给数据集自由发挥
- 聚类分析(宏观分析,区域划分)
2003年里,广东省各地区电信业发展除了差异性外,还有集中发展的趋势。我们可以利用聚类分析将广东省的各市分成几类。各类代表了不同的发展水平,同时每类所包含的城市具有类似的发展水平。经过分析,我们也得到一点启示:各市在发展电信业时,不能只片面强调通信总量,同时也要注意人均量的发展,注意在全地区范围内的普及。只有人均水平提升了,才真正具有意义,也才能说该城市的电信水平真正提高了。一个城市的电信业只有全面发展了,才能经受住WTO的冲击,才能保持良好的竞争力。同时,就广东省而言,尽管它的电信业总量2003年排到了全国之首,但是各地区间存在严重的差异。珠三角地区发展迅猛,电信业务总量大,市场份额高,而经济欠发达地区特别是山区和农村则发展较慢,总量小、份额低。对此,广东省政府应加快经济欠发达地区的电信建设,大力扩展山区电信市场,并采取扶持措施加强农村市场建设,促进广东省各地区电信业的协调发展。作为落后城市,也应该积极采取措施加速自身发展,提高竞争力,从而避免成为“拖油瓶”。
- 主成分分析(微观分析,综合排名)
由于指标多,不便于综合分析,先采用主成分分析法提取主要成分,然后进行相应的分析。用R软件运行后我们发现可以提取两个主要成分,这两个成分占全部的96.14% ,可以说是基本代表了全部指标的信息量。
经过主成分分析,我们发现可以提取两个主成分Comp. 1、Comp.2。
第一个主成分Comp.1主要由X(电信业务总量)、X(国际互联网用户)、X,(互联网用户使用时长)、X。(长途电话通话量)、X,(长途电话通话时长)决定,这5个指标是总量因素,说明一个城市的电信业规模和电信通信业务发展水平。
第二个主成分Comp.2主要由X(每百人拥有固定电话数)、X,(每百人拥有移动电话数)决定。这两个指标是平均量成分,反映了电信行业中的电话人均普及情况。
由于我们在主成分分析后选取的两个主成分PC,、PC,就代表了96.14%的信息,可以说基本表征了我们全部的指标。所以我们用提取的主成分进行各城市的综合分析。
我们发现七个经济指标可以用两个综合指标代替,而综合指标的信息没有损失多少。在此基础上,我们不仅可以算出各城市的成分得分,而且可以利用线性加权方法,以各主成分的贡献率为权数,即按公式(0.738 xPC,+0.223 xPC,) / (0.738+0.223)计算各城市电信业发展水平的综合得分并据此排名。其主成分得分和排名见下图。
- 分析
通过对各城市进行排名后,我们发现,排名比较靠前的地区有深圳、广州、东莞、惠州和佛山。比较靠后的地区有汕尾、湛江、茂名和阳江。
我们也可以从主成分得分图上清楚地看到,第一主成分Comp.1和第二主成分Comp. 2得分最高的均为深圳,而广东省各城市排名中稍有争议的是惠州、中山和茂名。我们回过去看前面的数据,发现尽管惠州市的第一主成分Comp.1水平,即通信发展水平低于中山市,但其第二主成分Comp.2因子,即电话普及水平是远远超过中山的,而第二主成分Comp.2所占的比重为全部变量的22.34%,这也是不容忽视的。而茂名市由于其互联网用户不够多而且人均电话普及量不够,其他两个主成分的得分都不高,而第二主成分尤其偏低,从而它的排名比较靠后。从主成分得分图上看到:
(1 )广州在第二象限,远离Comp. 1和 Comp.2轴。这说明广州的第一主成分Comp. 1得分比较高,仅次于深圳;但是第二主成分Comp.2得分较低。我们知道Comp. 1代表了电信业通信业务发展的总量水平,而Comp.2代表了电信业发展的平均量水平。结合Comp. 1 ,Comp.2的意义来分析,广州是广东的省会城市,经济、文化等各项总量发展水平都不错,电信业发展总量也不错,故而Comp.1得分比较高,仅次于深圳,但是由于广州也是一个大型开放性城市,人口也很多,人口增长的速度明显比电信业发展快,这样计算下来的人均量就不如深圳高了。(2)梅州和惠州的情况和广州有点相反,它们在电信总量方面不如广州,但由于其人口比较少,人均量高,从而尽管Comp.l得分比较低,但Comp.2有着很高的得分。这表现在主成分图上就是离Comp.2轴很近,离Comp.1轴很远。由于其特殊性,我们将它们单独分成一类。
(3)从图上我们看到深圳的位置在图中离原点比较远,同时它到Comp.1轴和到Comp.2轴的距离都比较远。这说明深圳Comp.1和 Comp.2的得分都比较高。深圳作为一个经济特区,自改革开放以来,各方面发展速度很快,是个发达城市,其移动电话用户比较多。近年来移动电话的发展在电信业发展中异军突起,也占据了重要地位。而与广州有所不同,深圳的人口总数不算太多,从而其电话普及率可以达到很高。正因为如此,它的Comp.2得分较高。同时由于其发达性,电话和互联网用户很多,电信业发展总量也不错,从而Comp.1有着很高的得分,在广东所有城市中排名第一。很高的Comp.l得分和比较高的Comp.2得分就决定了深圳在排名时可以领先于广州而居于第一位。
- 因子分析
结果分析:①从因子得分表可以看出,在盈利能力因子F上得分最高的四个公司依次是海螺水泥、福建水泥、冀东水泥和祁连山,这四家公司的得分远高于其他公司,这说明就盈利能力而言,这四家公司的盈利水平远高于其他公司,而盈利能力相对较弱的公司是尖峰集团、西水股份和牡丹江。②福建水泥、海螺水泥、四川金顶三家公司在因子F,上的得分较高,说明在水泥行业中,这三家公司的偿债能力是较好的,而狮头股份和大同水泥这两家公司在因子F,上的得分较低,则表明这两家的偿债能力相对较差,应着力提高。③在发展能力因子F,上,西水股份、海螺水泥的得分远远高于其他公司,反映在现实情况中,这两只股票从2008年到现在是稳中有升的,这也要得益于它们良好的发展能力。同时也说明在水泥行业上市公司中,就发展能力而言,好的公司还是少数,很多公司不注重长远稳健的发展,而只注重短期利润。这一点需要引起有关企业的注意。四川金顶在因子F,上的得分最低,说明它的发展能力最差,并且它的前两个因子得分也不高,在综合排名上也是靠后的,因此这家公司应从企业内部着手,进行整改,要从整体上提高公司的各项经营能力,达到提升公司经营业绩的目的。