《A Late Fusion CNN for Digital Matting》论文阅读
论文地址:A Late Fusion CNN for Digital Matting
1.摘要
本文研究了深度卷积神经网络的结构,通过以单个RGB图像作为输入来预测前景alpha遮罩。 我们的网络是具有两个解码器分支的全卷积网络,分别用于前景和背景分类。 然后,使用融合分支对两个分类结果进行融合,这将产生alpha值作为软分割结果。 与网络中的单个解码器分支相比,此设计提供了更大的自由度,以便在训练过程中获得更好的alpha值。 该网络无需用户交互即可隐式生成trimap,这对于没有数字遮罩专业知识的新手来说很容易使用。 实验结果表明,我们的网络可以为各种类型的对象实现高质量的alpha遮罩,并且在人类图像遮罩任务上优于基于CNN的最新图像遮罩方法。
2.相关工作
在这个部分,我们简要回顾了一下三种主要的数字抠图方法:基于采样的方法、基于类的方法以及基于深度学习的方法。
基于采样的方法使用颜色信息来推断图片中过渡区域每个像素的alpha值。这类方法的关键就是要(1)收集采样的像素,(2)建立前景与背景的颜色模型。这类方法利用自然图像的统计信息来解决一些抠图问题,并且当trimap标记的很好时,该方法能够取得较好的结果。
基于类的方法,已经被证明了效果比基于采样的方法要好。而要取得更好的alpha值结果,就要定义一个恰当的亲和力分数。全局优化策略,如频谱技术,是二进制优化技术的连续松弛,不能保证获取的最优解。
基于深度学习的抠图方法,直接从大量标注的数据中学习了一种输入图像到alpha的映射。
随后作者介绍了一些其他作者的贡献,并指出他们的优缺点。
3.本文方法
在这个部分,将介绍我们提出的方法细节。3.1是方法总览,3.2和3.3详细描述了模型结构和分割网络与融合网络的训练损失,3.4给出了网络的训练细节。
3.1方法总览
我们提出了一个新颖的端到端的神经网络,输入为包含前景的图片,输出为前景的alpha遮罩。如图2所示,我们的方法核心就是利用神经网络来预测三个图:前景概率图、背景概率图、混合权重图。输出的alpha遮罩就是根据混合权重图将前景概率图与背景概率图进行融合得到。网络有三个需要连续训练的部分:分割网络的预训练步骤,融合网络的预训练步骤以及最终的端到端联合训练步骤,其训练损失被加在输出alpha遮罩上。
 我们将尝试通过下面的统合方程来预测alpha
我们将尝试通过下面的统合方程来预测alpha
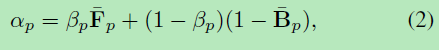
这里Fp和Bp分别代表某像素预测的前景与背景概率,βp为融合网络预测的混合权重。在我们的实现中,融合网络将输入图像和特征作为预测前景和背景分类分支的逻辑回归之前的输入。
从优化角度来看, 当满足一下式子时,αp关于βp的导数将消失;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LDfx6TmH-1576548078847)(https://img-bl首先,如果前景/背景概率图的预测准确(意味着满足等式3),则融合网络将专注于学习从前景到背景的过渡区域,这是解决消光问题的瓶颈。 其次,我们可以仔细设计损失函数,以鼓励过渡区域内的Fp + Bp!=1(请参见第3.2节),这可以提供有用的梯度来训练融合网络。
3.2分割网络
我们继续描述分割网络的体系结构及其训练损失。特别地,训练损失有利于实心前景和背景区域的概率为0或1。它还尝试预测过渡区域中真实Alpha值的上限和下限。
网络结构:分割网络由一个编码器和两个解码器组成。编码器从输入图像中提取语义特征。这两个解码器共享相同的编码结果,并分别预测前景和背景概率图。具体来说,我们使用没有全连接的层头的DenseNet-201 作为编码器。每个分支由与五个编码器块相对应的五个解码器块组成,并且解码器块遵循[22]中的特征金字塔网络结构的设计。为了增强像素级分割的结果,我们在[28]中使用了跳过连接,将编码器块中的多尺度特征(在平均下采样之前)与通过反卷积层上采样的特征连接起来。
训练损失:训练损失包含了L1损失、L2损失、交叉熵损失。特别的,我们通过根据alpha遮罩为不同的像素设置不同的权重来控制网络训练过程的行为。
我们首先测量预测概率值和基本真值之间的差:
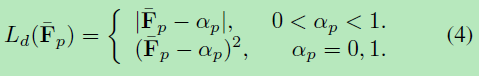
差异选择为过渡区域内的L1,以便在那里恢复alpha遮罩的细节,而其余区域使用L2损失来惩罚可能的分割误差。 我们发现此设置可以很好地在软细分和硬细分之间取得平衡。
我们还将L1损失引入预测的alpha遮罩的梯度上,因为在分类后去除过度模糊的alpha遮罩是有益的:
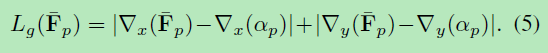
前景分类分支在像素p处的交叉熵(CE)损失由下式给出:
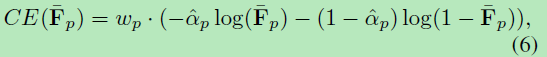
最红的损失函数如下所示:
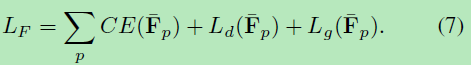
注意,交叉熵和过渡区域内部的L1损失的组合试图提供比真实值更大的概率,因为交叉熵损失会将概率拖至1。因此,可以将真实的alpha值放在方括号中。 由于等式中的1-B p,由两个分支预测的两个概率形成的区间。 2应该小于我们设置中的p。 这种设计使我们能够在应用融合网络后对精确的alpha值进行回归
此外,以不同的损失来训练前景和背景分割分支有助于学习输入图像的不同特征。 这些特征有益于整体学习的结果。 如图3和图4所示,分段损失的这种设计确实导致了有意义的隐式三映射的生成。 此外,介于0和1之间的alpha值大多由两个预测的概率括起来。


3.3融合网络
融合网络的目标是在像素处输出βp以融合前景和背景分类结果。
网络结构:它是一个具有五层卷积层和一层sigmoid的全卷积网络,用于计算混合权重βp(见图2)。 网络的输入包括:(1)来自前景和背景解码器最后一块的特征图; (2)来自与输入RGB图像卷积的特征。 我们根据实验将卷积核的大小设置为3×3,发现具有这种核大小的融合网络可以更好地生成alpha遮罩的细节。
训练损失:假设前景和背景解码器已经为实体像素提供了合理的分割结果,我们将训练损失设计为向过渡区域中的像素倾斜。 融合网络的损失函数可以根据公式(2)0直接推导:
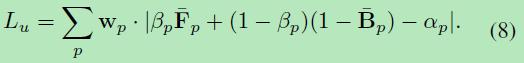
3.4训练的细节
我们使用预先经过ImageNet-1K训练的DenseNet-201网络作为我们的编码器主干。 首先对分割网络进行15次迭代的预训练。 在融合网络的预训练步骤中,我们冻结了分割阶段,并单独训练了4次迭代的融合阶段。 最后,我们对端到端的联合网络进行7次迭代训练,这将融合结果的梯度反向传播至分割和融合网络,从而进一步减少了训练损失。 在联合训练步骤中冻结所有批归一化层,以节省内存空间。 循环学习率策略用于在整个训练过程中加快收敛速度。 所有步骤的基本学习率为5.0×10−4。 预训练阶段的最大学习速率为1.5×10-3。 在联合训练步骤中,将最大学习速率设置为较小的1.0×10-3。
在进行端到端联合训练以微调整个网络时,我们还会使用特殊的损失。 损失是基于融合网络的损失,同时增加了分割网络的损失以避免过度拟合。 总体连接训练损失描述如下:
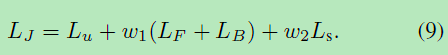
实验结果
我们分别在(1)人物肖像图(2)自然图像上进行测试
在人物肖像图的实验结果数据以及与其他算法的对比如下:


在自然图像上的测试结果以及其他算法对比如下:


以及一些来自互联网上的分割结果:

